
ELK 架构介绍
核心组成
ELK是一个应用套件,由Elasticsearch、Logstash和Kibana三部分组件组成,简称ELK;
它是一套开源免费、功能强大的日志分析管理系统。
ELK可以将我们的系统日志、网站日志、应用系统日志等各种日志进行收集、过滤、清洗,然后进行集中存放并可用于实时检索、分析。
这三款软件都是开源软件,通常是配合使用,而且又先后归于Elastic.co公司名下,故又被简称为ELK Stack。
下图是ELK Stack的基础组成。
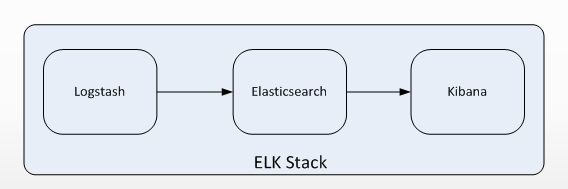
Elasticsearch 介绍
- Elasticsearch是一个实时的分布式搜索和分析引擎,它可以用于全文搜索,结构化搜索以及分析,采用Java语言编写。
- 它的主要特点如下:
1 | # 1. 实时搜索,实时分析 |
- Elasticsearch支持集群架构,典型的集群架构如下图所示:
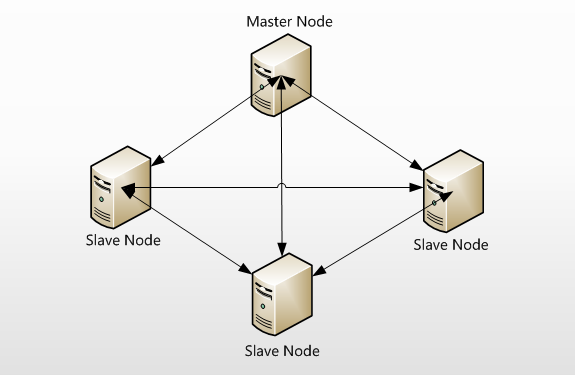
- 从图中可以看出,Elasticsearch集群中有Master Node和Slave Node两种角色,其实还有一种角色Client Node,这在后面会做深入介绍。
1 | # Master Node 主节点 用于节点的协调和调度 |
Logstash 介绍
Logstash是一款轻量级的、开源的日志收集处理框架,它可以方便的把分散的、多样化的日志搜集起来,并进行自定义过滤分析处理,然后传输到指定的位置,比如某个服务器或者文件。Logstash采用JRuby语言编写。
它的主要特点如下:
1 | # Logstash的理念很简单,从功能上来讲,它只做三件事情: |
- 别看它只做三件事,但通过组合输入和输出,可以变幻出多种架构实现多种需求。Logstash内部运行逻辑如下图所示:
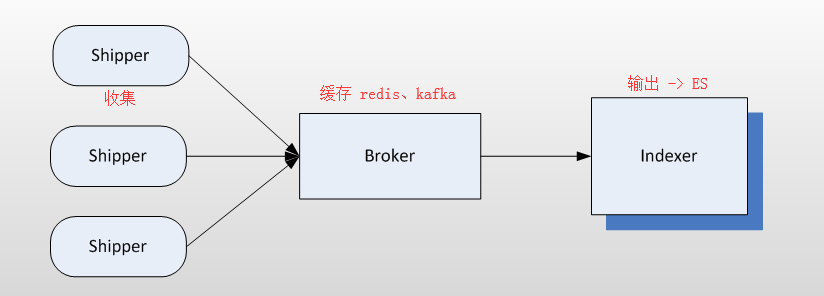
1 | Shipper:主要用来收集日志数据,负责监控本地日志文件的变化,及时把日志文件的最新内容收集起来, |
1 | Redis服务器是logstash官方推荐的broker,这个broker起数据缓存的作用。 |
1 | 这里需要说明的是,在实际应用中,LogStash自身并没有什么角色,只是根据不同的功能、不同的配置给出不同的称呼而已, |
kibana 介绍
Kibana是一个开源的数据分析可视化平台。
使用Kibana可以为Logstash和ElasticSearch提供的日志数据进行高效的搜索、可视化汇总和多维度分析。
还可以与Elasticsearch搜索引擎之中的数据进行交互。它基于浏览器的界面操作可以快速创建动态仪表板,实时监控ElasticSearch的数据状态与更改。
kibana使用的是nodejs开发。
ELK 工作流程
在需要收集日志的所有服务上部署logstash,作为logstash shipper用于监控并收集、过滤日志。
接着,将过滤后的日志发送给Broker。
然后,Logstash Indexer将存放在Broker中的数据再写入Elasticsearch。
Elasticsearch对这些数据创建索引。
最后由Kibana对其进行各种分析并以图表的形式展示。
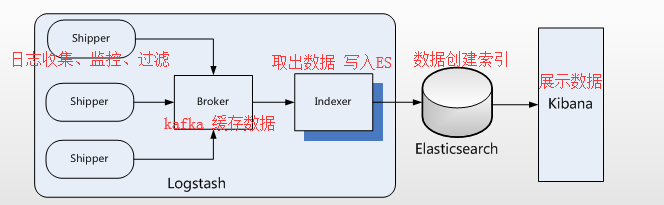
1 | 1. 有些时候,如果收集的日志量较大,为了保证日志收集的性能和数据的完整性, |