
什么是生成器
之前我们学习过迭代器,它的好处之一就是可以节省能存,在某些情况下,我们需要自己定义一个方法去实现迭代器功能,这个方法就是生成器。
在Python中生成器又分成两类:
- 生成器函数
- 生成器表达式
生成器函数
生成器Generator:
本质:迭代器(所以自带了iter方法和next方法,不需要我们去实现)
特点:惰性运算,开发者自定义
生成器函数:
一个包含yield关键字的函数就是一个生成器函数。yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
1 | # 只要含有yield关键字的函数都是生成器函数 |
运行过程总结:
- 由于函数中有yield,所以现在内存中会有一个生成器函数 generator
- g = generator() 发生了函数调用,生成器函数的特点:函数中的代码不执行
- g 得到了一个生成器
- 生成器里面即有iter方法也有next方法,说明它其实是一个迭代器
- 生成器就可以使用next方法取值,这时程序才第一次触发了生成器里面的代码
- yield 不会结束函数,return会直接结束
生成器函数的使用
生成器的最大好处就是不会在内存中一次性的生成所有数据1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23def factoy():
for i in range(100):
yield '生成%s次'%i
g = factoy()
# __next__() ,一次一次的提取
print(g.__next__())
print(g.__next__())
print(g.__next__())
# for循环遍历提取
for i in g:
print(i)
# 取50次
g = factoy()
count = 0
for i in g:
count += 1
print(i)
if count > 50:
break
print('*****',g.__next__()) # ***** 生成51次 可以继续从生成器中取值
列表为什么不能继续取值
1 | # 列表是可迭代的,并不是一个迭代器,在两次for循环的时候会产生两个迭代器 |
监听文件的输入
1 | def tail(filename): |
爬虫时的使用
1 | def parse_one_page(html): |
生成器函数的进阶
数据类型的强制转换 — 列表(生成器)
1 | def generator(): |
1 | def generator(): |
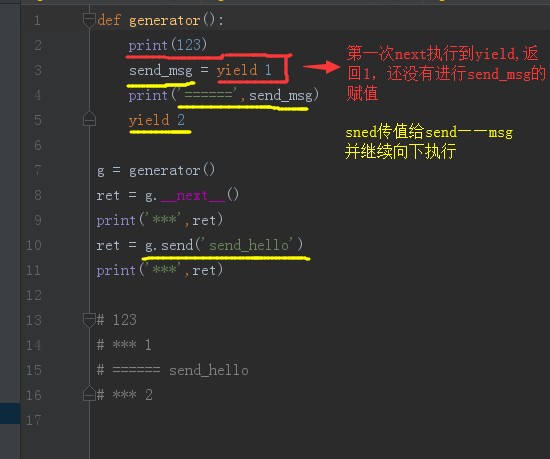
生成器函数 — send
1 | def generator(): |
send实例 — 计算移动平均值
1 | # 接收一次值计算平均值 |
那么如何多次计算呢,需要加上循环1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
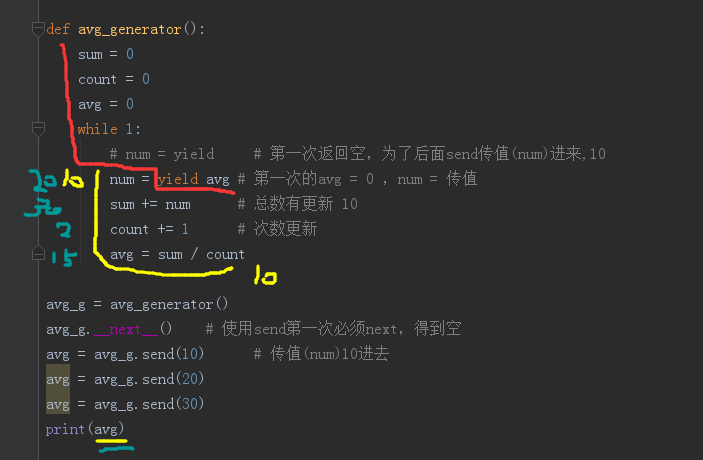
27# 移动平均值
# num: 10 20 30
# avg: 10 15 20
# 公式: avg = num / count
def avg_generator():
sum = 0
count = 0
avg = 0
while 1:
# num = yield # 第一次返回空,为了后面send传值(num)进来,10
num = yield avg # 第一次的avg = 0 ,num = 传值
sum += num # 总数有更新 10
count += 1 # 次数更新
avg = sum / count
avg_g = avg_generator()
avg_g.__next__() # 使用send第一次必须next,得到空
avg = avg_g.send(10) # 传值(num)10进去
avg = avg_g.send(20)
avg = avg_g.send(30)
print(avg)
# 每次计算方法:
# 如果我加上while循环,现在我有两个yield,第一次结束到yield avg,第二次执行什么?
# 如果执行next num = yield 相当于 num = 0
# 下面再用一次send 传值20 再返回打印
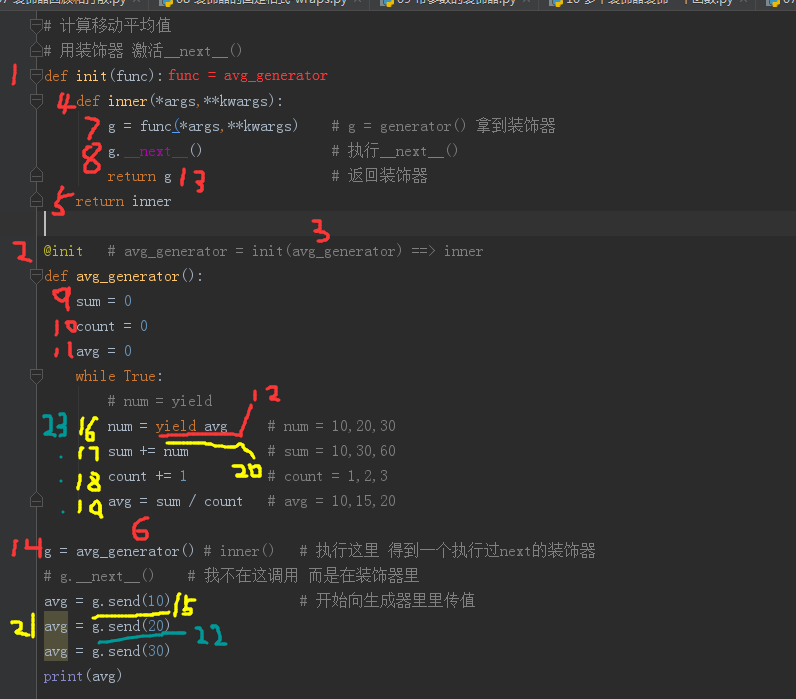
计算移动平均值(2)_预激协程的装饰器
1 | # 计算移动平均值 |
yield from
yield from : 从一个容器类型里取值,不需要一个个返回,而是集体返回接收1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# python 3
# 将结果按个返回
def generator():
a = 'abcde'
b = '12345'
# 单个字符串返回
for i in a:
yield i
for i in b:
yield i
g = generator()
# print(g.__next__())
for i in g:
print(i)
1 | # yield from 将结果按个返回 |
1 | # 将两个类型的数据list转化成同一个 |
生成器表达式
列表推导式
我们先写一个获取鸡蛋的程序1
2
3
4egg_list = []
for i in range(10):
egg_list.append('鸡蛋%s'%i)
print(egg_list)
在这里循环获取得到一个鸡蛋筐(列表),里面存着10个鸡蛋,列表推导式的写法如下1
2
3
4
5egg_list = ['鸡蛋%s' %i for i in range(10)]
print(egg_list)
# 1. for i in range(10) 循环
# 2. 将想要的 放在for前面
# 3. 用列表括起来
列表推导式可以做一些简单的循环工作,那么这个时候我们就想,列表生成后可是存在内存里的,那如果是大数据怎么办,很占用内存,占用内存我们就想到了 生成器
生成器推导式
生成器表达式 与 列表表达式 的不同
- 括号不一样
- 返回的值不一样
- 列表推导式得到的还是一个列表,一次性得到所有的值,占用内存
- 生成器表达式几乎不占用内存,但是不能直接应用,需要遍历循环取值,程序应该更关心内存
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21# 生成器表达式
g = (i for i in range(10))
print(g) # <generator object <genexpr> at 0x0000000001EB92B0> 生成器
for i in g:
print(i)
# 获取鸡蛋例子
egg_g = ('鸡蛋%s'%i for i in range(10)) # 生成器表达式
for i in egg_g: # 相当于老母鸡,然后下蛋
print(i)
# 每个数字都取平方
# g里面的代码一句话没执行,直到for循环取值__next__,for循环每走一次,上面的range10的循环才走一次
g = (i*i for i in range(10))
for i in g:
print(i)
#列表解析
sum([i for i in range(100000000)])#内存占用大,机器容易卡死
#生成器表达式
sum(i for i in range(100000000))#几乎不占内存
迭代器与生成器总结
可迭代对象:
- 拥有
__iter__方法 - 特点:惰性运算
例如: range(), str, list, tuple, dict, set
迭代器Iterator:
- 拥有
__iter__方法和__next__方法
例如: iter(range()), iter(str), iter(list), iter(tuple), iter(dict), iter(set), reversed(list_o), map(func,list_o), filter(func, list_o), file_o
生成器Generator:
本质:迭代器,所以拥有__iter__方法和__next__方法
特点:惰性运算, 开发者自定义
使用生成器的优点:
- 延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据量处理,将会非常有用。
- 提高代码可读性