
线程
进程内容回顾:
- 程序并不能单独运行,只有将程序装载到内存中,系统为它分配资源才能运行,而这种执行的程序就称之为进程。
- 程序和进程的区别就在于:程序是指令的集合,它是进程运行的静态描述文本;进程是程序的一次执行活动,属于动态概念。
- 在多道编程中,我们允许多个程序同时加载到内存中,在操作系统的调度下,可以实现并发地执行。这是这样的设计,大大提高了CPU的利用率。
- 进程的出现让每个用户感觉到自己独享CPU,因此,进程就是为了在CPU上实现多道编程而提出的。
- 进程的出现,可以让一台服务器同时处理多个任务,在多个任务之间来回切换并记录任务执行状态。
进程的缺陷:
- 进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
- 进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
线程的出现:
随着计算机技术的发展,进程出现了很多弊端,一是由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程;二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大。因此在80年代,出现了能独立运行的基本单位——线程(Threads)。
注意:
- 进程是资源分配的最小单位,线程是CPU调度的最小单位.
- 每一个进程中至少有一个线程。
进程和线程的关系
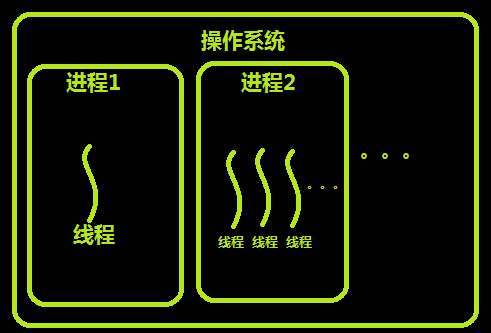
- 地址空间和其它资源(如打开文件):进程间相互独立,同一进程的各线程间共享。某进程内的线程在其它进程不可见。
- 通信:进程间通信IPC,线程间可以直接读写进程数据段(如全局变量)来进行通信——需要进程同步和互斥手段的辅助,以保证数据的一致性。
- 调度和切换:线程上下文切换比进程上下文切换要快得多。
- 在多线程操作系统中,进程不是一个可执行的实体。
线程的特点
在多线程的操作系统中,通常是在一个进程中包括多个线程,每个线程都是作为利用CPU的基本单位,是花费最小开销的实体。线程具有以下属性。
- 轻型实体。存储的较少
线程中的实体基本上不拥有系统资源,只是有一点必不可少的、能保证独立运行的资源。
线程的实体包括程序、数据和TCB。线程是动态概念,它的动态特性由线程控制块TCB(Thread Control Block)描述。 - 独立调度和分派的基本单位。 真正被操作系统调度的是线程
在多线程OS中,线程是能独立运行的基本单位,因而也是独立调度和分派的基本单位。由于线程很“轻”,故线程的切换非常迅速且开销小(在同一进程中的)。 - 共享进程资源。 进程的数据在多线程中使用不用ipc,而是直接使用
线程在同一进程中的各个线程,都可以共享该进程所拥有的资源,这首先表现在:所有线程都具有相同的进程id,这意味着,线程可以访问该进程的每一个内存资源;此外,还可以访问进程所拥有的已打开文件、定时器、信号量机构等。由于同一个进程内的线程共享内存和文件,所以线程之间互相通信不必调用内核。 - 可并发执行。 比如6个线程可以运行不同的代码
在一个进程中的多个线程之间,可以并发执行,甚至允许在一个进程中所有线程都能并发执行;同样,不同进程中的线程也能并发执行,充分利用和发挥了处理机与外围设备并行工作的能力。
内存中的线程
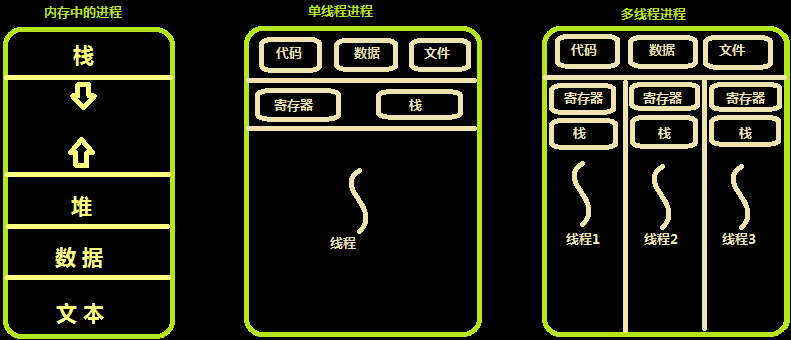
多个线程共享同一个进程的地址空间中的资源,是对一台计算机上多个进程的模拟,有时也称线程为轻量级的进程。
而对一台计算机上多个进程,则共享物理内存、磁盘、打印机等其他物理资源。多线程的运行也多进程的运行类似,是cpu在多个线程之间的快速切换。不同的进程之间是充满敌意的,彼此是抢占、竞争cpu的关系,如果迅雷会和QQ抢资源。而同一个进程是由一个程序员的程序创建,所以同一进程内的线程是合作关系,一个线程可以访问另外一个线程的内存地址,大家都是共享的,一个线程干死了另外一个线程的内存,那纯属程序员脑子有问题。
类似于进程,每个线程也有自己的堆栈,不同于进程,线程库无法利用时钟中断强制线程让出CPU,可以调用thread_yield运行线程自动放弃cpu,让另外一个线程运行。
线程通常是有益的,但是带来了不小程序设计难度,线程的问题是:
- 父进程有多个线程,那么开启的子线程是否需要同样多的线程
- 在同一个进程中,如果一个线程关闭了文件,而另外一个线程正准备往该文件内写内容呢?
因此,在多线程的代码中,需要更多的心思来设计程序的逻辑、保护程序的数据。
开启多线程
通过threading模块开启多线程
1 | # Python多线程模块 |
通过继承threading类 开启多线程
1 | import time |
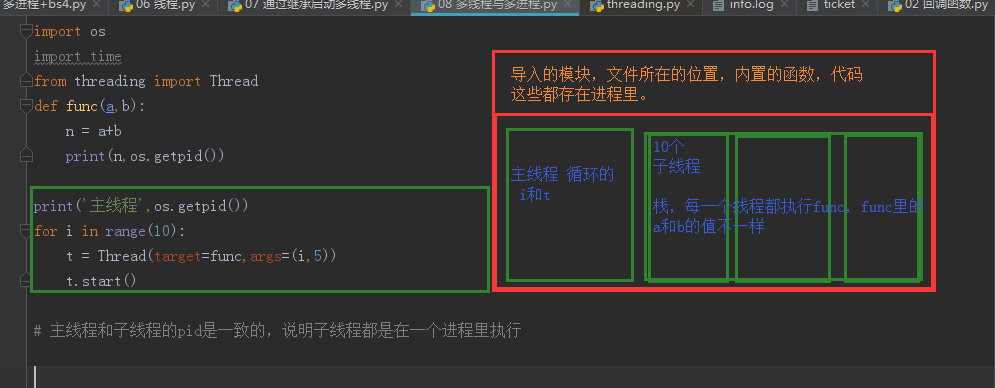
多线程与多进程
1 | import os |
内存数据共享
1 | # 内存数据共享 |
1 | # 总结: |
多线程与多进程执行效率对比
1 | import time |
线程模块中的其他方法
1 | import threading |
多线程实现简单的socket服务
1 | # server |
1 | # client |
守护线程 daemon=True
1 | import time |
线程锁 Lock
1 | import time |
递归锁解决死锁问题 RLock
1 | import time |
1 | # 递归锁 解决死锁问题 |
信号量 Semaphore
1 | import time |
事件 Event
1 | # 事件被创建的时候 |
定时器 Timer
1 | import time |
队列 queue
1 | # Queue 先进先出 队列 |
1 | # 队列 |
1 | # 栈 |
1 | # 优先级队列 |
线程池 concurrent.futures 模块
1 | # 1 介绍 |
1 | # 2 基本方法 |
1 | # 线程池 |
1 | # 流程总结: |
1 | ### 进程池 |
1 | ### map |
1 | # 回调函数 call_back |