ELK 应用案例
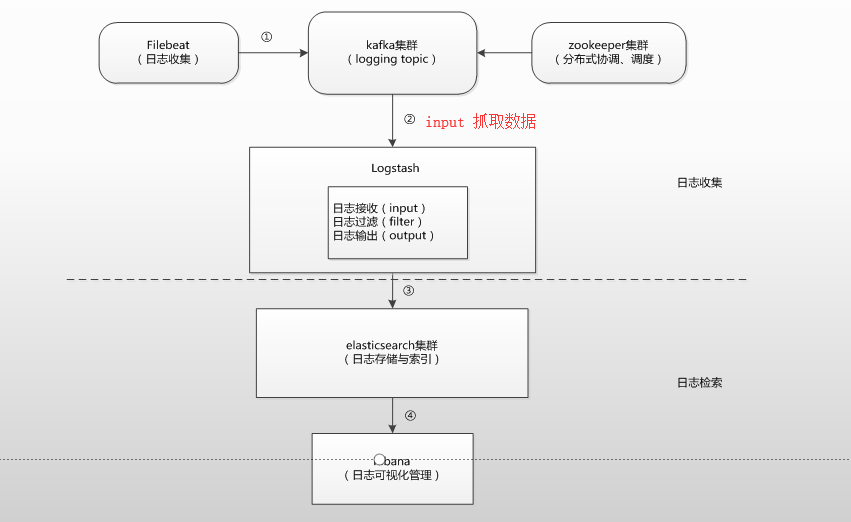
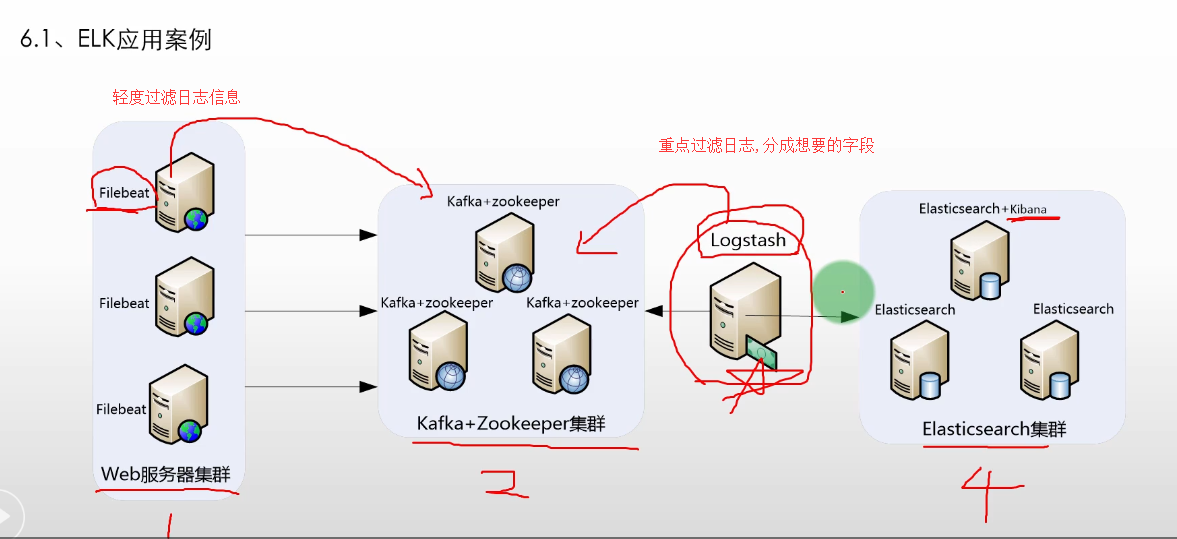
典型 ELK 应用架构
此架构稍微有些复杂,因此,这里做一下架构解读。 这个架构图从左到右,总共分为5层,每层实现的功能和含义分别介绍如下:
第一层. 数据采集层
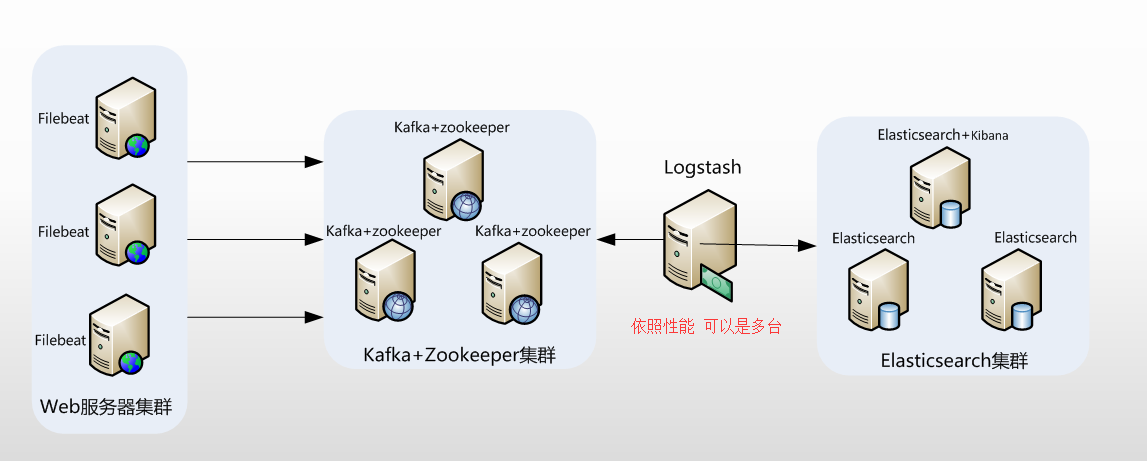
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。
filebeat 只能做简单的数据过滤,数据此时还是原始数据。
第二层. 消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。
通过zookeeper调度和协调kafka工作,比如主节点挂掉了,选取主节点等
第三层. 数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。
如数据量过大,或者考虑性能,Logstash可以为多台。
第四层. 数据持久化存储
- Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。
第五层. 数据查询、展示层
- Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。\
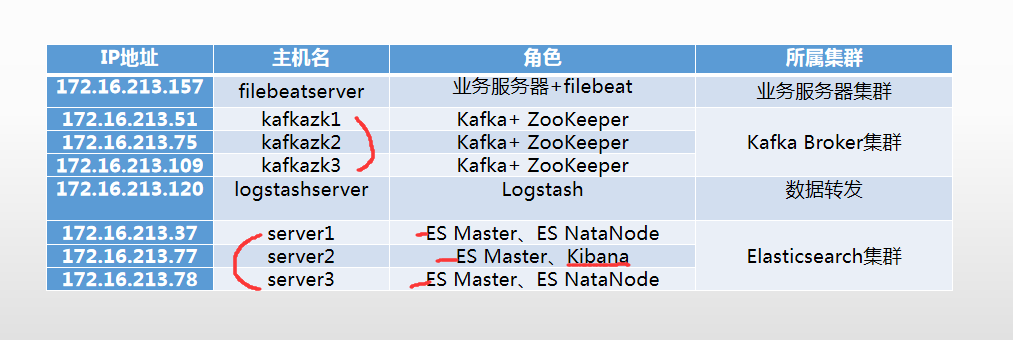
环境与角色说明
服务器环境与角色
- 操作系统统一采用Centos7.5版本,各个服务器角色如下表所示:(我使用阿里云服务器,操作系统可能会是7.6)
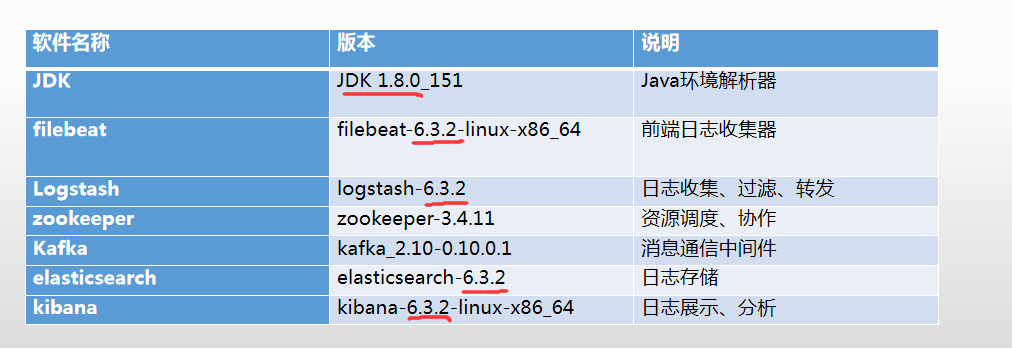
软件环境与版本
- 下表详细说明了本节安装软件对应的名称和版本号,其中,ELK三款软件推荐选择一样的版本,这里选择的是6.3.2版本。
安装JDK以及设置环境变量
选择合适版本并下载JDK
- Zookeeper 、elasticsearch和Logstash都依赖于Java环境,并且elasticsearch和Logstash要求JDK版本至少在JDK1.7或者以上。
- 安装过程
1 | [root@server2 ~]# ls |
安装并配置 elasticsearch 集群
elasticsearch 集群的架构与角色
在ElasticSearch的架构中,有三类角色,分别是Client Node、Data Node和Master Node,
搜索查询的请求一般是经过Client Node来向 Data Node 获取数据,
而索引查询首先请求 Master Node 节点,然后 Master Node 将请求分配到多个Data Node节点完成一次索引查询。
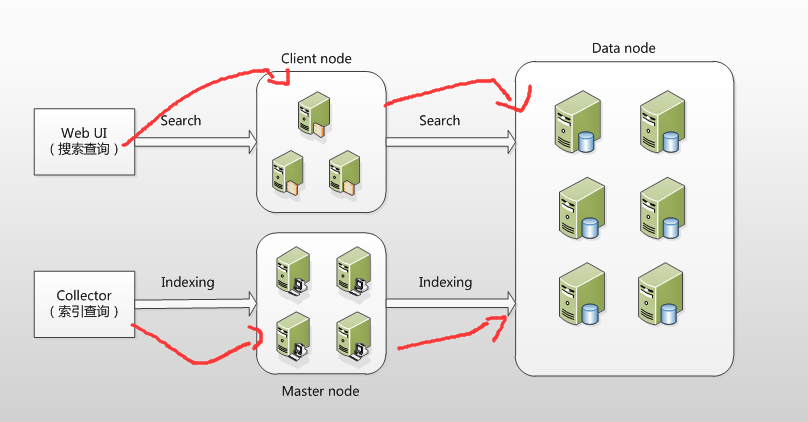
集群中每个角色的含义介绍如下:
- master node:
- 可以理解为主节点,主要用于元数据(metadata)的处理,比如索引的新增、删除、分片分配等,以及管理集群各个节点的状态。
- elasticsearch集群中可以定义多个主节点,但是,在同一时刻,只有一个主节点起作用,其它定义的主节点,是作为主节点的候选节点存在。
- 当一个主节点故障后,集群会从候选主节点中选举出新的主节点。
- data node:
- 数据节点,这些节点上保存了数据分片。它负责数据相关操作,比如分片的CRUD、搜索和整合等操作。
- 数据节点上面执行的操作都比较消耗 CPU、内存和I/O资源,因此数据节点服务器要选择较好的硬件配置,才能获取高效的存储和分析性能。
- client node:
- 客户端节点,属于可选节点,是作为任务分发用的,它里面也会存元数据,但是它不会对元数据做任何修改。
- client node存在的好处是可以分担data node的一部分压力,因为elasticsearch的查询是两层汇聚的结果,
- 第一层是在data node上做查询结果汇聚,然后把结果发给client node,client node接收到data node发来的结果后再做第二次的汇聚,
- 然后把最终的查询结果返回给用户。这样,client node就替data node分担了部分压力。
安装 elasticsearch集群
1 | # 环境介绍 |
- 下载ES
1 | https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz |
1 | [root@server2 ~]# mkdir -p /app/elk |
1 | # 解压安装es |
1 | # 目录说明 |
1 | [root@server2 elasticsearch]# cd config/ |
增加es用户授权
1 | #增加用户组 |
操作系统调优
操作系统以及JVM调优主要是针对安装elasticsearch的机器。对于操作系统,需要调整几个内核参数,将下面内容添加到/etc/sysctl.conf文件中:
fs.file-max主要是配置系统最大打开文件描述符数,建议修改为655360或者更高,
vm.max_map_count影响Java线程数量,用于限制一个进程可以拥有的VMA(虚拟内存区域)的大小,系统默认是65530,建议修改成262144或者更高。
1 | [root@server2 config]# vim /etc/sysctl.conf |
- 调整进程最大打开文件描述符(nofile)、最大用户进程数(nproc)和最大锁定内存地址空间(memlock),添加如下内容到/etc/security/limits.conf文件中:
1 | [root@server2 config]# vim /etc/security/limits.conf |
- 最后,还需要修改/etc/security/limits.d/20-nproc.conf文件(centos7.x系统)
1 | [root@server2 config]# vim /etc/security/limits.d/20-nproc.conf |
JVM调优
- JVM调优主要是针对elasticsearch的JVM内存资源进行优化,elasticsearch的内存资源配置文件为jvm.options,
- 此文件位于/usr/local/elasticsearch/config目录下,打开此文件,修改如下内容:
1 | [root@server2 ~]# cd /usr/local/elasticsearch/config/ |
配置 elasticsearch
- elasticsearch的配置文件均在elasticsearch根目录下的config文件夹,这里是/usr/local/elasticsearch/config目录,
- 主要有jvm.options、elasticsearch.yml和log4j2.properties三个主要配置文件。这里重点介绍elasticsearch.yml一些重要的配置项及其含义。
- 这里配置的elasticsearch.yml文件内容如下:
1 | [root@server2 config]# cd /usr/local/elasticsearch/config |
注意node.name肯定不能相同,其他可以相同
cluster.name: elkbigdata
- 配置elasticsearch集群名称,默认是elasticsearch。这里修改为elkbigdata,elasticsearch会自动发现在同一网段下的集群名为elkbigdata的主机。
- node.name: server1
- 节点名,任意指定一个即可,这里是server1,我们这个集群环境中有三个节点,分别是server1、server2和server3,记得根据主机的不同,要修改相应的节点名称。
- node.master: true
- 指定该节点是否有资格被选举成为master,默认是true,elasticsearch集群中默认第一台启动的机器为master角色,如果这台服务器宕机就会重新选举新的master。
- node.data: true
- 指据,默认为true,表示数据存储节点,如果节点配置node.master:false并且node.data: false,则该节点就是client node。
- 这个client node类似于一个“路由器”,负责将集群层面的请求转发到主节点,将数据相关的请求转发到数据节点。
- path.data:/data1/elasticsearch,/data2/elasticsearch
- 设置索引数据的存储路径,默认是elasticsearch根目录下的data文件夹,这里自定义了两个路径,可以设置多个存储路径,用逗号隔开。
- path.logs: /usr/local/elasticsearch/logs
- 设置日志文件的存储路径,默认是elasticsearch根目录下的logs文件夹
- bootstrap.memory_lock: true
- 此配置项一般设置为true用来锁住物理内存。linux下可以通过“ulimit -l” 命令查看最大锁定内存地址空间(memlock)是不是unlimited
- network.host: 0.0.0.0
- 此配置项用来设置elasticsearch提供服务的IP地址,默认值为0.0.0.0,此参数是在elasticsearch新版本中增加的,此值设置为服务器的内网IP地址即可。
- http.port: 9200
- 设置elasticsearch对外提供服务的http端口,默认为9200。其实,还有一个端口配置选项transport.tcp.port,此配置项用来设置节点间交互通信的TCP端口,默认是9300。
- discovery.zen.minimum_master_nodes: 1
- 配置当前集群中最少的master节点数,默认为1,也就是说,elasticsearch集群中master节点数不能低于此值,如果低于此值,elasticsearch集群将停止运行。在三个以上节点的集群环境中,建议配置大一点的值,推荐2至4个为好。
- discovery.zen.ping.unicast.hosts: [“172.17.70.229:9300”, “172.17.70.230:9300”,”172.17.70.231:9300”]
- 设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。这里需要注意,master节点初始列表中对应的端口是9300。即为集群交互通信端口。
创建data目录
1 | # /data1/elasticsearch,/data2/elasticsearch |
使用普通用户启动ES服务
1 | # es5版本后 禁止root用户启动es |
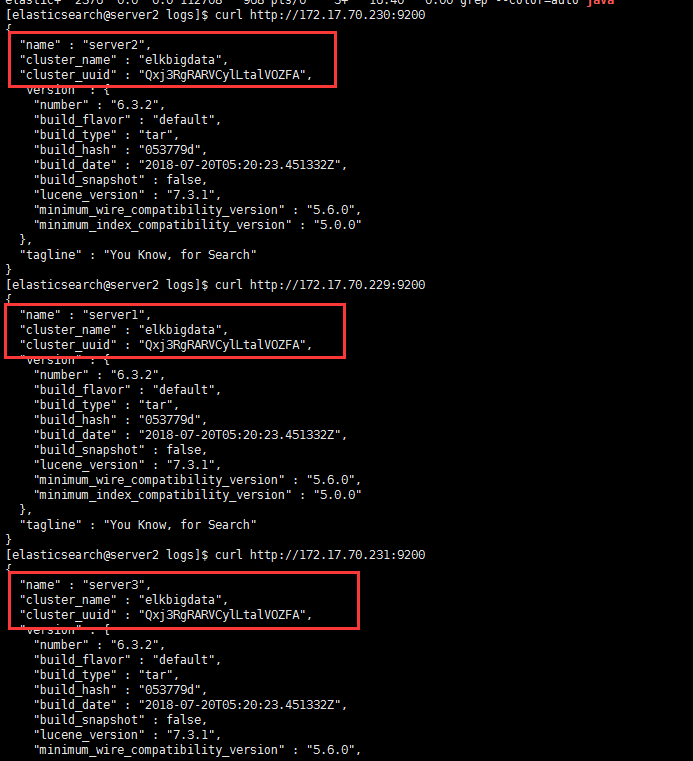
验证elasticsearch集群的正确性
1 | # 将所有elasticsearch节点的服务启动后,在任意一个节点执行如下命令: |
安装与配置 zookeeper 集群
- 对于集群模式下的ZooKeeper部署,官方建议至少要三台服务器,关于服务器的数量,推荐是奇数个(3、5、7、9等等),以实现ZooKeeper集群的高可用,这里使用三台服务器进行部署
下载与安装zookeeper
- ZooKeeper是用Java编写的,需要安装Java运行环境,可以从zookeeper官网https://zookeeper.apache.org/获取zookeeper安装包,这里安装的版本是zookeeper-3.4.13.tar.gz。
- 将下载下来的安装包直接解压到一个路径下即可完成zookeeper的安装,
1 | [root@server2 elk]# tar -zxvf zookeeper-3.4.13.tar.gz -C /usr/local |
配置zookeeper
- zookeeper 安装到了/usr/local目录下,因此,zookeeper的配置模板文件/usr/local/zookeeper/conf/zoo_sample.cfg,
- 拷贝zoo_sample.cfg并重命名为zoo.cfg,重点配置如下内容:
1 | [root@server2 conf]# cd /usr/local/zookeeper/conf/ |
1 | # 配置属性参数 |
1 | [root@kafkazk1 conf]# grep ^'[a-Z]' zoo.cfg |
每个配置项含义如下
- tickTime:zookeeper使用的基本时间度量单位,以毫秒为单位,它用来控制心跳和超时。2000表示2 tickTime。更低的tickTime值可以更快地发现超时问题。
- initLimit:这个配置项是用来配置Zookeeper集群中Follower服务器初始化连接到Leader时,最长能忍受多少个心跳时间间隔数(也就是tickTime)
- syncLimit:这个配置项标识Leader与Follower之间发送消息,请求和应答时间长度最长不能超过多少个tickTime的时间长度
- dataDir:必须配置项,用于配置存储快照文件的目录。需要事先创建好这个目录,如果没有配置dataLogDir,那么事务日志也会存储在此目录。
- clientPort:zookeeper服务进程监听的TCP端口,默认情况下,服务端会监听2181端口。
- server.A=B:C:D:其中A是一个数字,表示这是第几个服务器;B是这个服务器的IP地址;
C表示的是这个服务器与集群中的Leader服务器通信的端口;D 表示如果集群中的Leader服务器宕机了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
myid 文件
- 除了修改zoo.cfg配置文件外,集群模式下还要配置一个文件myid,
- 这个文件需要放在dataDir配置项指定的目录下,这个文件里面只有一个数字,如果要写入1,表示第一个服务器,与zoo.cfg文本中的server.1中的1对应,以此类推,
- 在集群的第二个服务器zoo.cfg配置文件中dataDir配置项指定的目录下创建myid文件,写入2,这个2与zoo.cfg文本中的server.2中的2对应。
- Zookeeper在启动时会读取这个文件,得到里面的数据与zoo.cfg里面的配置信息比较,从而判断每个zookeeper server的对应关系。
- 为了保证zookeeper集群配置的规范性,建议将zookeeper集群中每台服务器的安装和配置文件路径都保存一致。
1 | server1 myid 1 |
1 | [root@kafkazk1 conf]# mkdir -p /data/zookeeper |
启动 zookeeper
1 | # 三台机器一起启动 |
1 | # 查看启动是否成功 |
1 | # 有时候为了启动Zookeeper方面,也可以添加zookeeper环境变量到系统的/etc/profile中, |
安装并配置 Kafka Broker 集群
- 这里将kafka和zookeeper部署在一起了。另外,由于是部署集群模式的kafka,因此下面的操作需要在每个集群节点都执行一遍。
下载与安装Kafka
1 | # 选择kafka版本 需要与 filebeat 需求的对应 |
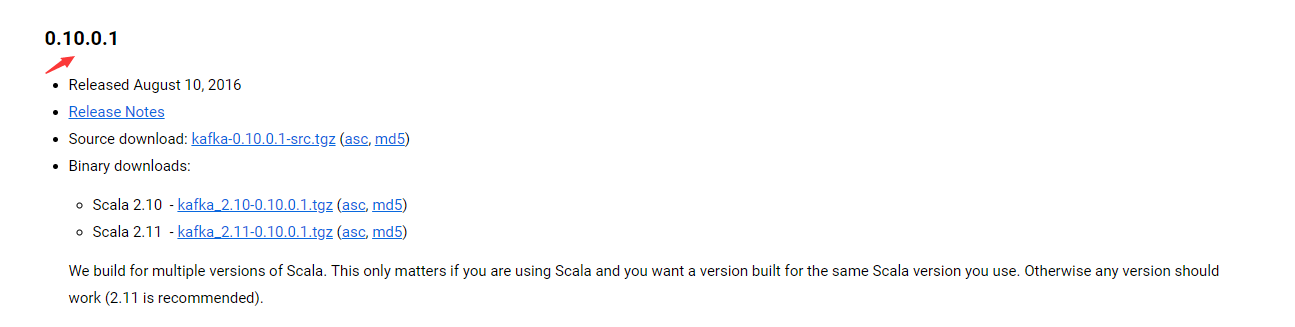
可以从kafka官网 https://kafka.apache.org/downloads 获取kafka安装包,这里推荐的版本是kafka_2.10-0.10.0.1.tgz,
将下载下来的安装包直接解压到一个路径下即可完成kafka的安装,这里统一将kafka安装到/usr/local目录下,基本操作过程如下:
1 | [root@kafkazk1 elk]# tar -zxvf kafka_2.10-0.10.0.1.tgz -C /usr/local |
1 | [root@kafkazk1 kafka]# ls -l |
1 | # 主配置文件 |
配置 kafka集群
1 | # 常用配置 |
每个配置项含义如下
1 | 1. broker.id: |
本次配置
- kafka集群都要修改配置文件
1 | [root@kafkazk1 config]# grep ^'[a-Z]' server.properties |
启动kafka集群
- 在启动kafka集群前,需要确保ZooKeeper集群已经正常启动。
- 依次在kafka各个节点上执行如下命令即可
1 | # nohup 后台启动 |
1 | 这里将kafka放到后台运行,启动后,会在启动kafka的当前目录下生成一个nohup.out文件, |
1 | [root@kafkazk2 kafka]# tail -200 nohup.out |
kafka 集群基本命令操作
kefka提供了多个命令用于查看、创建、修改、删除topic信息,
也可以通过命令测试如何生产消息,消费消息等,这些命令位于kafka安装目录的bin目录下,这里是/usr/local/kafka/bin。
登录任意一台kafka集群节点,切换到此目录下,即可进行命令操作。
下面列举kafka的一些常用命令的使用方法:
1 | # 务必掌握 |
1 | # 显示当前kafka集群中的topic列表 |
1 | # 创建一个topic |
1 | # 查看某个topic的属性信息 |
1 | # 生产消息 |
1 | # 消费消息 |


1 | # 从头开始接收 查看所有消息 |
实际生产机制,并不是键盘生产消息,而是通过第三方软件,比如logstash或者filebeat,向kafka生产数据
消费者 可以使ES 也可以使logstash,最终实现数据传递
kafka就是生产和消费数据的中介,他实现数据的传递,消息队列,持久化缓存数据,作用于消息传输和保存数据
1 | # 删除一个topic |
安装并配置 Filebeat
为什么要使用 filebeat
- Logstash功能虽然强大,但是它依赖java、在数据量大的时候,Logstash进程会消耗过多的系统资源,这将严重影响业务系统的性能,
- 而filebeat就是一个完美的替代者,filebeat是Beat成员之一,基于Go语言,没有任何依赖,配置文件简单,格式明了,
- 同时,filebeat比logstash更加轻量级,所以占用系统资源极少,非常适合安装在生产机器上。
下载与安装 filebeat
- 由于filebeat基于go语言开发,无其他任何依赖,因而安装非常简单,
- 可以从elastic官网https://www.elastic.co/downloads/beats/filebeat 获取filebeat安装包,
- 这里下载的版本是filebeat-6.3.2-linux-x86_64.tar.gz。
- 将下载下来的安装包直接解压到一个路径下即可完成filebeat的安装。
- 根据前面的规划,将filebeat安装到filebeat server主机上,这里设定将filebeat安装到/usr/local目录下,
- 基本操作过程如下:
1 | [root@filebeat1 ~]# mkdir -p /app/elk |
1 | [root@filebeat1 filebeat]# cd /usr/local/filebeat/ |
1 | # 配置方法 |
配置 filebeat
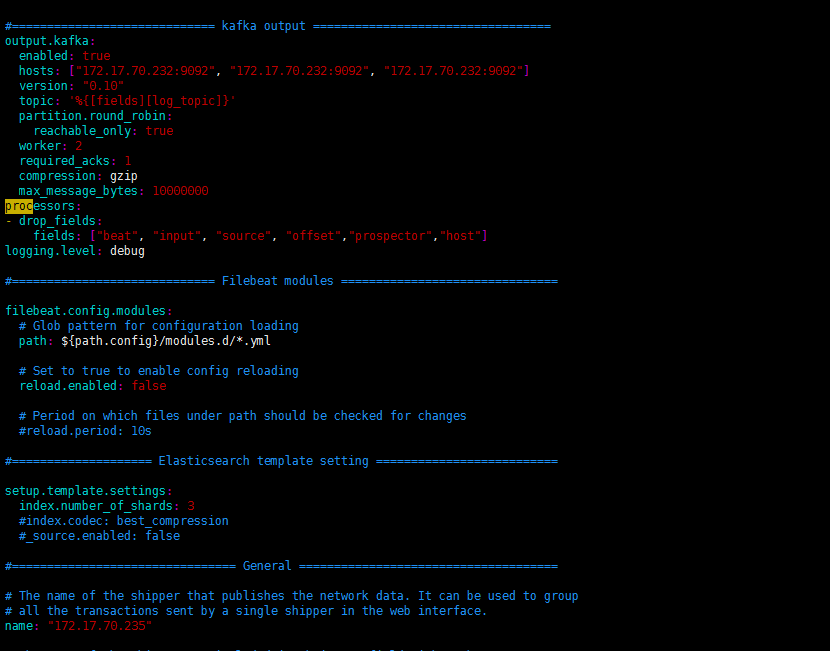
- filebeat的配置文件目录为/usr/local/filebeat/filebeat.yml,这里仅列出常用的配置项,内容如下:
1 | filebeat.inputs: |
1 | # 实验版本 |
1 | # 官方文档支持 |
1 | # 所有输出的选项 都需要注释 默认的是es |

1 | 收费插件 Xpack |
配置项的含义介绍如下:
1 | 1. filebeat.inputs: |
1 | # 过滤 清除字段 |

启动 filebeat 收集日志
- 所有配置完成之后,就可以启动filebeat,开启收集日志进程了,启动方式如下:
1 | [root@filebeat1 filebeat]# cd /usr/local/filebeat/ |
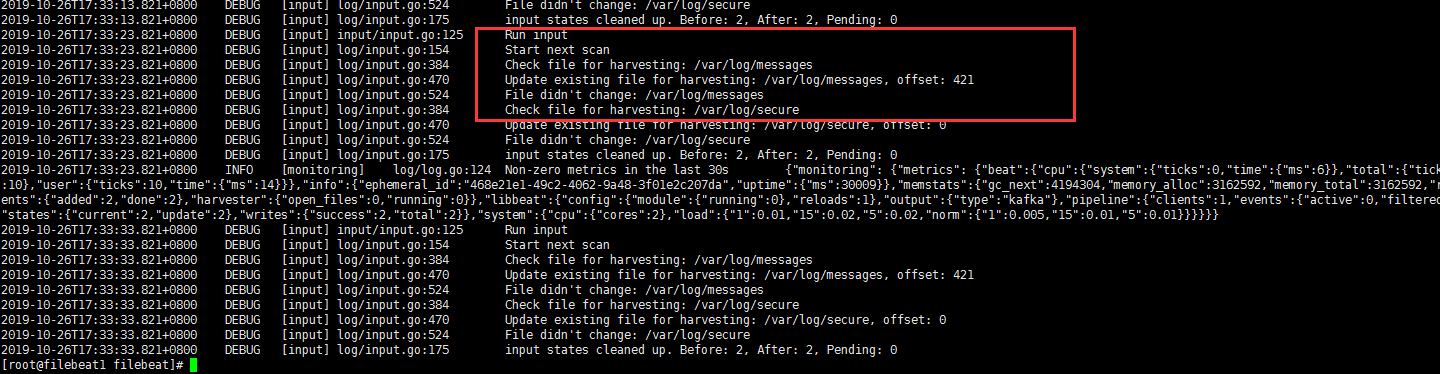
1 | # 看看要收集的日志 格式 |
模拟测试 filebeat 输出信息格式解读
- 开启filebeat的日志查看记录,有变化就会更新到日志中
1 | [root@filebeat1 filebeat]# tailf nohup.out |
- 模拟一个失败的登录,日志产生到 /var/log/secure 中
1 | # 找一台服务器访问filebeat主机,故意失败登录,故意输错密码 |
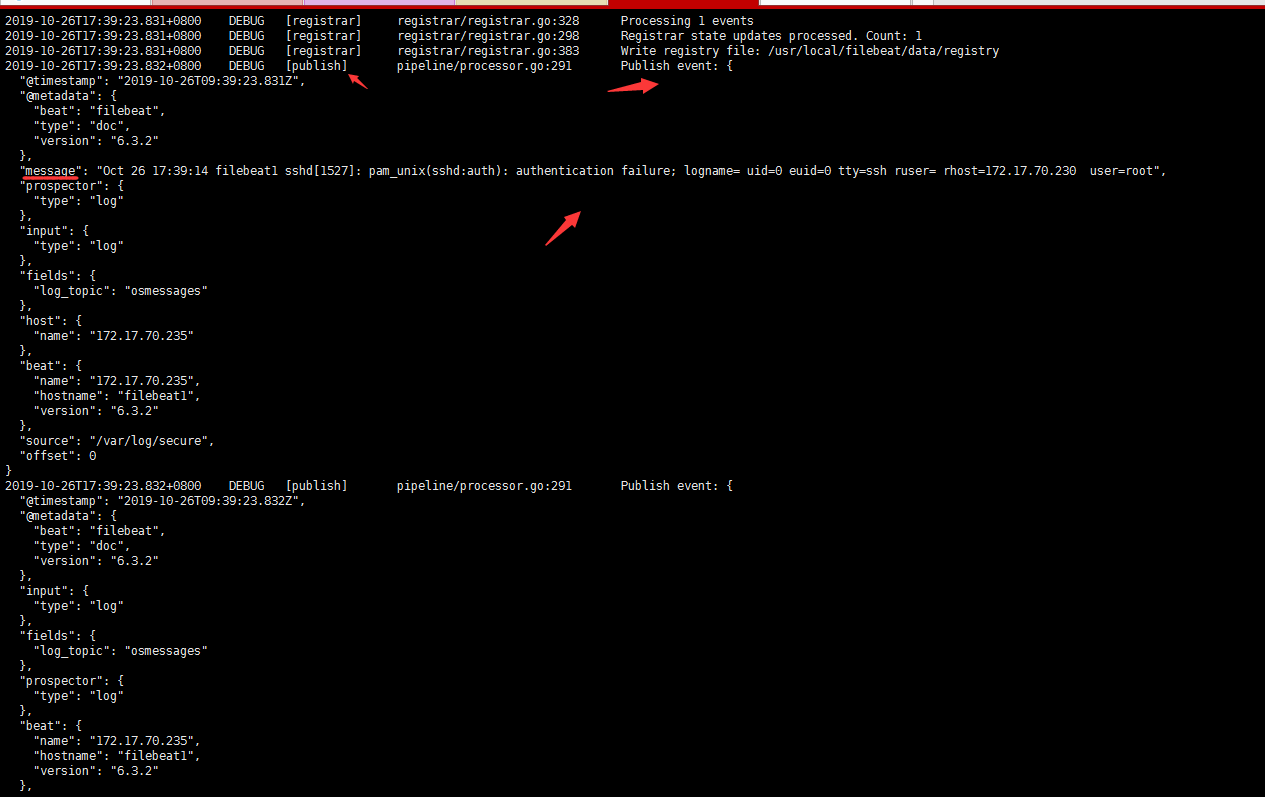

filebeat输出信息格式解读
- 从这个输出可以看到,输出日志被修改成了JSON格式,日志总共分为10个字段,
- 分别是 “@timestamp”、”@metadata”、”beat”、”host”、”source”、
“offset”、”message”、”prospector”、”input”和”fields”字段, - 每个字段含义如下:
1 | 1. @timestamp:时间字段,表示读取到该行内容的时间。 |
过滤字段
- 日志输出格式介绍和字段删减方法
- filebeat收集了这么多字段的数据,所有我们要做一个简单的过滤 再交给后面的程序
- 通过filebeat接收到的内容,默认增加了不少字段,但是有些字段对数据分析来说没有太大用处,
- 所以有时候需要删除这些没用的字段,在filebeat配置文件中添加如下配置,即可删除不需要的字段:
- 这个设置表示删除”beat”、”input”、”source”、”offset” 四个字段,其中,
- @timestamp 和@metadata字段是不能删除的,就算加上也过滤不了。
- 做完这个设置后,再次查看kafka中的输出日志,已经不再输出这四个字段信息了。
- 后面可以通过logstash进行更好的过滤,不用担心
1 | processors: |
1 | # 重启filebeat |
1 | # 减少输出后 |
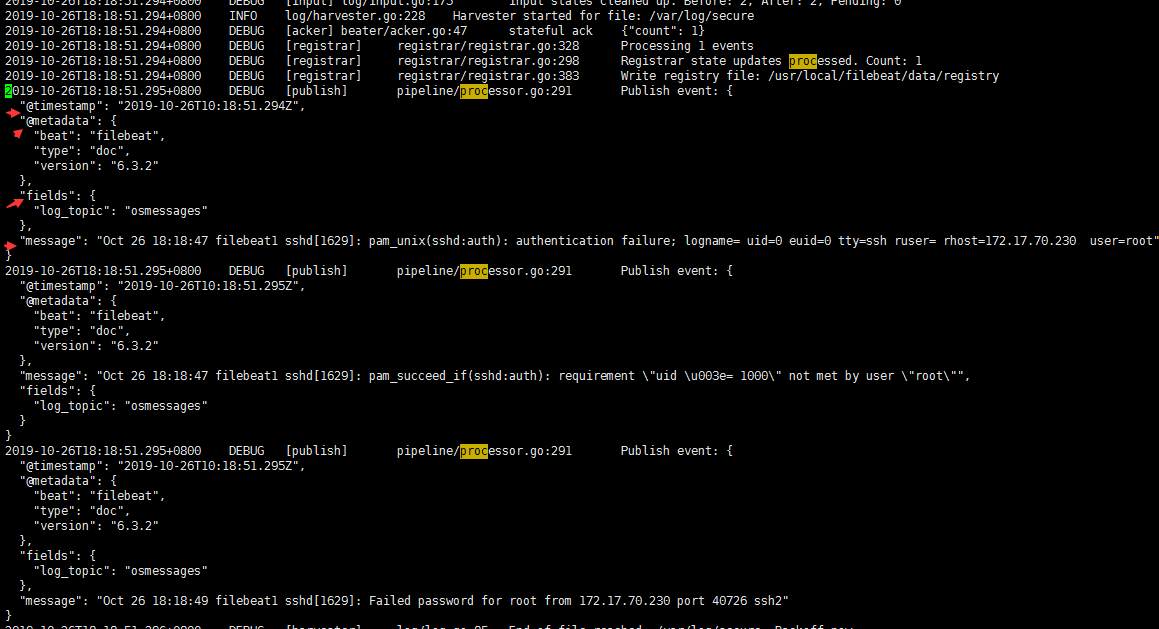
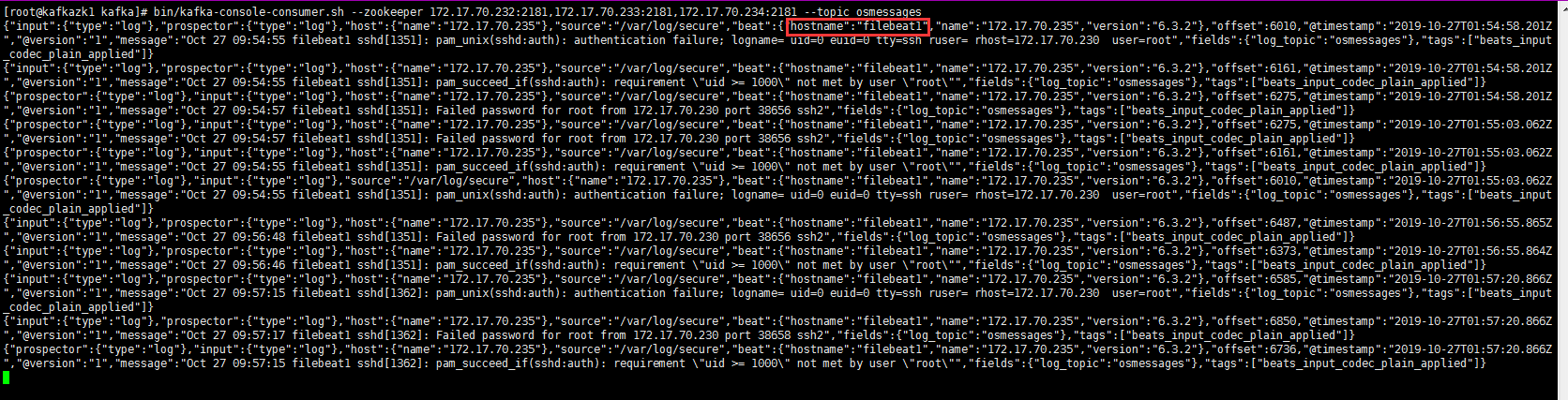
查看kafka集群有没有收到日志
登录到任意的kafka集群节点
消费topic osmessages就行
1 | # 先看看有没有创建 我们定义的topic |

1 | # 时间概念: |
安装并配置 Logstash 服务
下载与安装 Logstash
- 可以从elastic官网 https://www.elastic.co/downloads/logstash 获取logstash安装包,这里下载的版本是logstash-6.3.2.tar.gz。
- 将下载下来的安装包直接解压到一个路径下即可完成logstash的安装。根据前面的规划,
- 将logstash安装到logstash server主机上,这里统一将logstash安装到/usr/local目录下,基本操作过程如下:
1 | [root@filebeat1 ~]# mkdir -p /app/elk |
Logstash 是怎么工作的
Logstash是一个开源的、服务端的数据处理pipeline(管道),它可以接收多个源的数据、然后对它们进行转换、最终将它们发送到指定类型的目的地。
Logstash是通过 插件机制 实现各种功能的,可以在https://github.com/logstash-plugins 下载各种功能的插件,也可以自行编写插件。
Logstash实现的功能主要分为接收数据、解析过滤并转换数据、输出数据三个部分,对应的插件依次是input插件、filter插件、output插件,
其中,filter插件是可选的,其它两个是必须插件。也就是说在一个完整的Logstash配置文件中,必须有input插件和output插件。
1 | # 官方文档学习 |
常用的 input 插件
- input插件主要用于接收数据,Logstash支持接收多种数据源,常用的有如下几种:
- file:
- 读取一个文件,这个读取功能有点类似于linux下面的tail命令,一行一行的实时读取。
- syslog:
- 监听系统514端口的syslog messages,并使用RFC3164格式进行解析。
- redis:
- Logstash 可以从redis服务器读取数据,此时redis类似于一个消息缓存组件。
- kafka:
- Logstash 也可以从kafka集群中读取数据,kafka加Logstash的架构一般用在数据量较大的业务场景,kafka可用作数据的缓冲和存储。
- filebeat:
- filebeat是一个文本日志收集器,性能稳定,并且占用系统资源很少,Logstash可以接收filebeat发送过来的数据。
常用的 filter
- filter插件主要用于数据的过滤、解析和格式化,也就是将非结构化的数据解析成结构化的、可查询的标准化数据。常见的filter插件有如下几个:
- grok: 正则捕获
- grok是Logstash最重要的插件,可解析并结构化任意数据,支持正则表达式,并提供了很多内置的规则和模板可供使用。
- 使用最多,但也最复杂。
- mutate: 数据修改
- 提供了丰富的基础类型数据处理能力。包括类型转换,字符串处理和字段处理等。
- date:时间处理
- 可以用来转换你的日志记录中的时间字符串。
- GeoIP:地址查询
- 可以根据IP地址提供对应的地域信息,包括国别,省市,经纬度等,对于可视化地图和区域统计非常有用。
常用的 output
- output插件用于数据的输出,一个Logstash事件可以穿过多个output,直到所有的output处理完毕,这个事件才算结束。输出插件常见的有如下几种:
- elasticsearch:
- 发送数据到elasticsearch。
- file:
- 发送数据到文件中。
- redis:
- 发送数据到redis中,从这里可以看出,redis插件既可以用在input插件中,也可以用在output插件中。
- kafka:
- 发送数据到kafka中,与redis插件类似,此插件也可以用在Logstash的输入和输出插件中。
Logstash 配置文件入门
- /usr/local/logstash/config/, jvm.options是设置JVM内存资源的配置文件,logstash.yml是logstash全局属性配置文件,
- 另外还需要自己创建一个logstash事件配置文件,这里介绍下logstash事件配置文件的编写方法和使用方式。
- 在介绍Logstash配置之前,先来认识一下logstash是如何实现输入和输出的。
- Logstash提供了一个shell脚本/usr/local/logstash/bin/logstash,
- 可以方便快速的启动一个logstash进程,在Linux命令行下,运行如下命令启动Logstash进程:
1 | [root@logstash elk]# cd /usr/local/logstash/ |
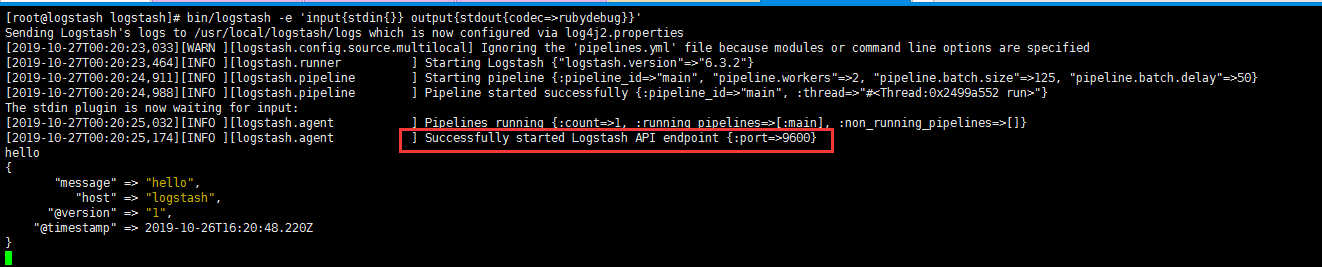
1 | 1. -e代表执行的意思。 |
1 | 1. 这就是logstash的输出格式。Logstash在输出内容中会给事件添加一些额外信息。 |
编写事件文件
- 在logstash的输出中,常见的字段还有type,表示事件的唯一类型,
- tags,表示事件的某方面属性,我们可以随意给事件添加字段或者从事件里删除字段。
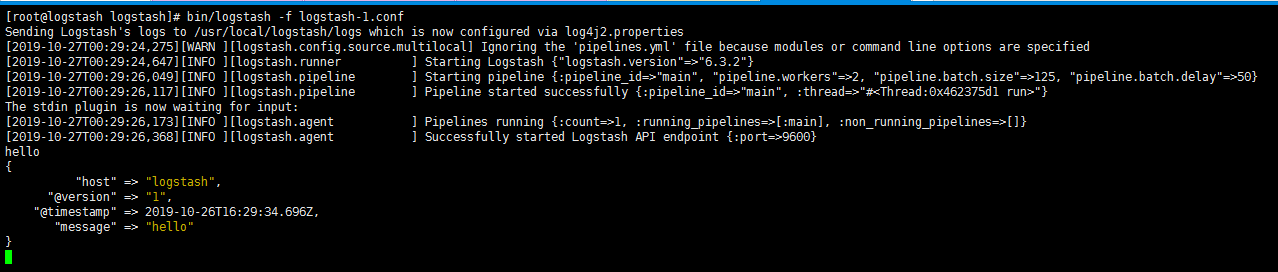
- 使用-e参数在命令行中指定配置是很常用的方式,但是如果logstash需要配置更多规则的话,就必须把配置固化到文件里,这就是logstash事件配置文件
- 如果把上面在命令行执行的logstash命令,写到一个配置文件logstash-1.conf中,就变成如下内容:
1 | [root@logstash logstash]# vim logstash-1.conf |
input 输入插件 file
- logstash启动后会去监控messages文件
1 | [root@logstash logstash]# vim logstash-1.conf |
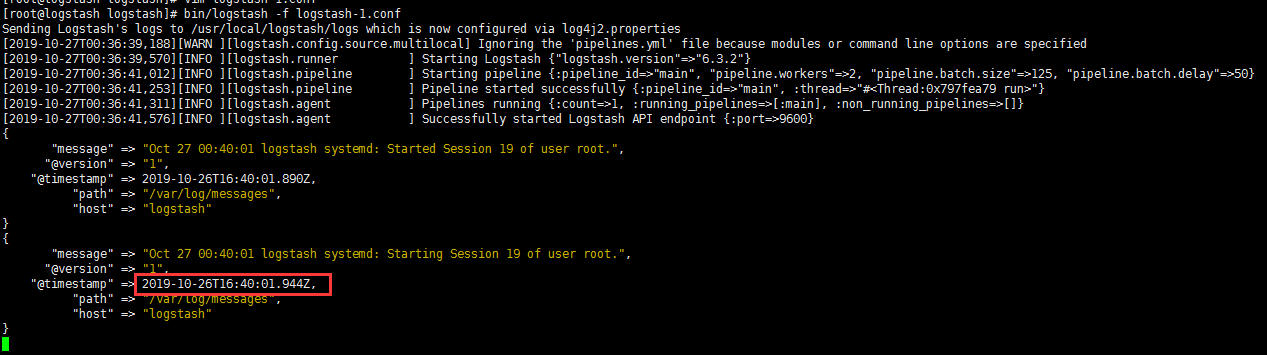
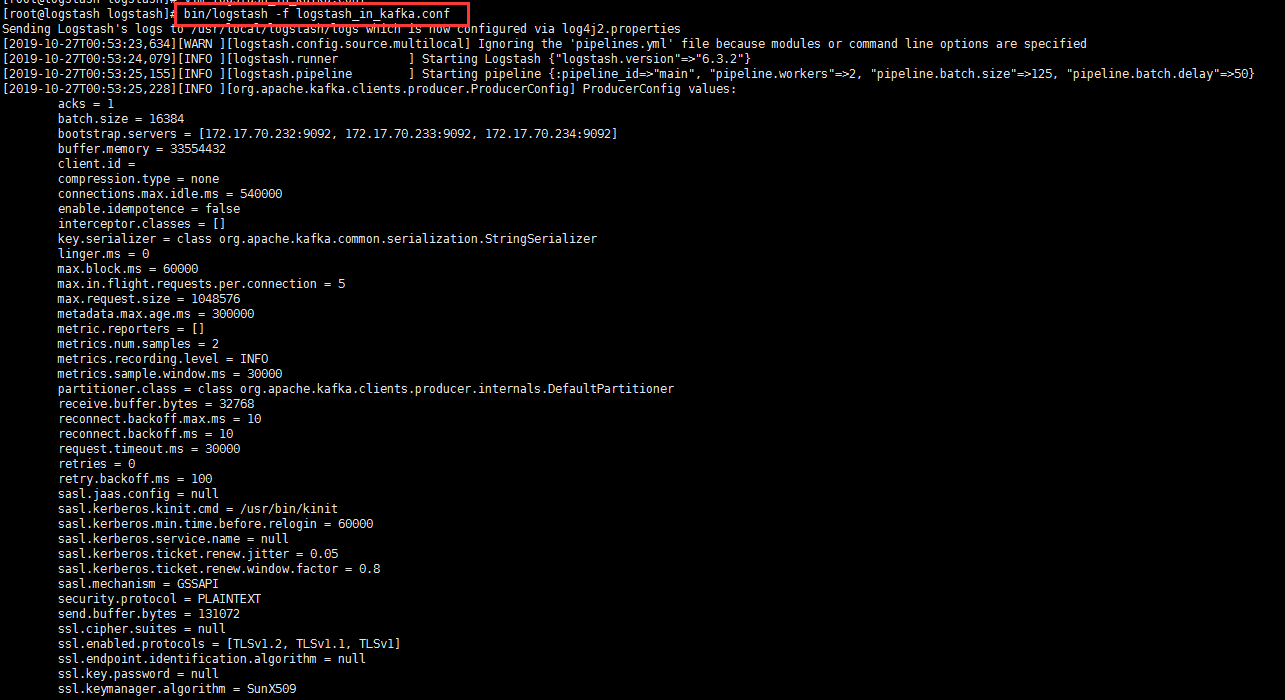
output 输出插件 输出到kafka
1 | [root@logstash logstash]# vim logstash_in_kafka.conf |
1 | 1. 这个配置文件中,输入input仍然是file,重点看输出插件,这里定义了output的输出源为kafka, |
1 | # kafka 消费数据 |


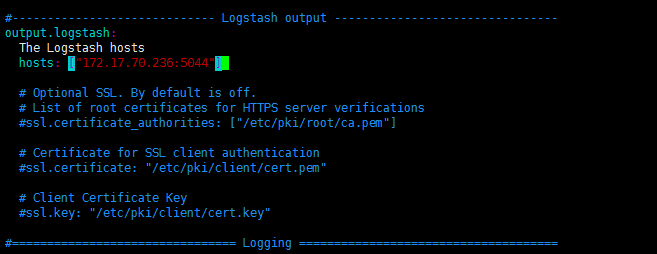
收集 filebeat端口发来的数据
1 | # 5044是接收端口,filebeat把数据发送到他的5044端口上,logstash收集 |

1 | # 配置filebeat |
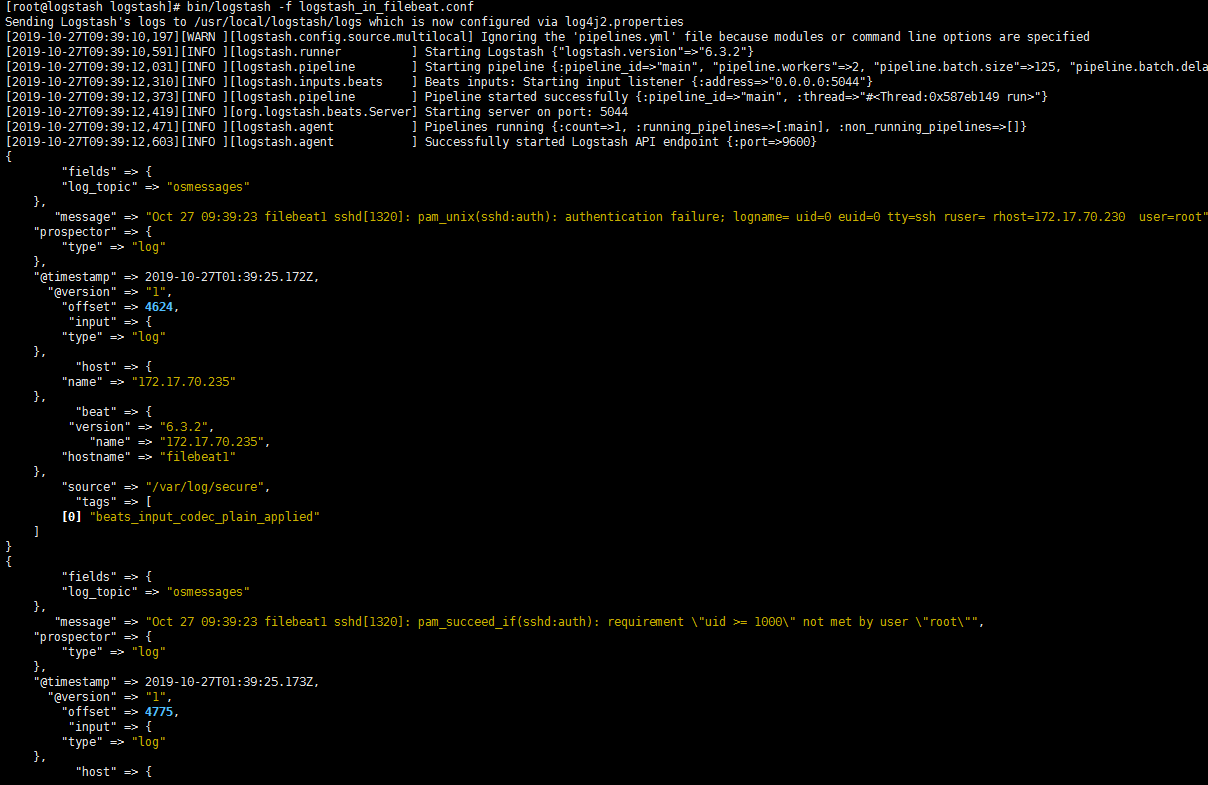
1 | # 把输出改成kafka |

配置logstash作为转发节点
- 上面对logstash的使用做了一个基础的介绍,现在回到本节介绍的这个案例中,在这个部署架构中,
- logstash是作为一个二级转发节点使用的,也就是它将kafka作为数据接收源,然后将数据发送到elasticsearch集群中,
- 按照这个需求,新建logstash事件配置文件 kafka_os_into_es.conf,内容如下:
1 | [root@logstash logstash]# vim kafka_os_into_es.conf |
1 | # 注意 |

安装并配置Kibana展示日志数据
下载与安装Kibana
kibana使用Node.js(JavaScript)语言编写,安装部署十分简单,即下即用,可以从elastic官网https://www.elastic.co/cn/downloads/kibana 下载所需的版本,
这里需要注意的是Kibana与Elasticsearch的版本必须一致,另外,在安装Kibana时,要确保Elasticsearch、Logstash和kafka已经安装完毕。
这里安装的版本是kibana-6.3.2-linux-x86_64.tar.gz。将下载下来的安装包直接解压到一个路径下即可完成kibana的安装,根据前面的规划,
将kibana安装到server2主机上,然后统一将kibana安装到/usr/local目录下,基本操作过程如下:
1 | [root@server2 elk]# tar -zxvf kibana-6.3.2-linux-x86_64.tar.gz -C /usr/local |
配置 Kibana
由于将Kibana安装到了/usr/local目录下,因此,Kibana的配置文件为/usr/local/kibana/config/kibana.yml,
Kibana 配置非常简单,这里仅列出常用的配置项,内容如下:
1 | [root@server2 kibana]# vim /usr/local/kibana/config/kibana.yml |
- 每个配置项的含义介绍如下
- 阿里云服务器 用公网地址 开访问端口 5601
- server.port:
- kibana绑定的监听端口,默认是5601。
- server.host:
- kibana绑定的IP地址,如果内网访问,设置为内网地址即可。
- elasticsearch.url:
- kibana访问ElasticSearch的地址,如果是ElasticSearch集群,添加任一集群节点IP即可,
- 官方推荐是设置为ElasticSearch集群中client node角色的节点IP。
- kibana.index:
- 用于存储kibana数据信息的索引,这个可以在kibanaweb界面中看到。
启动Kibana服务与web配置
- 启动kibana服务的命令在/usr/local/kibana/bin目录下,执行如下命令启动kibana服务:
1 | [root@server2 kibana]# cd /usr/local/kibana/ |
创建索引
1 | 之前我们在 logstash定义了 这个索引 |
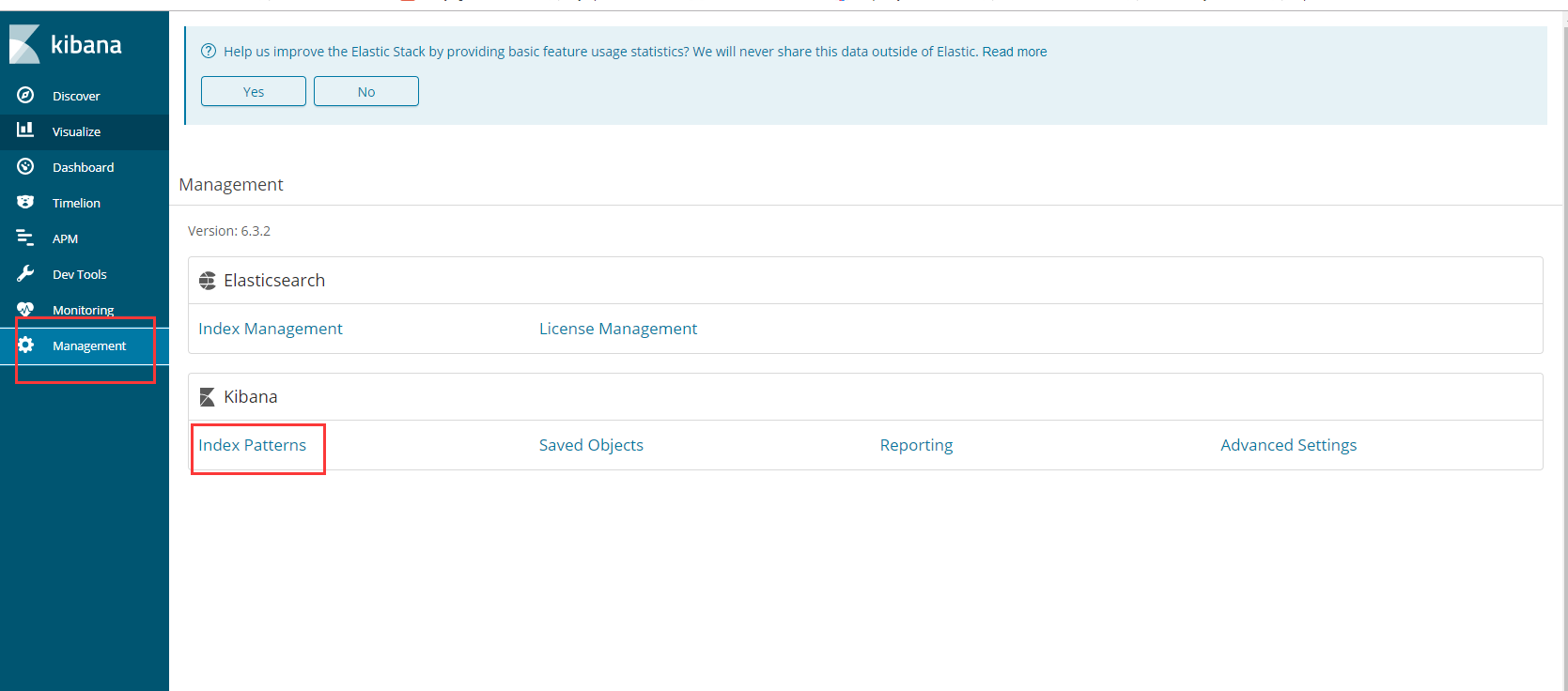
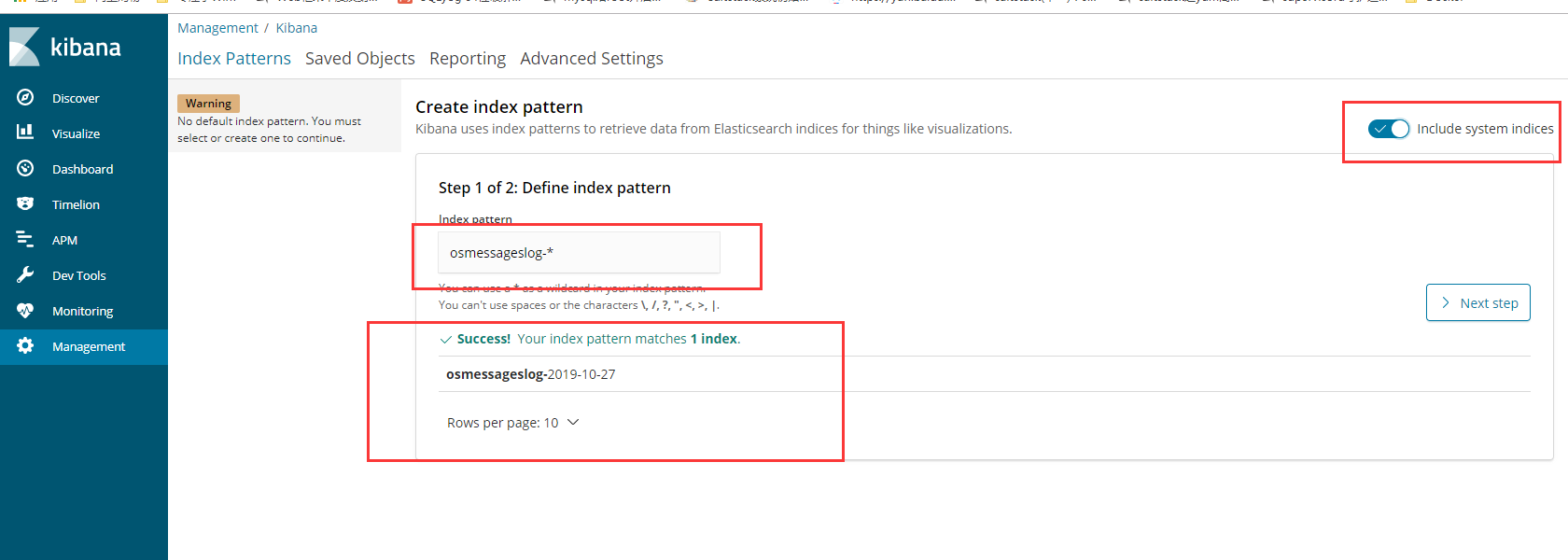
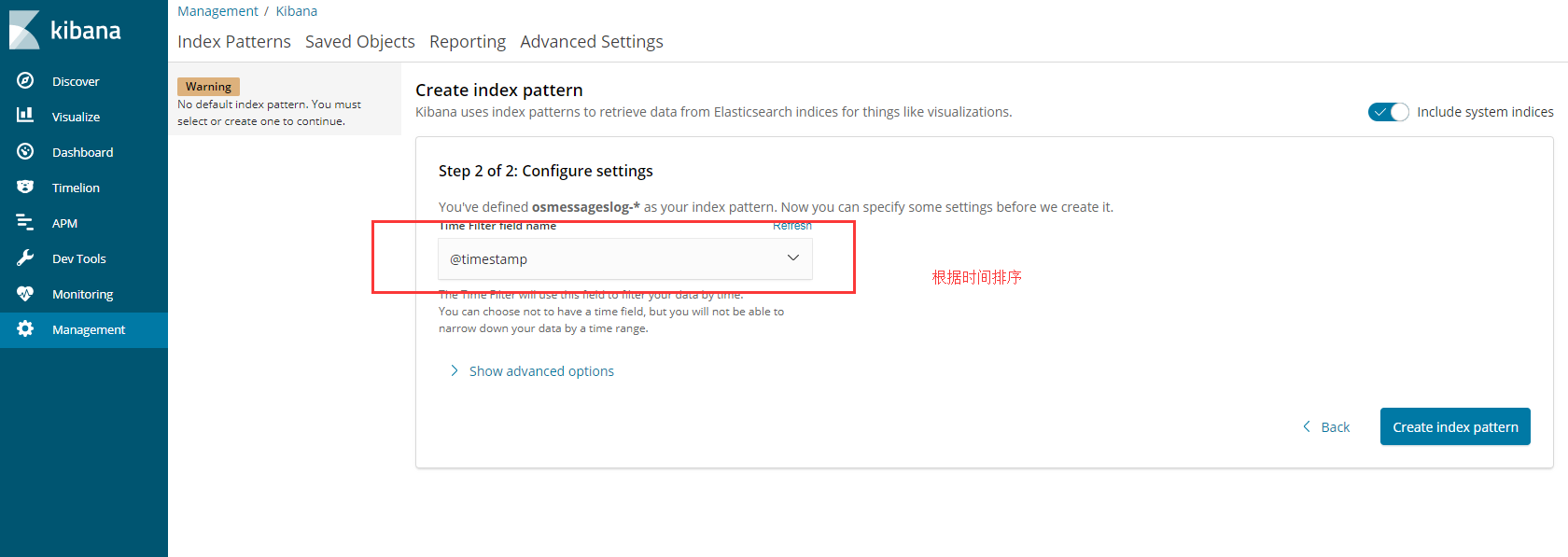
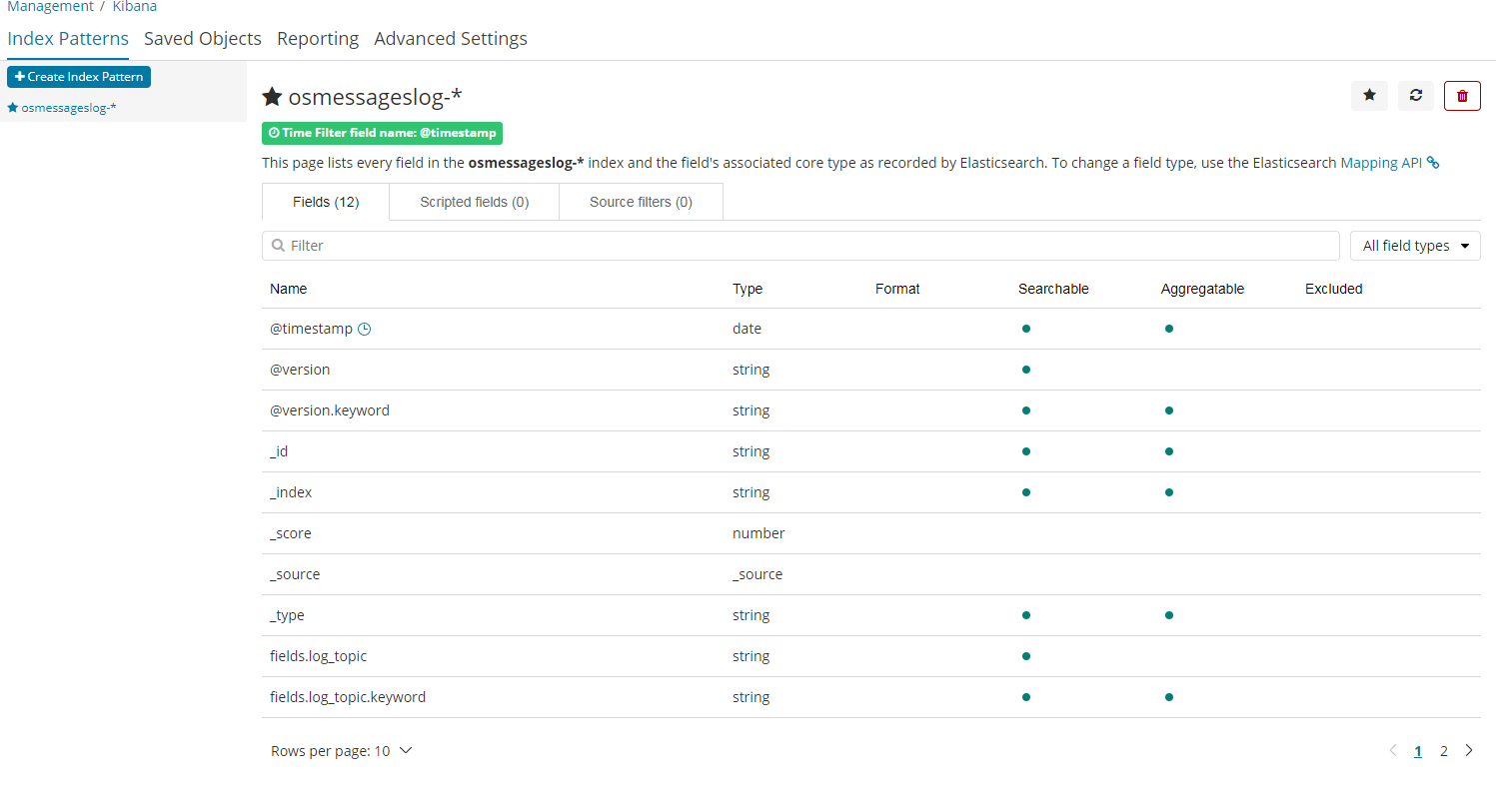
查看数据
1 | 以后不用再去每台服务器查看日志 |
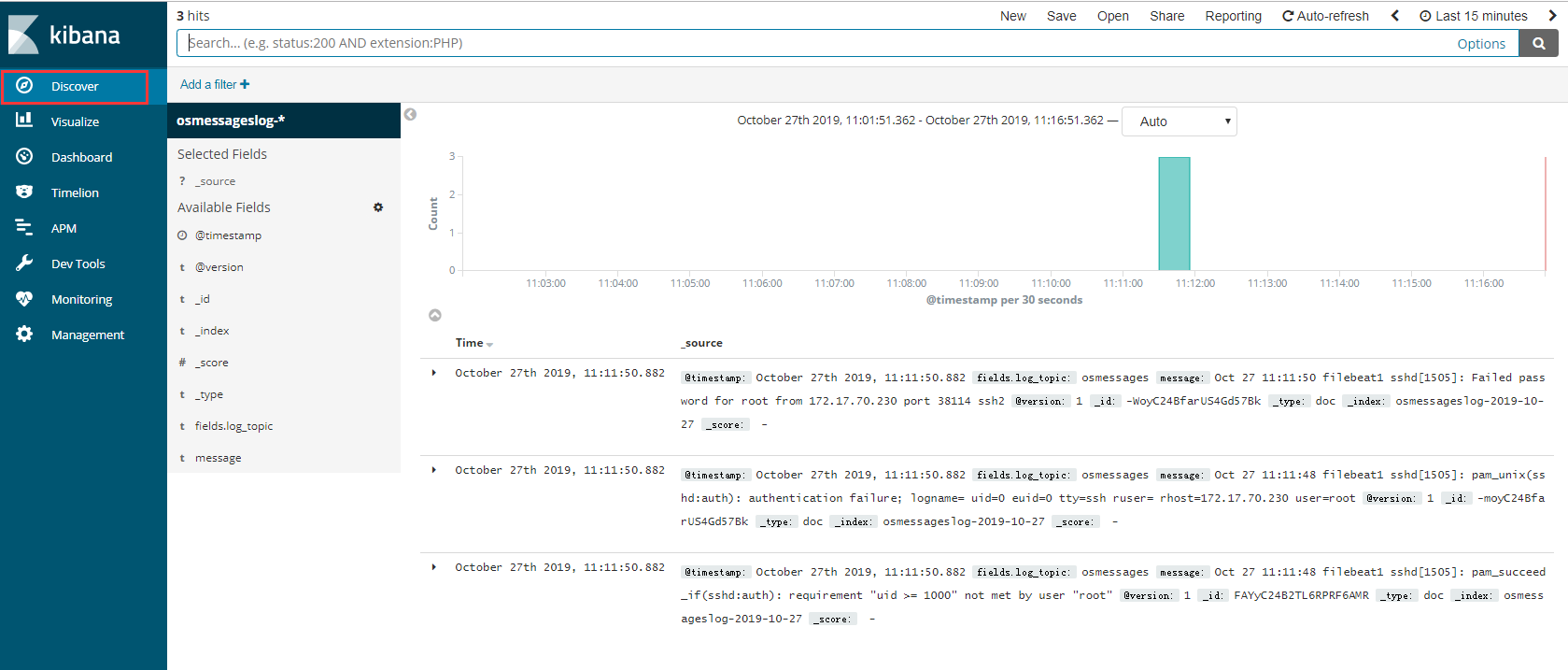
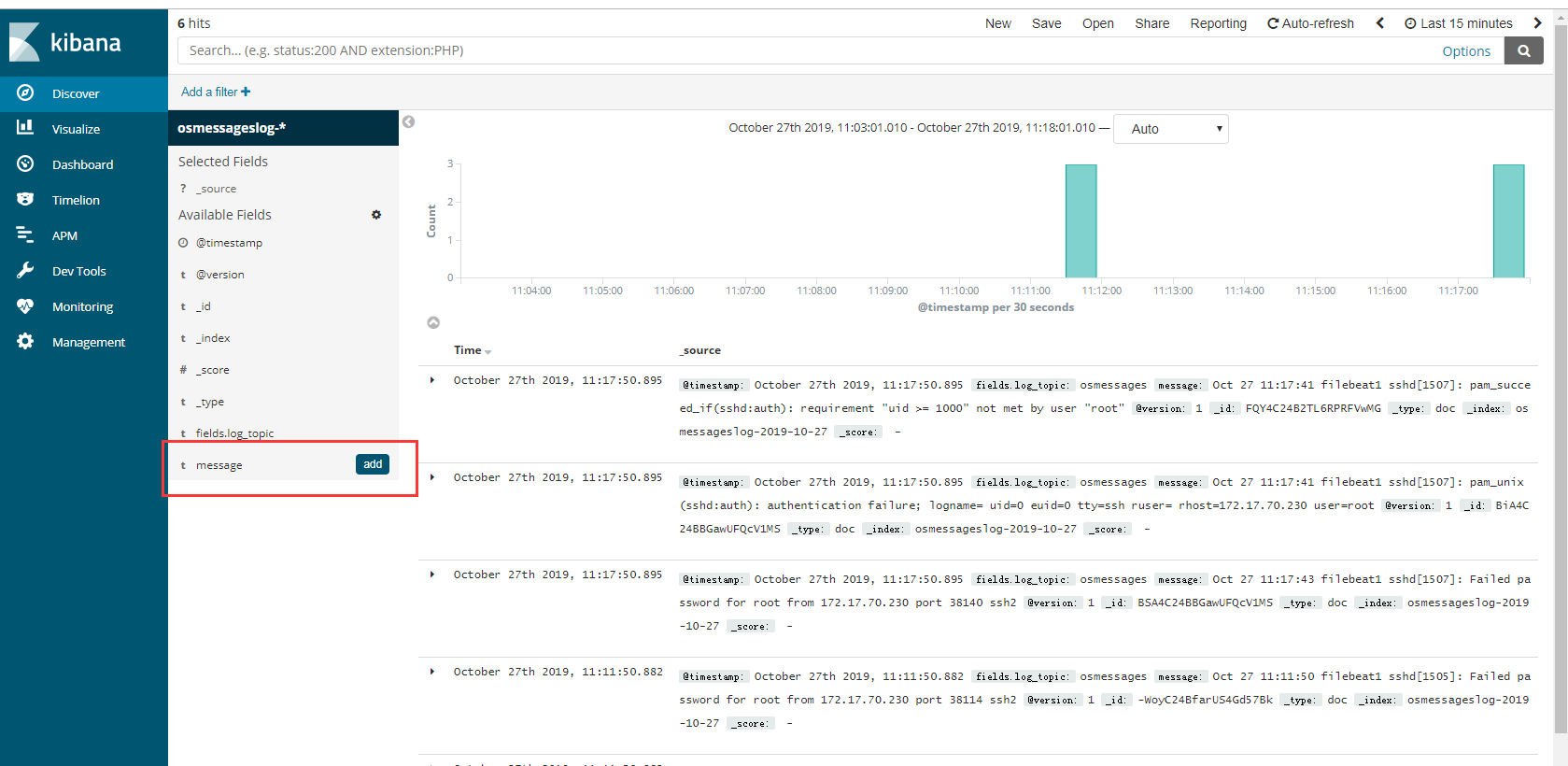
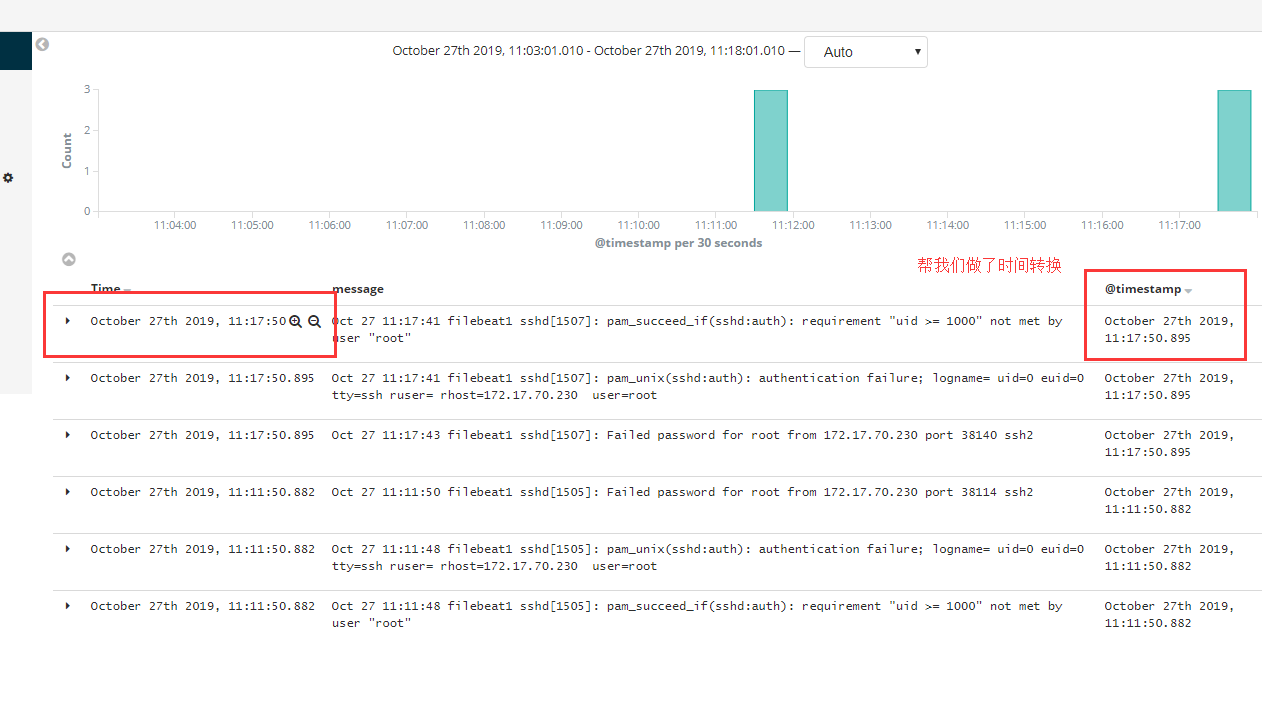
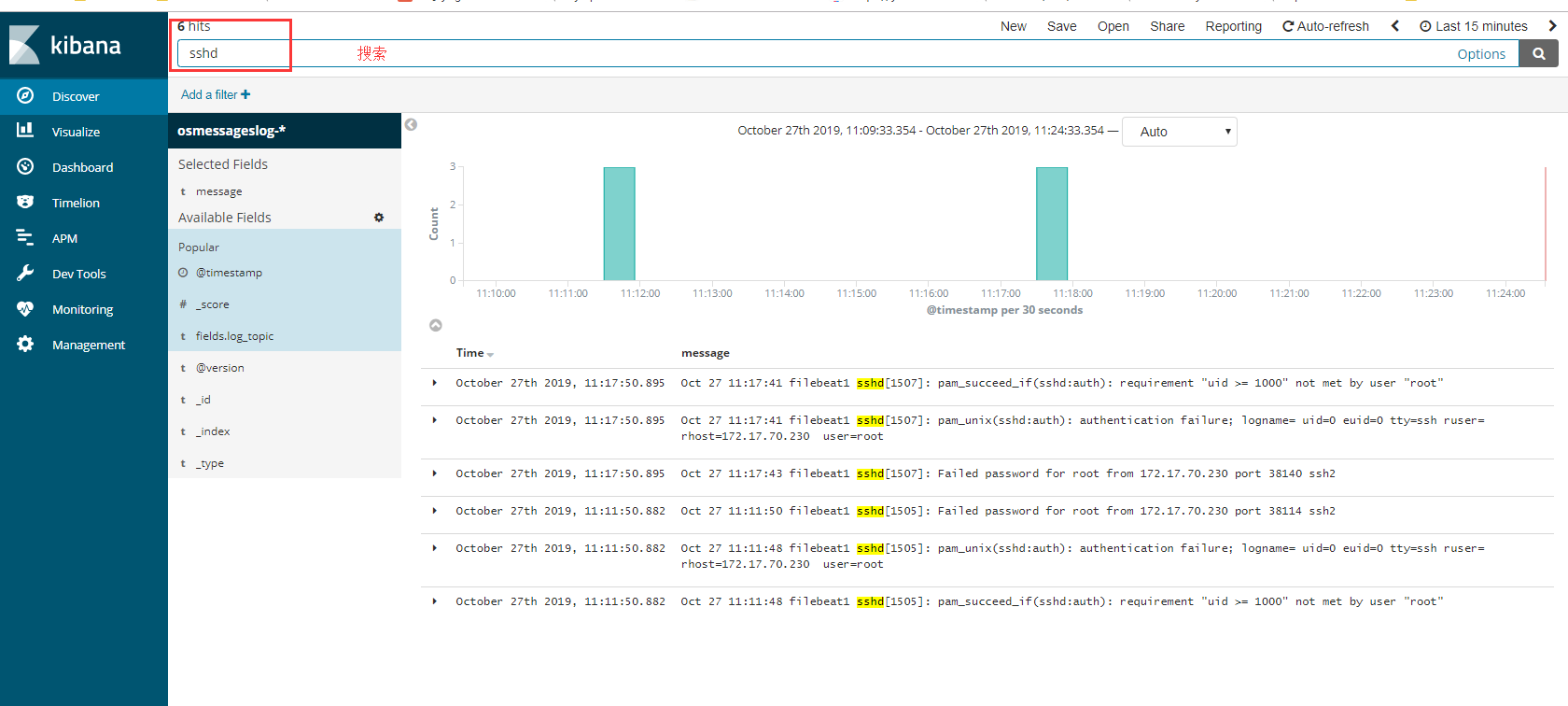
1 | 自定义 按照字段搜索 |
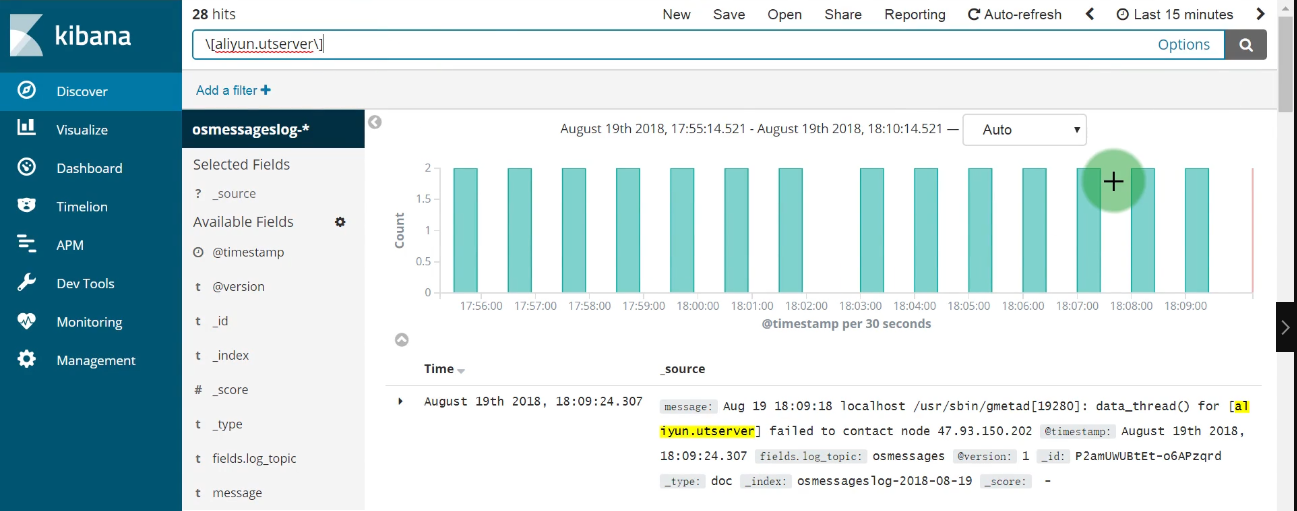
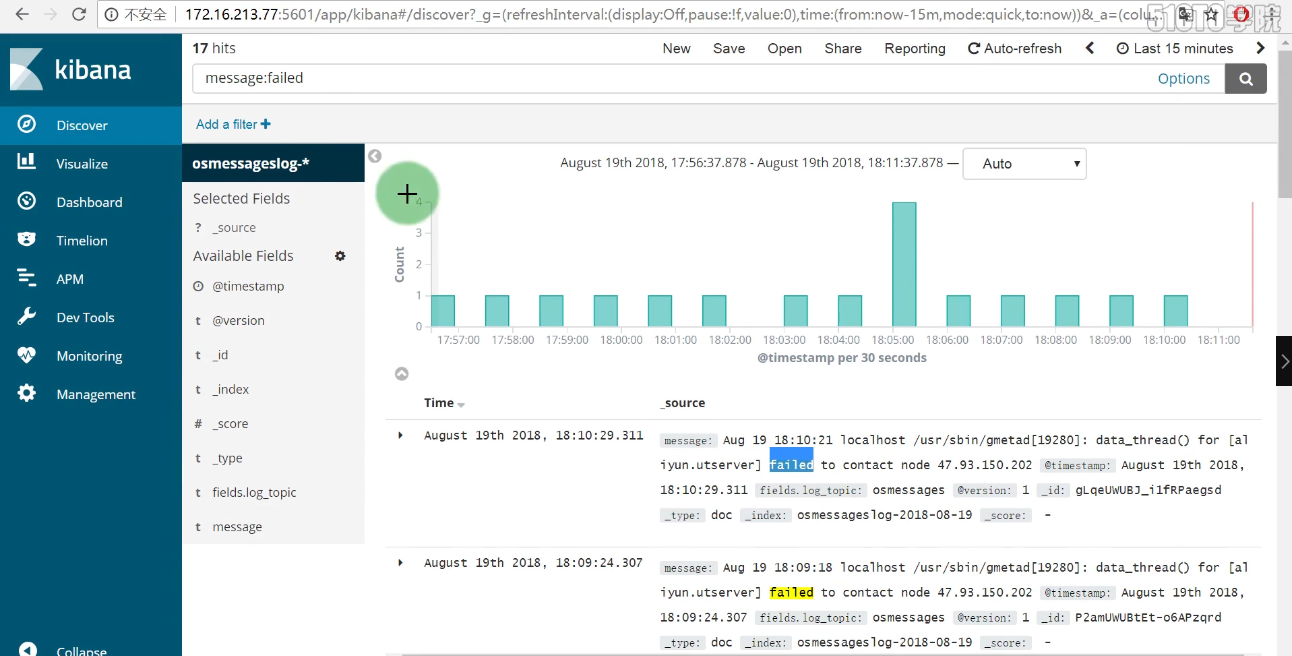
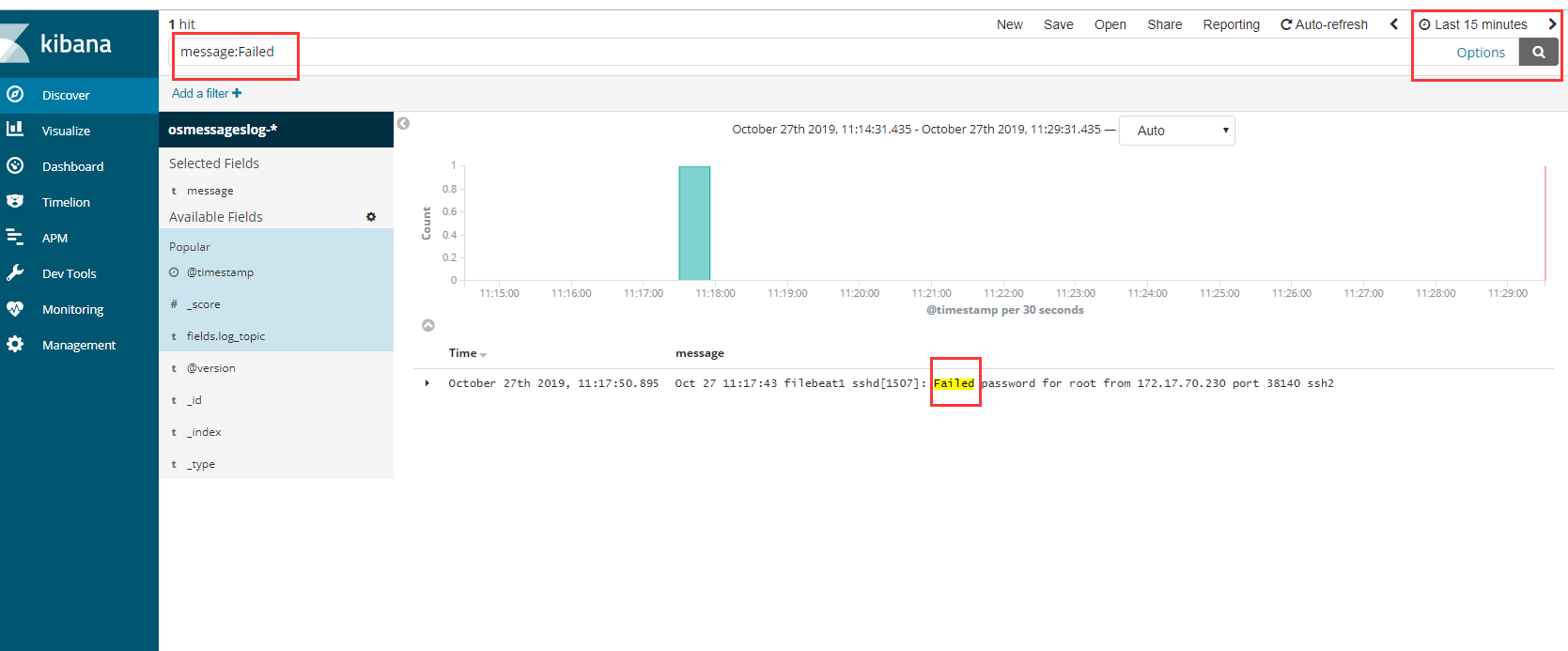
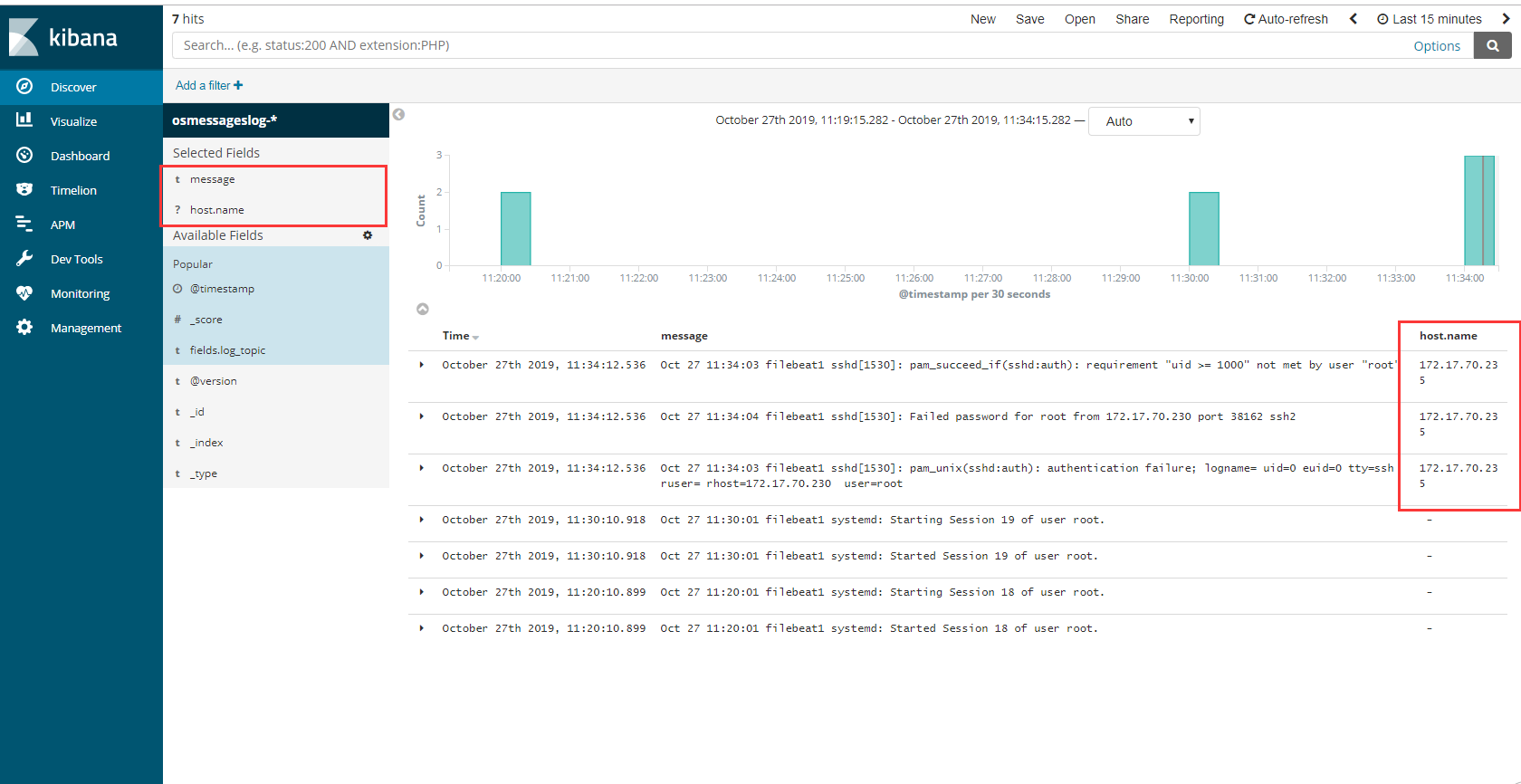
1 | # 收集的字段与我们filebeat 过滤的字段 息息相关 如果加上host 就可以知道来自哪台服务器,添加上就有了 |
修改filebeat的过滤

1 | [root@filebeat1 filebeat]# kill -9 `pgrep -f filebeat` |

调试并验证日志数据流向
- 经过上面的配置过程,大数据日志分析平台已经基本构建完成,由于整个配置架构比较复杂,这里来梳理下各个功能模块的数据和业务流向。