
Django ORM系统
ORM介绍
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在的互不匹配的现象的技术。
简单的说,ORM是通过使用描述对象和数据库之间映射的元数据,将程序中的对象自动持久化到关系数据库中
ORM的优势
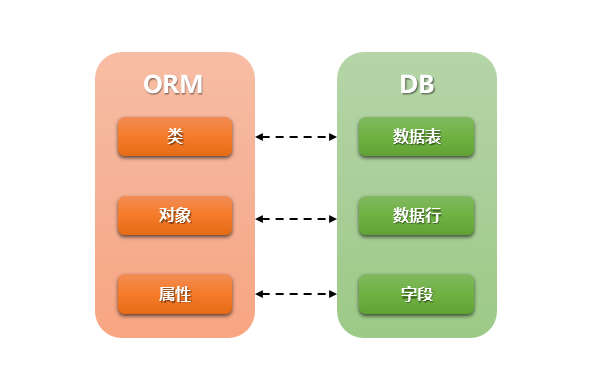
ORM解决的主要问题是对象和关系的映射。它通常把一个类和一个表一一对应,类的每个实例对应表中的一条记录,类的每个属性对应表中的每个字段。
ORM提供了对数据库的映射,不用直接编写SQL代码,只需像操作对象一样从数据库操作数据。
让软件开发人员专注于业务逻辑的处理,提高了开发效率。
ORM的劣势
ORM的缺点是会在一定程度上牺牲程序的执行效率。
ORM用多了SQL语句就不会写了,关系数据库相关技能退化…
ORM的总结
ORM只是一种工具,工具确实能解决一些重复,简单的劳动。这是不可否认的。
但我们不能指望某个工具能一劳永逸地解决所有问题,一些特殊问题还是需要特殊处理的。
但是在整个软件开发过程中需要特殊处理的情况应该都是很少的,否则所谓的工具也就失去了它存在的意义。
Django中的ORM
Django项目如何使用ORM连接MySQL
- 手动创建数据库
1 | CREATE DATABASE mybook CHARSET utf8 |
- 在settings.py里面配置数据库信息(告诉Django连接哪一个数据库)
1 | DATABASES = { |
- 在项目下的init.py文件中,告诉Django用pymysql代替MySQLdb连接数据库
1 | import pymysql |
- 在app/models.py 中定义类,类一定要继承models.Model
1 | class Book(models.Model): |
- 执行两条命令:
1 | 1. 在哪执行: |
Model
在Django中model是你数据的单一、明确的信息来源。
它包含了你存储的数据的重要字段和行为。
通常,一个模型(model)映射到一个数据库表,
基本情况:
- 每个模型都是一个Python类,它是django.db.models.Model的子类。
- 模型的每个属性都代表一个数据库字段。
综上所述,Django为您提供了一个自动生成的数据库访问API,详询官方文档链接。
快速入门
下面这个例子定义了一个 Person 模型,包含 first_name 和 last_name。
1 | from django.db import models |
first_name 和 last_name 是模型的字段。每个字段被指定为一个类属性,每个属性映射到一个数据库列。1
2
3
4
5CREATE TABLE myapp_person (
"id" serial NOT NULL PRIMARY KEY,
"first_name" varchar(30) NOT NULL,
"last_name" varchar(30) NOT NULL
);
一些说明:
- 表myapp_person的名称是自动生成的,如果你要自定义表名,需要在model的Meta类中指定 db_table 参数,强烈建议使用小写表名,特别是使用MySQL作为后端数据库时。
- id字段是自动添加的,如果你想要指定自定义主键,只需在其中一个字段中指定 primary_key=True 即可。如果Django发现你已经明确地设置了Field.primary_key,它将不会添加自动ID列。
- 本示例中的CREATE TABLE SQL使用PostgreSQL语法进行格式化,但值得注意的是,Django会根据配置文件中指定的数据库后端类型来生成相应的SQL语句。
- Django支持MySQL5.5及更高版本。
表与表之间的关系
- 一对多(出版社和书)
- 外键:
publisher = models.ForeignKey(to=’Publisher’)
在数据库里有没有publisher这个字段?
数据库实际生成的是 publisher_id ,Django默认加上_i
- 多对多(作者和书)
- 多对多关联:
from Django.db import models
books = models.ManyToManyField(to=’Book’)
多对多在数据库中,是通过第三章表建立的关
增删改查操作
- 单表增删改查:
1 | 增: |
- 外键的增删改查:
1 | 增、删、查同上 |
- 多对多操作:
1 | 1. 查询id为1的作者都写过哪些书: |
Django ORM 常用字段和参数
1 | AutoField |
基础使用
1 | # models.py |
1 | # Create Table |
1 | from app02 import models |

字段参数
1 | null:用于表示某个字段可以为空。 |
ORM 操作
基础操作,必知必会13条:
all 查询所有结果
1 | import os |
filter 筛选
1 | # 它包含了与所给筛选条件相匹配的对象 |
get 筛选
1 | # get查询 |
exclude 筛选不匹配
1 | # exclude 它包含了与所给筛选条件不匹配的对象 |
values 返回可迭代的字典序列
1 | # values 返回一个QuerySet对象,里面都是字典,不写字段名默认查询所有字段 |
values_list 返回可迭代的元组序列
1 | # values_list 返回一个QuerySet对象,里面都是元祖 |
order_by 按照指定的字段排序
1 | # ret = models.Person.objects.all() # ordering = "birthday" |
reverse 对一个有序的QuerySet 反向排序
1 | # 通常都使用order_by,不使用meta |
distinct 从返回结果中剔除重复纪录
count 返回QuerySet对象中对象的数量
1 | ret = models.Person.objects.all().count() |
first 返回QuerySet第一个对象
1 | ret = models.Person.objects.all().first() |
last 返回QuerySet最后一个对象
1 | ret = models.Person.objects.all().last() |
exists 判断表里是否有数据
1 | ret = models.Person.objects.all().exists() |
单表的双下划线查询
1 | # 单表查询的 双下划线方法 |
ForeignKey操作
外键的 正向查询 和 反向查询
- 先看外键在哪张表里
- 从有外键字段的表 查询 正向查询,反之 叫做反向查询
正向查询
1 | # 基于对象 跨表查询 |
1 | # 双下划线 跨表查询 |
反向查询
1 | # 基于对象 跨表查询 |
1 | # 双下划线 跨表查询 |
1 | # models.py 外键表配置 |
Django终端打印SQL语句
1 | # ORM操作 查看具体的SQL语句 |
多对多查询
“关联管理器”是在一对多或者多对多的关联上下文中使用的管理器。
- 它存在于下面两种情况:
- 外键关系的反向查询
- 多对多关联关系
- 简单来说就是当 点后面的对象 可能存在多个的时候就可以使用以下的方法。
1 | # 多对多 |
1 | # 1. create |
1 | # 2. add |
1 | # revome |
1 | # clear |
1 | 对于所有类型的关联字段,add()、create()、remove()和clear(),set()都会马上更新数据库。 |
聚合查询和分组查询
1 | # 聚合 aggregate |
1 | # 分组 annotate |
F查询和Q查询
1 | # 价格大于9.9的书 |
1 | # Q查询 |
在Python脚本中调用Django环境
1 | import os |
返回对象和QuerySet
1 | # 返回QuerySet对象的方法有 |
1 | # 特殊的QuerySet |
1 | # 返回具体对象的 |
1 | # 返回布尔值的方法有: |
1 | # 返回数字的方法有 |
练习
单标双下划线
1 | # 获取id大于1 且 小于5的书籍 |
正向查询
1 | # 正向查询 |