
什么是协程
- 在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位。
- 无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建进程、创建线程、以及管理他们之间的切换。
- 基于单线程来实现并发又成为一个新的课题,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发。这样就可以节省创建线进程所消耗的时间。
并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长。协程的本质
就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
- 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
- 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
实现在多个任务之间切换 yield + send
- yield无法做到遇到io阻塞
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# 进程 : 启动多个进程,进程之间是由操作系统负责调用
# 线程 : 启动多个线程,真正被CPU执行的最小单位实际是线程
# 开启一个线程 :创建1个线程,属于线程的内存开销 寄存器和堆栈
# 关闭一个线程
# 线程在CPython下,由于全局GLI锁,多线程没有办法同时访问CPU,真正工作只有一个CPU
# 协程 : 本质上是一个线程
# 在多个任务之间切换,来节省IO时间
# 无需切换寄存器 和 堆栈,只是正常在程序之间切换
# ***** 能在多个任务之间切换
# ***** 协程中任务之间的切换也消耗时间,但是开销,要远远小于进程线程之间的切换。
# 实现并发的手段
### 实现在多个任务之间切换 yield + send
import time
def consumer():
# print(111111)
while True:
x = yield
time.sleep(1)
print('处理了数据: ' ,x)
def producer():
c = consumer() # 生成器
next(c) # 激活生成器,send之前必须next
for i in range(10):
time.sleep(1)
print('生产了数据 %s ' %i)
c.send(i)
producer() # 在producer控制了consumer函数,并且来回切换 即-在两个任务中切换
c = consumer() # 生成器
print(c) # <generator object consumer at 0x00000000021C84C0>
c.__next__()
next(c)
c.send(100)
c.send(200)
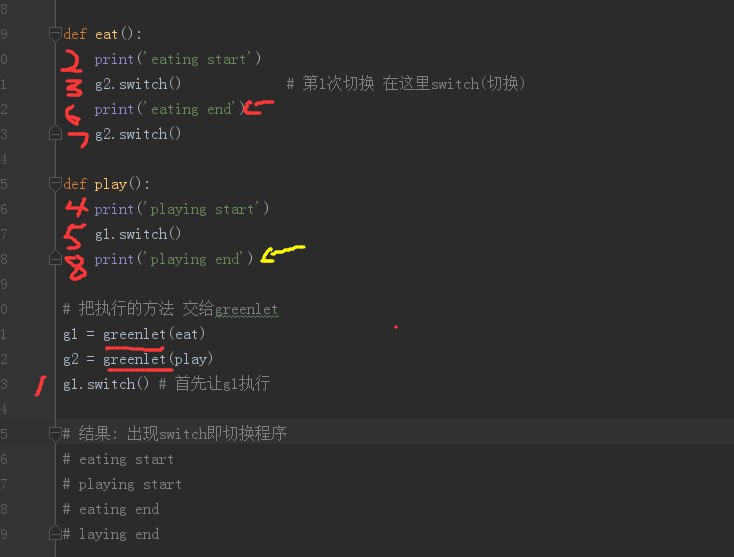
greenlet 模块切换执行程序
1 | from greenlet import greenlet |
使用gevent模块实现协程
安装:pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
1 | # g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 |
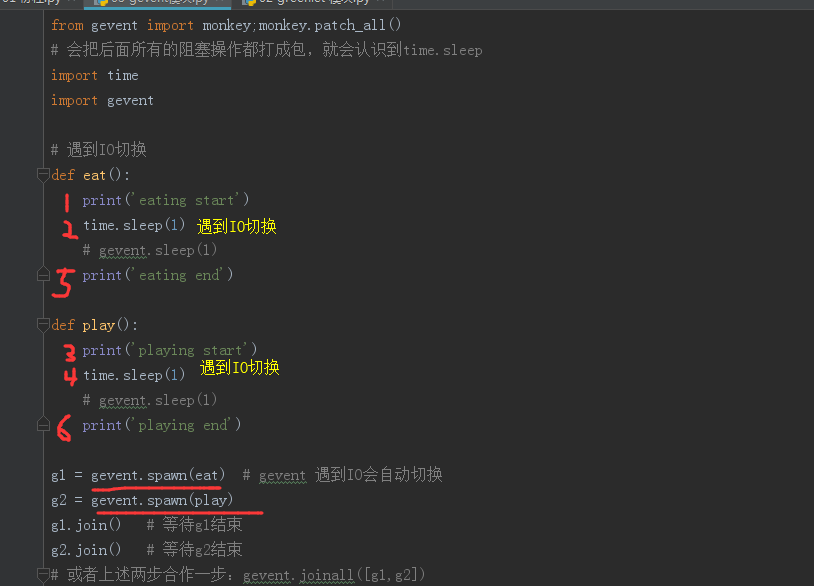
使用gevent实现IO切换
1 | from gevent import monkey;monkey.patch_all() |
gevent的同步和异步
1 | # gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞, |
协程爬虫小例子
1 | # 协程:能够在线程中实现并发效果 |