
内置函数
什么是内置函数? 就是python给你提供的. 拿来直接用的函数,比如print., input等等.
截止 到python版本3.6.2 python一共提供了68个内置函数. 有一些我们已经用过了.有一些还没有用过. 还有一些需要学完了面向对象才能继续学习的.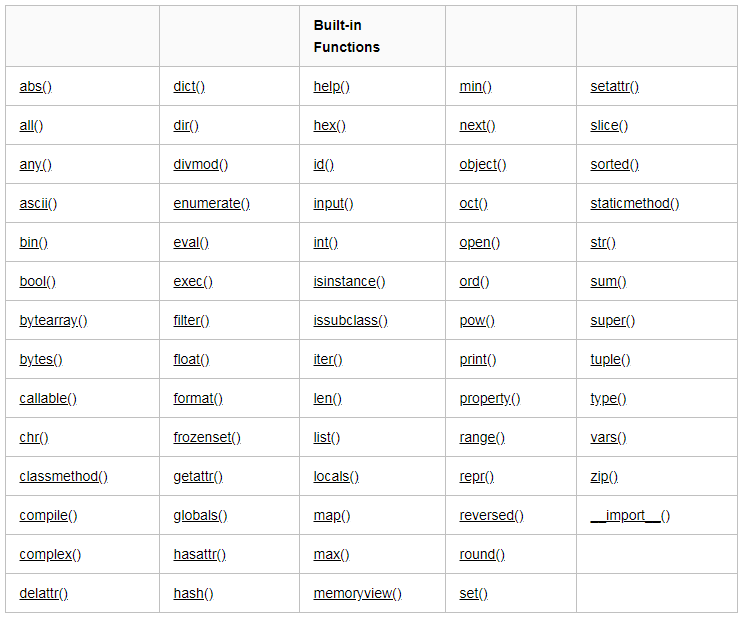
作用域相关(2)

locals() 和 globals()
基于字典的形式获取局部变量和全局变量1
2print(locals()) # 返回本地作用域中的所有名字
print(globals()) # 返回全局作用域中的所有名字
迭代器/生成器相关(3)
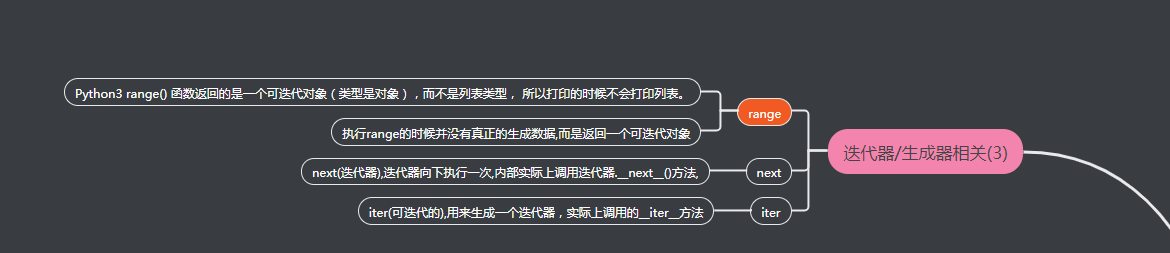
range(),next() 和 iter()
Python3 range() 函数返回的是一个可迭代对象(类型是对象),而不是列表类型, 所以打印的时候不会打印列表。1
2
3
4
5
6
7# range
# range(10)
# range(1,11)
# range(1,11,2) # 步长取值
print('__iter__' in dir(range)) # True 可迭代的
print('__next__' in dir(range)) # False 不是迭代器
print('__next__' in dir(iter(range(1,11,2)))) # True
next(迭代器),迭代器向下执行一次,内部实际上调用迭代器.__next__()方法
iter(可迭代的),用来生成一个迭代器1
2
3
4
5
6
7
8
9
10# next 和 iter
l = [1,2,3,4,5]
it = iter(l) # 转成迭代器
print(type(it)) # <class 'list_iterator'>
while 1:
try:
print(next(it))
except StopIteration:
# 遇到StopIteration就退出循环
break
其他(12)
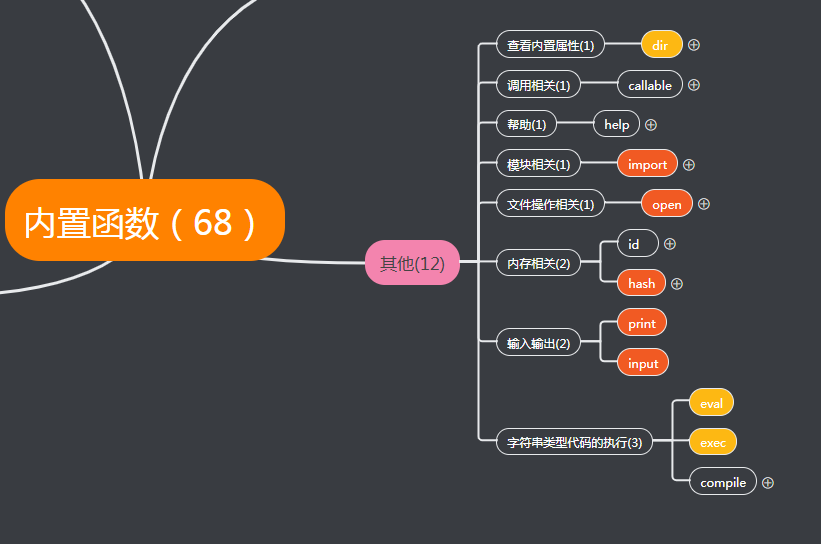
查看内置属性(1)
dir()
默认查看全局空间内的属性,也接受一个参数,查看这个参数内的方法或变量1
2print(dir()) # 获得当前模块的属性列表
print(dir([])) # 查看列表的方法
调用相关(1)
callable()
callable 用来检查一个对象是否可被调用
对于函数、方法、lambda 函式、 类以及实现了 __call__ 方法的类实例, 它都返回 True。1
2
3a = 1
print(callable(a)) # False
print(callable(print)) # True
帮助(1)
help()
用于查看函数或模块用途的详细说明
在控制台执行help()进入帮助模式。可以随意输入变量或者变量的类型。输入q退出
或者直接执行help(o),o是参数,查看和变量o有关的操作。。。1
help(str)
模块相关(1)
import()
导入模块1
import time
文件操作相关(1)
open()
打开一个文件,返回一个文件操作符(文件句柄)
操作文件的模式有r,w,a,r+,w+,a+ 共6种,每一种方式都可以用二进制的形式操作(rb,wb,ab,rb+,wb+,ab+)
可以用encoding指定编码.1
2
3f = open('01 内置函数.py')
print(f.writable()) # 判断当前文件是否可写
print(f.readable()) # 判断当前文件是否可读
内存相关(2)
id()
id()函数用于获取对象的内存地址。1
2
3# id(o) o是参数,返回一个变量的内存地址
a = 100
print(id(a)) # 1497027344
hash()
用于获取取一个对象(字符串或者数值等)的哈希值。
hash() 函数可以应用于数字、字符串和对象,不能直接应用于 list、set、dictionary。
获取到对象的哈希值(int, str, bool, tuple)
- hash函数会根据一个内部的算法对当前可hash变量进行处理,返回一个int数字。
- 每一次执行程序,内容相同的变量hash值在这一次执行过程中不会发生改变。
1
2
3
4print(hash(12345)) # 12345
print(hash('abcde')) # -5832084034581495945
print(hash(('a','b'))) # -3079515087831999849
# print(hash(['a',1,'b',2])) # 报错:TypeError: unhashable type: 'list' 不可哈希
输入输出(2)
input()
获取用户输入1
2content = input('>>>')
print(type(content),content) # input得到的是字符串类型
print()
打印输出1
2
3
4
5# 关键字传参 end默认为'\n',指定不是回车即可
# 这就是我们为什么使用print的时候会出现换行,end的值修改成了空字符串
print('我们的祖国是花园\n',end='')
print('我们的祖国是花园\n',end='')
print('我们的祖国是花园\n')
1 | # sep 打印多个值之间的分隔符,默认为空格 |
1 | # file: 默认是输出到屏幕,如果设置为文件句柄,输出到文件 |
字符串类型代码的执行(3)
eval()
eval() 将字符串类型的代码执行并返回结果1
print(eval('1+2+3+4')) # 10 有返回值 ——有结果的简单计算
exec()
exec() 将自字符串类型的代码执行1
2
3
4
5print(exec('1+2+3+4')) # None 没有返回值 ——简单的流程控制
# exec 和eval都可以执行 字符串类型的代码
# 区别是eval有返回值,exec没有
# eval只能用在明确知道要执行的代码
compile()
将字符串类型的代码编译。代码对象能够通过exec语句来执行或者eval()进行求值。1
2
3
4#流程语句使用exec
# code1 = 'for i in range(0,10): print (i)'
# compile1 = compile(code1,'','exec')
# exec (compile1)
1 | #简单求值表达式用eval |
1 | #交互语句用single |
基础数据类型相关(38)
和数字相关(14)
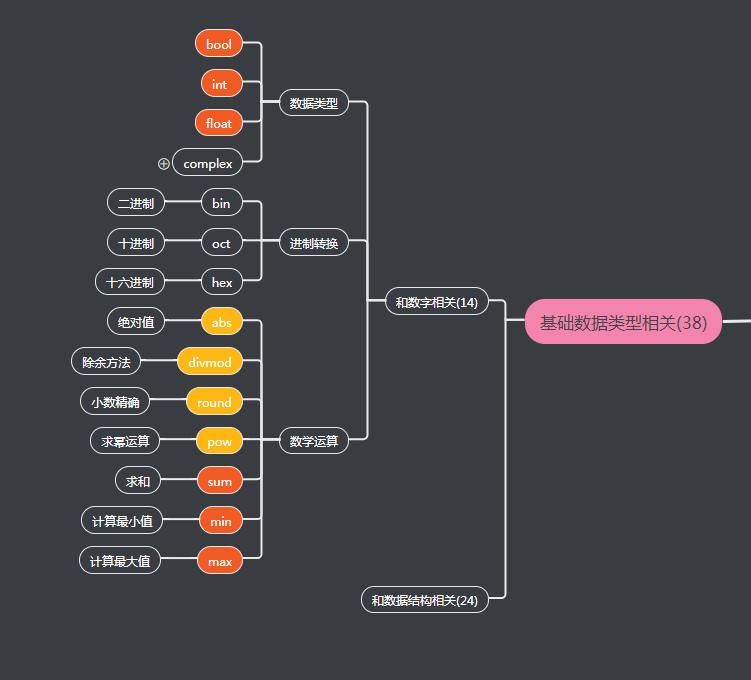
bool()
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
int –> bool 非0为True,0为False1
2
3
4n1 = 10
print(bool(n1)) # True
n2 = 0
print(bool(n2)) # False
int()
int() 函数用于将一个字符串或数字转换为整型。
int() 将给定的数据转换成int值. 如果不给值, 返回01
2
3
4
5
6
7
8# int
# str 转换成 int 只能转换数字字符串
str1 = '10'
print(int(str1)) # 10
# int 转换成 str 数字可以转换成任何字符串
num = 5
print(str(num))
float()
float() 将给定的数据转换成float值. 也就是浮点数
- 浮点数包括:
- 有限循环小数
- 无线循环小数
- 小数包括:
- 有限循环小数
- 无线循环小数
- 无线不循环小数
1
2
3
4
5# 浮点数
# 354.123 == 3.54123 * 10**2 == 35.4123 * 10 在这个过程中点是浮动的 所以才叫浮点数
f = 1.78789787079889 # 当小数特别长的时候 就有可能不准了 二进制转小数会有问题就会不准
print(float(1)) # 1.0
print(float('123') ) # 转换字符串 123.0
complex()
complex() 创建一个复数. 第一个参数为实部, 第二个参数为虚部. 或者第一个参数直接 用字符串来描述复数
- 实数:
- 有理数 : 整数 有限循环小数 无线循环小数
- 无理数 : 无线不循环小数 π
- 虚数: 虚无缥缈的数
1
2
3# python里面的虚数 = 12j (j是单位)
# 5 + 12j === 复合的数 == 复数 (复数之间是无法比较大小的)
print(complex(1, 2)) # (1+2j)
bin()
1 | print(bin(10)) # 十进制转二进制 # 0b1010 |
oct()
1 | print(oct(10)) # 十进制转十进制 # 0o12 |
hex()
1 | print(hex(10)) # 十进制转十六进制 # 0xa |
abs()
abs() 函数返回数字的绝对值。1
2
3# abs求绝对值 负的转正的 正的还是正的
print(abs(-5)) # 5
print(abs(10)) # 10
divmod()
1 | # divmod 接收两个参数 div 除法 mod 取余 |
round()
round() 方法返回浮点数x的四舍五入值。1
print(round(3.14159,2)) # 3.14 2代表保留两位 支持四舍五入
pow()
1 | # pow 求幂运算 |
sum()
sum() 求和1
2
3
4
5
6
7
8# sum(iterable[, start])
# start 从几开始相加
# 列表计算总和后再加10
ret = sum([1,2,3],10)
print(ret) # 16
ret = sum((1,2,3))
print(ret) # 6
min()
min()计算最小值1
2
3
4
5# min(iterable,key,default)
# min(*args,key,default)
print(min([1,2,3])) # 1
print(min(1,2,3)) # 1
print(min((1,2,3,-4),key=abs)) # 1 key=abs 以绝对值的方法来计算
max()
min()计算最大值1
2
3
4
5# max(iterable,key,default)
# max(*args,key,default)
print(max([1,2,3])) # 3
print(max(1,2,3)) # 3
print(max((1,2,3,-4),key=abs)) # -4 key=abs 以绝对值的方法来计算
和数据结构相关(24)
list()
list() 用于将元组或字符串转换为列表。
注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。1
2
3
4str1="Hello World"
print(list(str1)) # ['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
tup1 = (1,2,3,'leo')
print(list(tup1)) # [1, 2, 3, 'leo']
tuple()
tuple()函数将列表转换为元组。。1
2l1= ['Google', 'Taobao', 'Runoob', 'Baidu']
print(tuple(l1)) # ('Google', 'Taobao', 'Runoob', 'Baidu')
reversed()
reversed() 返回一个反向的迭代器1
2
3
4
5
6
7
8
9
10# list.reverse() # 列表的反转方法
l2 = [1,2,3,4]
l2.reverse()
print(l2) # [4, 3, 2, 1] 原本的列表发生变化
l3 = [1,2,3,4,5]
iter_l = reversed(l3) # 保留原列表,返回一个反向的迭代器
print(iter_l) # <list_reverseiterator object at 0x000000000288CF98> 迭代器
for i in iter_l:
print(i)
slice()
slice() 函数实现切片对象,主要用在切片操作函数里的参数传递。1
2
3
4l = (1,2,23,213,5612,342,43)
sli = slice(1,5,2) # 切片规则
print(l[sli]) # (2, 213)
print(l[1:5:2]) # (2, 213)
str()
str() 将数据转化成字符串1
2
3
4l4 = [1,2,3]
print(str(l4)) # [1, 2, 3]
dict4 = {'name':'leo'}
print(str(dict4)) # {'name': 'leo'}
format()
format() 字符串格式化1
2
3
4
5
6
7print("{},{}".format('leo','lex')) # leo,lex 不设置指定位置,按默认顺序
print("{0},{1},{0}".format('leo','lex')) # leo,lex,leo 设置指定位置
print("名字:{name},年龄{age}".format(name='leo',age='30')) # 名字:leo,年龄30
# 通过字典设置参数
info = {'name':'leo',"age":29}
print("名字:{name},年龄{age}".format(**info)) # 名字:leo,年龄29
bytes()
bytes 将数据转换成bytes类型1
2
3
4
5# 拿到的事gbk编码,想要转换成utf-8编码
print(bytes('您好',encoding='GBK')) # b'\xc4\xfa\xba\xc3' unicode转成 GBK
print(bytes('您好',encoding='utf-8')) # b'\xe6\x82\xa8\xe5\xa5\xbd' unicode 转 utf-8
# gbk -> decode(解码) unicode -> encode(编码) utf-8
bytearray()
bytes类型的数组1
2
3b_array = bytearray('您好',encoding='utf-8')
print(b_array) # bytearray(b'\xe6\x82\xa8\xe5\xa5\xbd')
print(b_array[0]) # 230
memoryview()
memoryview() 函数返回给定参数的内存查看对象(Momory view)。
所谓内存查看对象,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。1
2
3
4ret = memoryview(bytes('你好',encoding='utf-8'))
print(len(ret))
print(bytes(ret[:3]).decode('utf-8'))
print(bytes(ret[3:]).decode('utf-8'))
ord()
字符按照unicode转数字1
2
3print(ord('A')) # 65
print(ord('a')) # 97
print(ord('1')) # 49
chr()
数字按照unicode转字符1
2print(chr(65)) # A
print(chr(49)) # 1
ascii()
只要是ascii码(字母、数字、符号、拉丁文)就显示,不是的话就打印\u类型1
2print(ascii('好')) # '\u597d'
print(ascii('l')) # l
repr()
repr格式化,原形毕露1
2
3
4
5name = 'egg'
print('你好%s' %name) # 你好egg %s ==> str
print('你好%r' %name) # 你好'egg' %r ==> repr
print(repr('1')) # '1'
print(repr(1)) # 1
dict()
创造字典1
2print(dict()) # {}
print(dict(a=1,b=2,c=3)) # {'a': 1, 'b': 2, 'c': 3}
set()
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等1
2
3
4
5
6x = set('runoob')
y = set('google')
print((set(['b', 'r', 'u', 'o', 'n']), set(['e', 'o', 'g', 'l'])) ) # 重复的被删除
print(x & y) # 交集 {'o'}
print(x | y ) # 并集 {'r', 'o', 'l', 'n', 'e', 'u', 'b', 'g'}
print(x - y ) # 差集 {'r', 'b', 'n', 'u'}
frozenset()
生成一个新的不可变集合,它可以作为字典的key1
2a = frozenset(range(10)) # 生成一个新的不可变集合
b = frozenset('runoob')
重要的内置参数
len()
返回对象的长度或者元素个数1
2
3
4test = 'abcde'
list1 = [1,2,3]
print(len(test)) # 5 字符串长度
print(len(list1)) # 3 列表元素个数
enumerate()
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,
同时列出数据和数据下标,一般用在 for 循环当中
enumerate(sequence, [start=0])
- sequence – 一个序列、迭代器或其他支持迭代对象。
- start – 下标起始位置。
1
2
3
4
5
6seasons = ['Spring', 'Summer', 'Fall', 'Winter']
list2 = list(enumerate(seasons))
print(list2) # [(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
list3 = list(enumerate(seasons, start=1)) # 小标从 1 开始
print(list3) # [(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]
all()
有任何一个空内容就是false1
2
3print(all(['a','',123])) # False
print(all(['a',123])) # True
print(all([0,123])) # False
any()
有一个正确的就是True1
print(any(['',True,0,[]])) # True
zip()
zip 拉链方法,如果少一个元素无法对应上,就不加入,以最小的数据类型为准1
2
3
4
5
6
7
8
9
10l1 = [1,2,3]
l2 = ['a','b','c','d']
t3 = ('*','**',[1,2])
d4 = {'k1':'1','k2':'2'}
print(zip(l1,l2)) # <zip object at 0x00000000028422C8>
for i in zip(l1,l2,t3,d4):
print(i)
# (1, 'a', '*', 'k1')
# (2, 'b', '**', 'k2')
filter()
filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
filter() 函数接收一个函数 f 和一个list,这个函数 f 的作用是对每个元素进行判断,返回 True或 False,filter()根据判断结果自动过滤掉不符合条件的元素,返回由符合条件元素组成的新list。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 过滤列表中的奇数
def is_odd(x):
return x % 2 == 1 # 奇数
# 第一个参数 函数方法
# 第二个参数 可迭代的
# 可迭代的里面的每个数据都会传入前面的函数
# 根据函数的结算结果筛选,为True的才会留下,最后返回一个迭代器
ret = filter(is_odd,[1,3,5,8,10])
print(ret) # <filter object at 0x00000000027A8780> 迭代器
# for i in ret:
# print(i) # 迭代器节省内存
print(list(ret)) # [1, 3, 5]
# 相当于列表推导式
l2 = [i for i in [1,3,5,8,10] if i % 2 == 1]
print(l2) # [1, 3, 5]
1 | # 名字有两个e的结果 |
1 | # 只保留字符串 |
1 | # 删除列表中的None和空字符串 |
1 | # 练习:请利用filter()过滤出1~100中平方根是整数的数,即结果应该是: |
map()
Python中的map函数应用于每一个可迭代的项,返回的是一个结果list。
如果有其他的可迭代参数传进来,map函数则会把每一个参数都以相应的处理函数进行迭代处理。map()函数接收两个参数,一个是函数,一个是序列,map将传入的函数依次作用到序列的每个元素,并把结果作为新的list返回。1
2
3
4
5
6
7
8
9
10
11# map 有点像 [i for i in [1,2,3]]
ret = map(abs,[-1,-2,3,-8])
for i in ret:
print(i) # 1,2,3,8
# filter 执行了filter之后的记过集合 <= 执行之前的个数
# filter只管筛选,不会改变原来的值
# map 执行前后元素个数不变,值变了
# 值可能发生改变
# 要注意配合匿名函数
sorted()
对List、Dict进行排序,Python提供了两个方法
对给定的List L进行排序,
方法1.用List的成员函数sort进行排序,在本地进行排序,不返回副本
方法2.用built-in函数sorted进行排序(从2.4开始),返回副本,原始输入不变1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# sort
l = [1,-4,6,5,-10]
l.sort(key=abs) # 在原列表的基础上进行排序
print(l) # [1, -4, 5, 6, -10]
# sorted
# 会生成一个新的数据,保留原来数据
# 排序的过程中负载的算法不支持产生一个迭代器
l = [1,-4,6,5,-10]
print(sorted(l)) # [-10, -4, 1, 5, 6] # 生成一个新列表,不改变原列表 占内存
print(l) # [1, -4, 6, 5, -10] # 源列表不变
# reversed() 倒叙 返回一个反向的迭代器
# sorted() 排序 返回list
print(sorted(l,key=abs)) # [1, -4, 5, 6, -10]
# 列表按照每一个元素的len排序
l = [[1,2],[3,4,5,6],(7,),'123']
print(sorted(l,key=len)) # [(7,), [1, 2], '123', [3, 4, 5, 6]]