
Filebeat 简介
1 | elk官网 https://www.elastic.co/ |
Filebeat是一个开源的文本日志收集器,它是elastic公司Beats数据采集产品的一个子产品,采用go语言开发,
一般安装在业务服务器上作为代理来监测日志目录或特定的日志文件,并把它们发送到logstash、elasticsearch、redis或Kafka等。
可以在官方地址 https://www.elastic.co/downloads/beats 下载各个版本的Filebeat。
Filebeat 架构与运行原理
Filebeat是一个轻量级的日志监测、传输工具,
它最大的特点是性能稳定、配置简单、占用系统资源很少。
这也是强烈推荐Filebeat的原因。
下图是官方给出的Filebeat架构图:
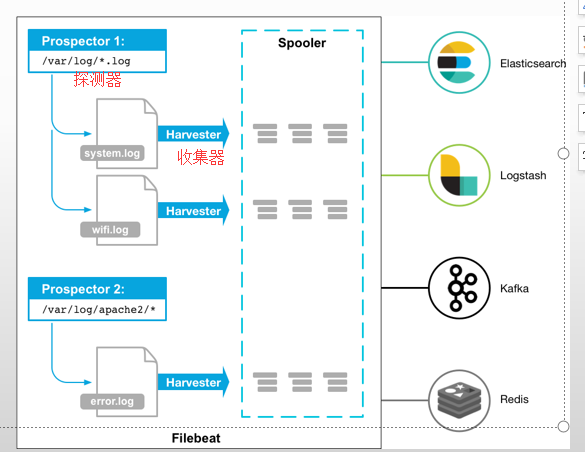
运行原理
从图中可以看出,Filebeat主要由两个组件构成: prospector(探测器)和harvester(收集器)。这两类组件一起协作完成Filebeat的工作。
Harvester负责进行单个文件的内容收集,在运行过程中,每一个Harvester会对一个文件逐行进行内容读取,并且把读写到的内容发送到配置的output中。
当Harvester开始进行文件的读取后,将会负责这个文件的打开和关闭操作,因此,在Harvester运行过程中,文件都处于打开状态。
如果在收集过程中,删除了这个文件或者是对文件进行了重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。
Prospector负责管理Harvster,它会找到所有需要进行读取的数据源。然后交给Harvster进行内容收集,
如果input type配置的是log类型,Prospector将会去配置路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。
综上所述,filebeat的工作流程为
1 | 1. 当开启filebeat程序的时候,它会启动一个或多个探测器(prospector)去检测指定的日志目录或文件,在配置文件定义好 |