
ZooKeeper 概念介绍
在介绍ZooKeeper之前,先来介绍一下分布式协调技术。
所谓分布式协调技术: 主要是用来解决分布式环境当中多个进程之间的同步控制,
让他们有序的去访问某种共享资源,防止造成资源竞争(脑裂)的后果。
保障共享资源不会产生竞争
分布式系统
所谓分布式系统就是在不同地域分布的多个服务器,共同组成的一个应用系统来,为用户提供服务。
在分布式系统中最重要的是进程的调度
假设有一个分布在三个地域的服务器组成的一个应用系统,在第一台机器上挂载了一个资源,然后这三个地域分布的应用进程都要竞争这个资源。
但我们又不希望多个进程同时进行访问,这个时候就需要一个协调器,来让它们有序的来访问这个资源。
这个协调器就是分布式系统中经常提到的那个“锁”。
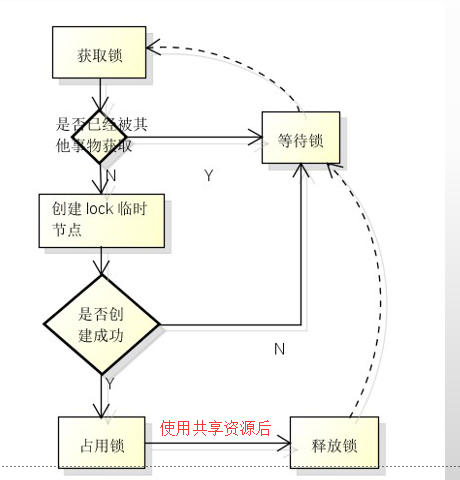
分布式 “锁”
例如 “进程1” 在使用该资源的时候,会先去获得这把锁。
“进程1” 获得锁以后会对该资源保持独占,此时其它进程就无法访问该资源。
“进程1” 在用完该资源以后会将该锁释放掉,以便让其它进程来获得锁。
由此可见,通过这个“锁”机制,就可以保证分布式系统中多个进程能够有序的访问该共享资源。
这里把这个分布式环境下的这个“锁”叫作分布式锁。这个分布式锁就是分布式协调技术实现的核心内容。
ZooKeeper 就是分布式 “锁”
综上所述,ZooKeeper是一种为分布式应用所设计的高可用、高性能的开源分布式协调服务。
它提供了一项基本服务:分布式锁服务。
同时,也提供了数据的维护和管理机制,如:统一命名服务、状态同步服务、集群管理、分布式消息队列、分布式应用配置项的管理等等。
ZooKeeper 应用举例
- 这里以ZooKeeper提供的基本服务分布式锁为例进行介绍。
- 在分布式锁服务中,有一种最典型应用场景,就是通过对集群进行Master角色的选举,来解决分布式系统中的单点故障问题。
- 所谓单点故障,就是在一个主从的分布式系统中,主节点负责任务调度分发,从节点负责任务的处理,而当主节点发生故障时,整个应用系统也就瘫痪了,那么这种故障就称为单点故障。
- 解决单点故障,传统的方式是采用一个备用节点,这个备用节点定期向主节点发送ping包,主节点收到ping包以后向备用节点发送回复Ack信息,
- 当备用节点收到回复的时候就会认为当前主节点运行正常,让它继续提供服务。
- 而当主节点故障时,备用节点就无法收到回复信息了,此时,备用节点就认为主节点宕机,然后接替它成为新的主节点继续提供服务。
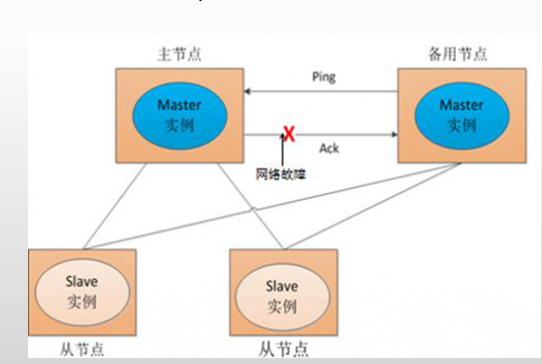
- 这种传统解决单点故障的方法,虽然在一定程度上解决了问题,但是有一个隐患,就是网络问题。
- 可能会存在这样一种情况:主节点并没有出现故障,只是在回复ack响应的时候网络发生了故障,这样备用节点就无法收到回复。
- 那么它就会认为主节点出现了故障,接着,备用节点将接管主节点的服务,并成为新的主节点。
- 此时,分布式系统中就出现了两个主节点(双Master节点)的情况,双Master节点的出现,会导致分布式系统的服务发生混乱。
- 这样的话,整个分布式系统将变得不可用。为了防止出现这种情况,就需要引入ZooKeeper来解决这种问题。
ZooKeeper 工作原理
- 下面通过三种情形,介绍下Zookeeper是如何进行工作的。
Master 启动
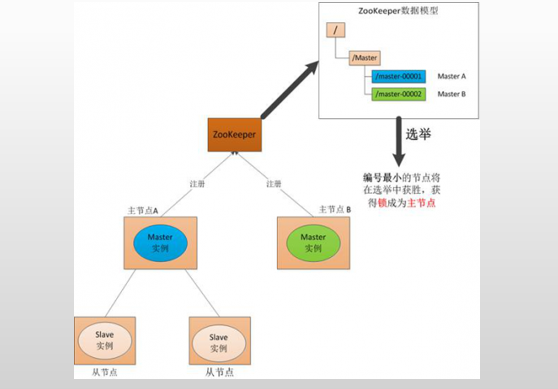
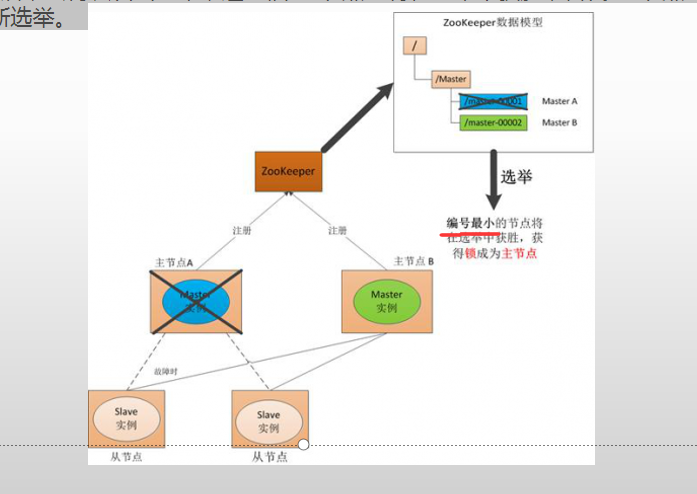
在分布式系统中引入Zookeeper以后,就可以配置多个主节点,这里以配置两个主节点为例,假定它们是”主节点A”和”主节点B”。
当两个主节点都启动后,它们都会向ZooKeeper中注册节点信息。
我们假设”主节点A”锁注册的节点信息是”master00001”,”主节点B”注册的节点信息是”master00002”,
注册完以后会进行选举,选举有多种算法,这里以编号最小作为选举算法,那么编号最小的节点将在选举中获胜并获得锁成为主节点,也就是”主节点A”将会获得锁成为主节点,
然后”主节点B”将被阻塞成为一个备用节点。这样,通过这种方式Zookeeper就完成了对两个Master进程的调度。完成了主、备节点的分配和协作。
Master 故障
如果”主节点A”发生了故障,这时候它在ZooKeeper所注册的节点信息会被自动删除。
而ZooKeeper会自动感知节点的变化,发现”主节点A”故障后,会再次发出选举,这时候”主节点B”将在选举中获胜,替代”主节点A”成为新的主节点。
这样就完成了主、备节点的重新选举。
Master 恢复
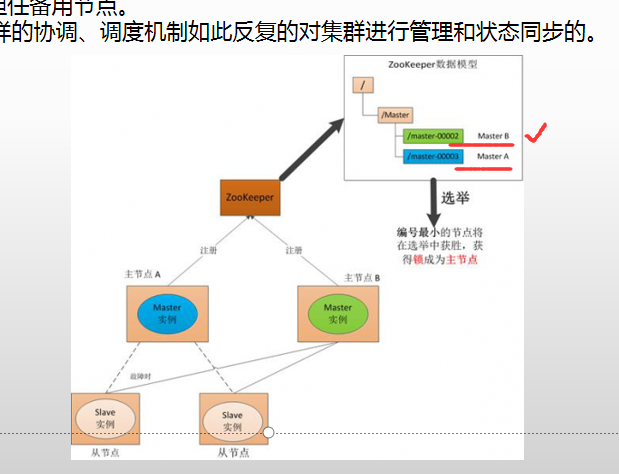
如果主节点恢复了,它会再次向ZooKeeper注册自身的节点信息。
只不过这时候它注册的节点信息将会变成”master00003”,而不是原来的信息。
ZooKeeper会感知节点的变化再次发动选举,这时候”主节点B”在选举中会再次获胜继续担任”主节点”,”主节点A”会担任备用节点。
Zookeeper就是通过这样的协调、调度机制如此反复的对集群进行管理和状态同步的。
1 | 1. 每个master节点都会在zookeeper 注册信息 |
Zookeeper 集群架构
Zookeeper一般是通过集群架构来提供服务的,下图是Zookeeper的基本架构图。
Zookeeper集群主要角色有Server和client,其中,Server又分为Leader、Follower和Observer三个角色,每个角色的含义如下:
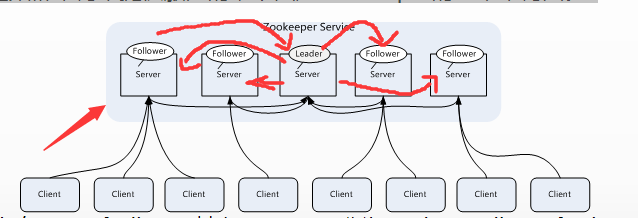
1 | Leader:领导者角色,主要负责投票的发起和决议,以及更新系统状态。 |
1 | 1. Zookeeper集群中每个Server在内存中存储了一份数据,在Zookeeper启动时,将从实例中选举一个Server作为leader, |