
Logstash基本语法组成
- logstash之所以功能强大和流行,还与其丰富的过滤器插件是分不开的,过滤器提供的并不单单是过滤的功能,
- 还可以对进入过滤器的原始数据进行复杂的逻辑处理,甚至添加独特的事件到后续流程中。
- Logstash配置文件有如下三部分组成,其中input、output部分是必须配置,
- filter部分是可选配置,而filter就是过滤器插件,可以在这部分实现各种日志过滤功能。
1 | input { |
Logstash 输入插件(Input)
读取文件(File)
- logstash使用一个名为filewatch的ruby gem库来监听文件变化,并通过一个叫.sincedb的数据库文件来记录被监听的日志文件的读取进度(时间戳),
- 这个sincedb数据文件的默认路径在 <path.data>/plugins/inputs/file下面,
- 文件名类似于.sincedb_452905a167cf4509fd08acb964fdb20c,
- 而<path.data>表示logstash插件存储目录,默认是LOGSTASH_HOME/data。
1 | input { |
- 这个配置是监听并接收本机的/var/log/messages文件内容,
- start_position表示按时间戳记录的地方开始读取,如果没有时间戳则从头开始读取,有点类似cat命令,
- 默认情况下,logstash会从文件的结束位置开始读取数据,也就是说logstash进程会以类似tail -f命令的形式逐行获取数据。
- type用来标记事件类型,通常会在输入区域通过type标记事件类型。
1 | 看业务需求,是否需要重新读取日志中所有内容,需要就加上 start_position => "beginning" |
标准输入(Stdin)
- stdin是从标准输入获取信息
1 | input{ |
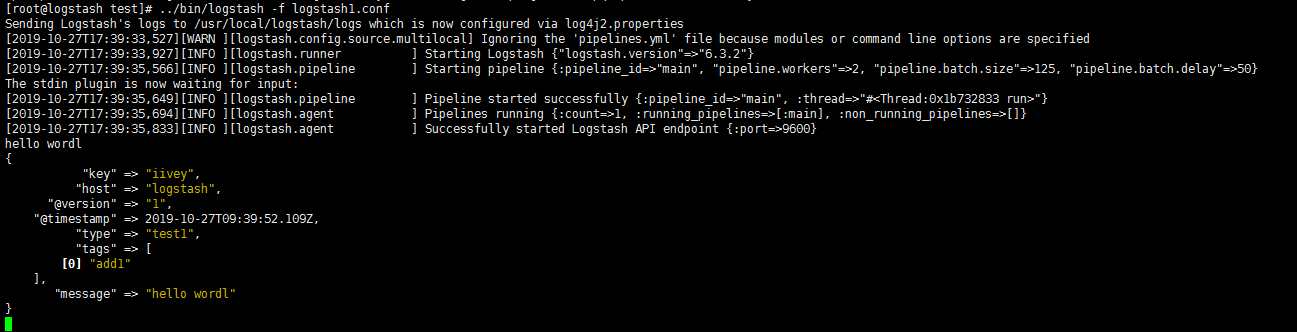
读取 Syslog日志
6.0版本叫做rsyslog
如何将rsyslog收集到的日志信息发送到logstash中,这里以centos7.5为例,需要做如下两个步骤的操作:
首先,在 需要收集日志 的 服务器 上找到rsyslog的配置文件/etc/rsyslog.conf,添加如下内容:
1 | *.* @@172.16.213.120:5514 |
其中,172.16.213.120是logstash服务器的地址。5514是logstash启动的监听端口。
接着,重启rsyslog服务:
然后,在logstash服务器上创建一个事件配置文件,内容如下:
1 | input { |

1 | # 去要收集的服务器上配置 |
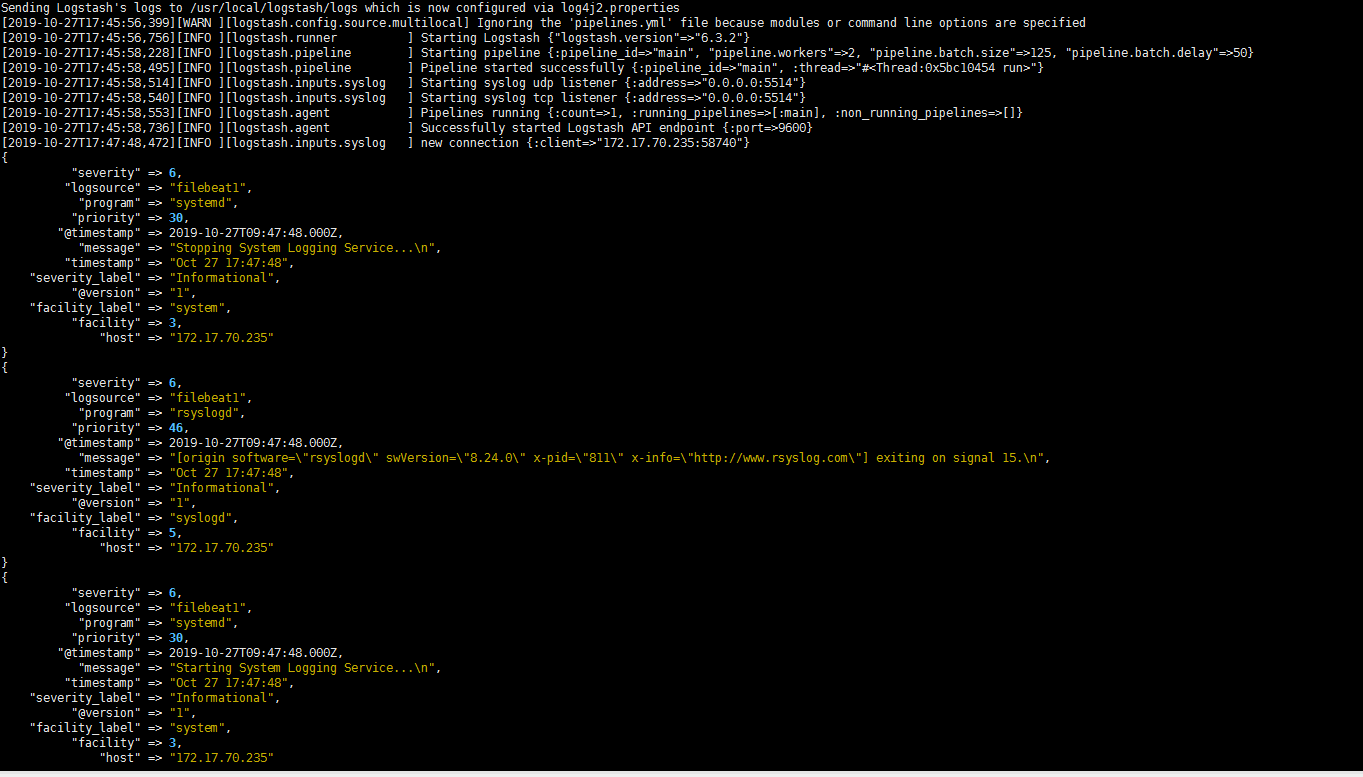
读取TCP网络数据
- 下面的事件配置文件就是通过”LogStash::Inputs::TCP”和”LogStash::Filters::Grok”配合实现syslog功能的例子,
- 这里使用了logstash的TCP/UDP插件读取网络数据:
- grok 正则抓取
1 | input { |

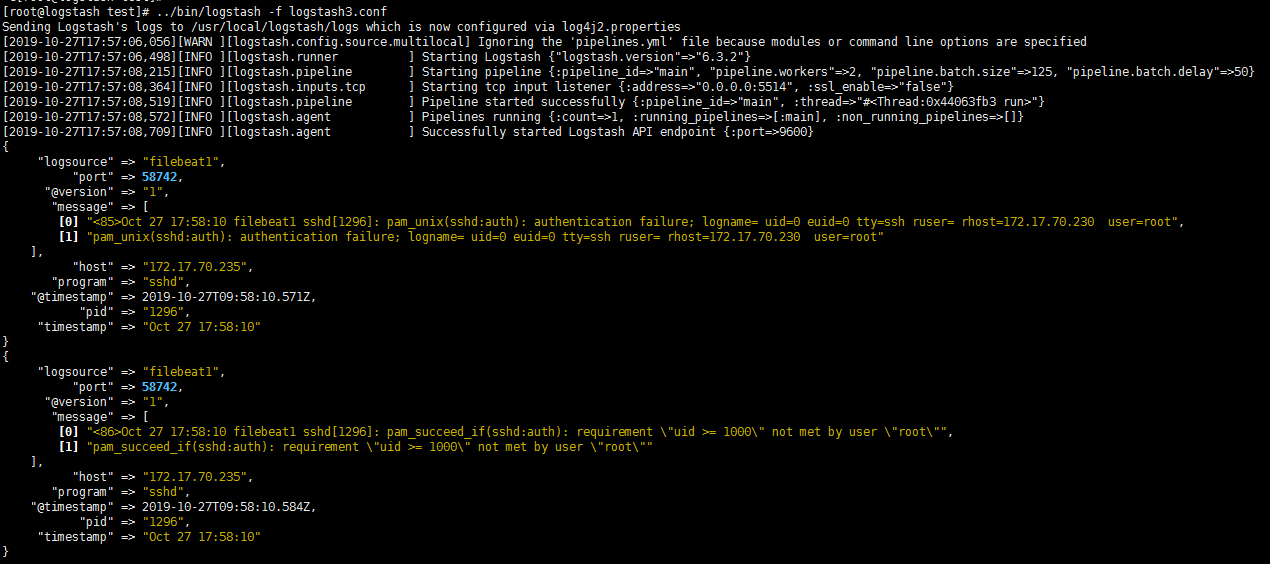
Logstash 编码插件(Codec)
- 其实我们就已经用过编码插件codec了,也就是这个rubydebug,它就是一种codec,虽然它一般只会用在stdout插件中,作为配置测试或者调试的工具。
- 编码插件(Codec)可以在logstash输入或输出时处理不同类型的数据,
- 因此,Logstash不只是一个input–>filter–>output的数据流,而是一个input–>decode–>filter–>encode–>output的数据流。
- Codec支持的编码格式常见的有plain、json、json_lines等。下面依次介绍。
codec插件之 plain
- plain是一个空的解析器,它可以让用户自己指定格式,也就是说输入是什么格式,输出就是什么格式。
- 下面是一个包含plain编码的事件配置文件:
1 | input{ |

codec插件之 json、json_lines
- 如果发送给logstash的数据内容为json格式,可以在input字段加入codec=>json来进行解析,这样就可以根据具体内容生成字段,方便分析和储存。
- 如果想让logstash输出为json格式,可以在output字段加入codec=>json,下面是一个包含json编码的事件配置文件:
- json每个字段是key:values格式,多个字段之间通过逗号分隔。有时候,如果json文件比较长,需要换行的话,那么就要用json_lines编码格式了。
- 数据分析 大多数使用json格式
- 数据非常大需要换行,就改成json_lines
1 | input { |

Logstash 过滤器插件(Filter)
- filter插件对字段的分割、转换和赋值
Grok 正则捕获
- grok是一个十分强大的logstash filter插件,他可以通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。
- 他是目前logstash 中解析非结构化日志数据最好的方式。
Grok 的语法规则是:
- %{语法: 语义}
“语法”指的就是匹配的模式,例如使用NUMBER模式可以匹配出数字,IP模式则会匹配出127.0.0.1这样的IP地址:
- 例如输入的内容为:
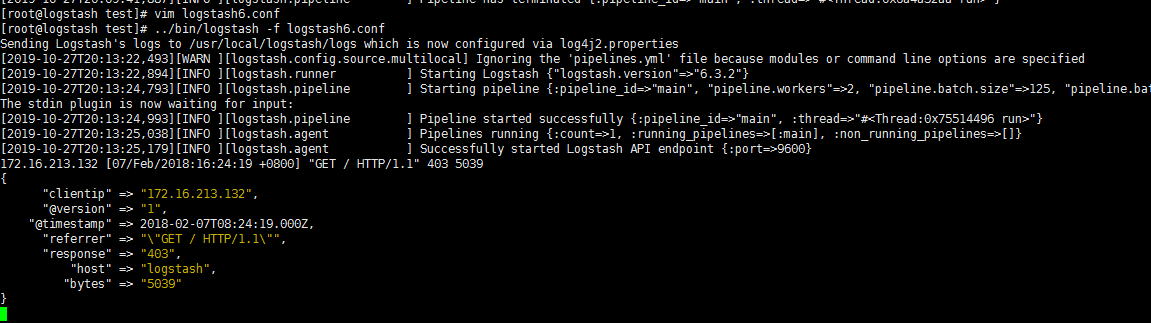
- 172.16.213.132 [07/Feb/2018:16:24:19 +0800] “GET / HTTP/1.1” 403 5039
1 | %{IP:clientip}匹配模式将获得的结果为: clientip: 172.16.213.132 |
- 匹配规则方法路径查看
1 | # 匹配模式 |
调试grok正则表达式工具:
- 实际使用过滤先通过调试工具获取方法
1 | http://grokdebug.herokuapp.com |
1 | 172.16.213.132 [07/Feb/2018:16:24:19 +0800] "GET / HTTP/1.1" 403 5039 |
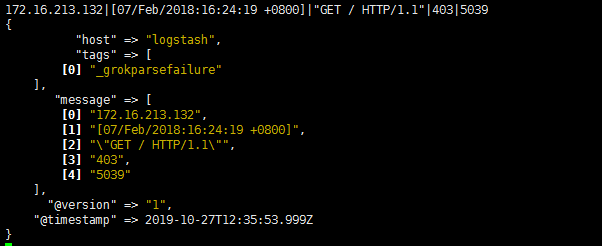
- 通过上面这个组合匹配模式,我们将输入的内容分成了五个部分,即五个字段,
- 将输入内容分割为不同的数据字段,这对于日后解析和查询日志数据非常有用,这正是使用grok的目的。
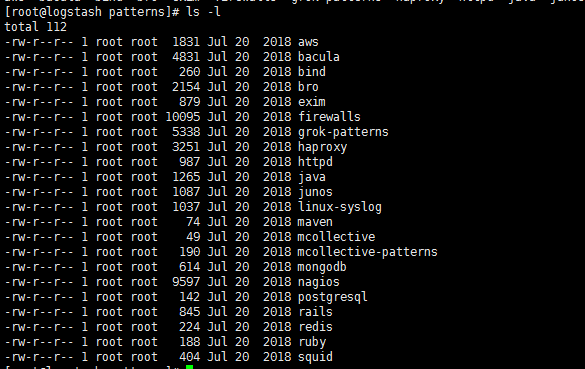
- Logstash默认提供了近200个匹配模式(其实就是定义好的正则表达式)让我们来使用,可以在logstash安装目录下,
- 例如这里是/usr/local/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.2/patterns目录里面查看,
- 基本定义在grok-patterns文件中。
1 | # 从这些定义好的匹配模式中,可以查到上面使用的四个匹配模式对应的定义规则 |
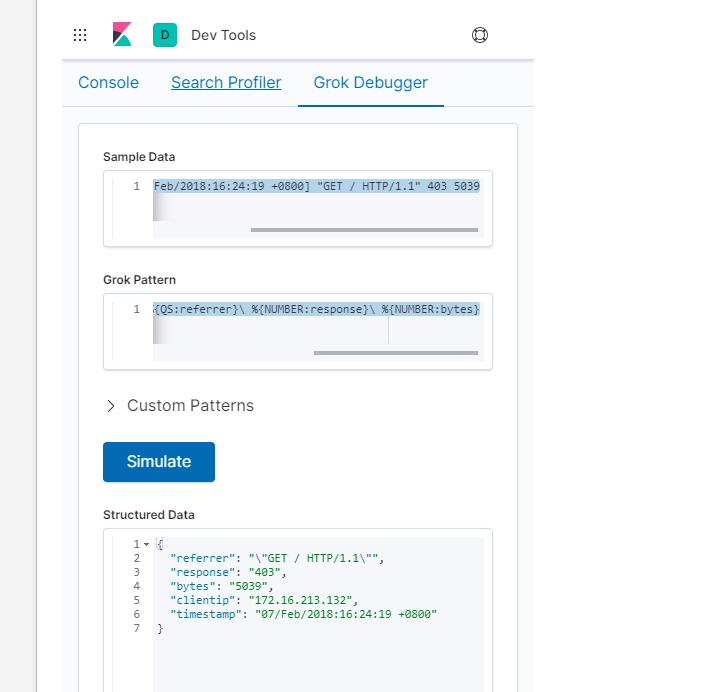
使用 Grok 正则捕获
1 | [root@logstash test]# vim logstash6.conf |
1 | [root@logstash test]# ../bin/logstash -f logstash6.conf |
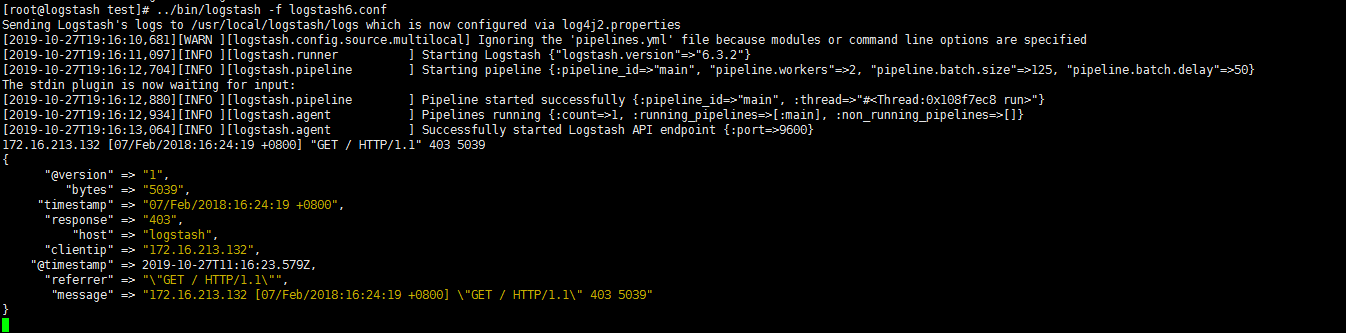
进一步过滤 messages
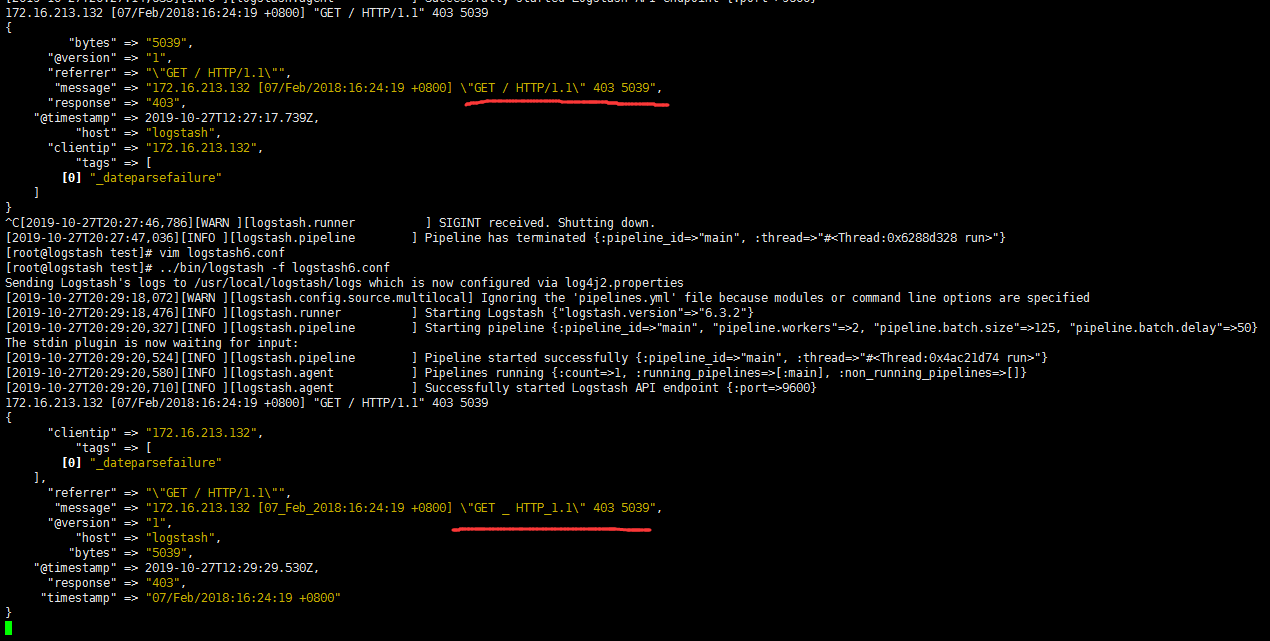
- 既然已经把messages字段过滤分割5段,那么已经不需要messages整体这个字段了,需要把它删除
- 两个时间字段 日志收集时间和日志产生时间 不一致,主要是我们在后面展示的时候,只想展示 日志的产生时间,需要替换赋值
- 我们自己定义的时间字段也可删除,需要放在赋值之后,要不然赋值没了
1 | remove_field => ["message"] 删除字段中的某一列 |
1 | [root@logstash test]# vim logstash6.conf |
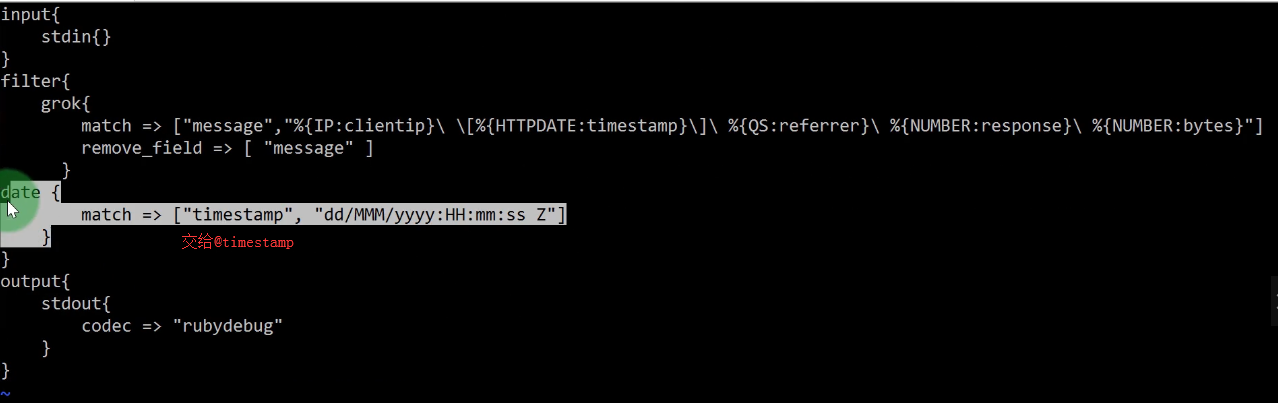
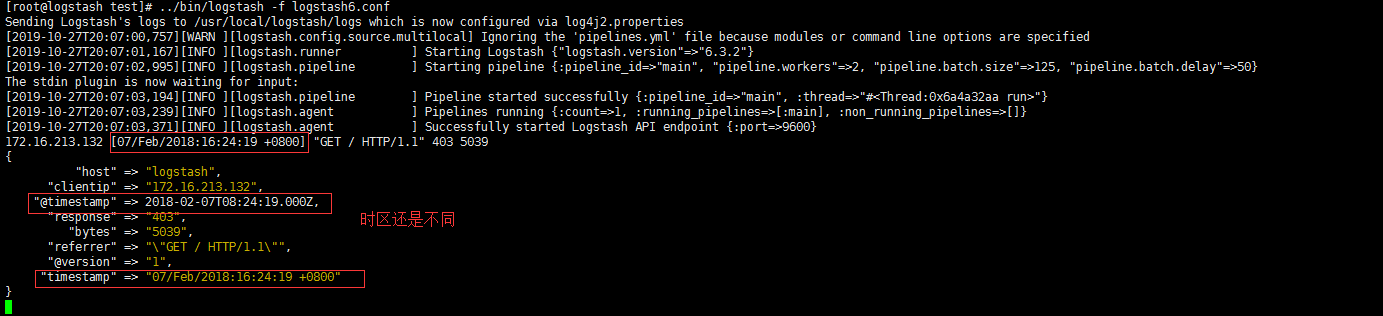
1 | [root@logstash test]# vim logstash6.conf |
时间处理 (Date)
- date插件是对于排序事件和回填旧数据尤其重要,它可以用来转换日志记录中的时间字段,变成LogStash::Timestamp对象,
- 然后转存到@timestamp字段里,这在之前已经做过简单的介绍。
1 | filter { |

数据修改 (Mutate)
gsup 正则表达式替换匹配字段
- gsub可以通过正则表达式替换字段中匹配到的值,只对字符串字段有效
1 | # filed_name_1 是要替换的字段名 |
1 | [root@logstash test]# vim logstash6.conf |
split 分隔符分割字符串为数组
- split可以通过指定的分隔符分割字段中的字符串为数组
1 | # 将filed_name_2字段以"|"为区间分隔为数组。 |
1 | [root@logstash test]# vim logstash6.conf |
rename 重命名字段
- rename可以实现重命名某个字段的功能
1 | # 这个示例表示将字段old_field重命名为new_field。 |
1 | [root@logstash test]# vim logstash6.conf |
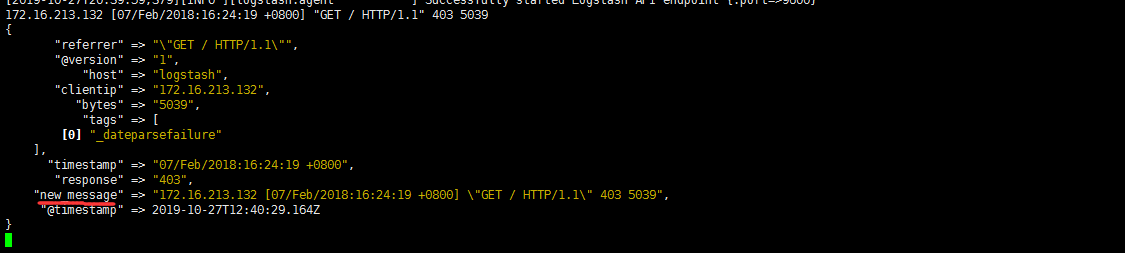
remove_field 删除字段
- remove_field可以实现删除某个字段的功能
1 | # 将字段timestamp删除 |
数据修改(Mutate) 完整示例
1 | # gsub => ["referrer","\"",""] |
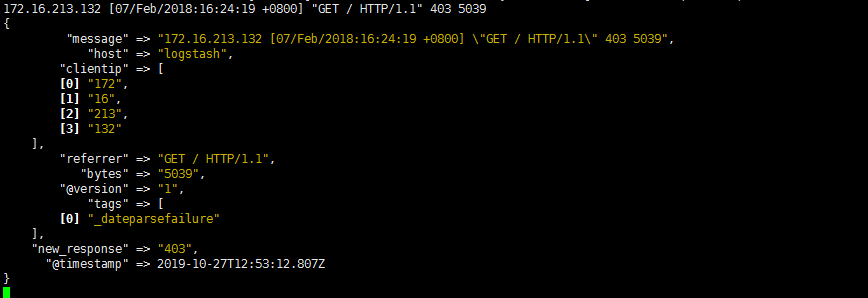
GeoIP 地址查询归类
- GeoIP是最常见的免费IP地址归类查询库,当然也有收费版可以使用。
- GeoIP库可以根据IP 地址提供对应的地域信息,包括国别,省市,经纬度等,此插件对于可视化地图和区域统计非常有用。
- 下面是一个关于GeoIP插件的简单示例(仅列出filter部分)::
1 | # 其中,ip_field字段是输出IP地址的一个字段。 |
1 | [root@logstash test]# vim logstash6.conf |
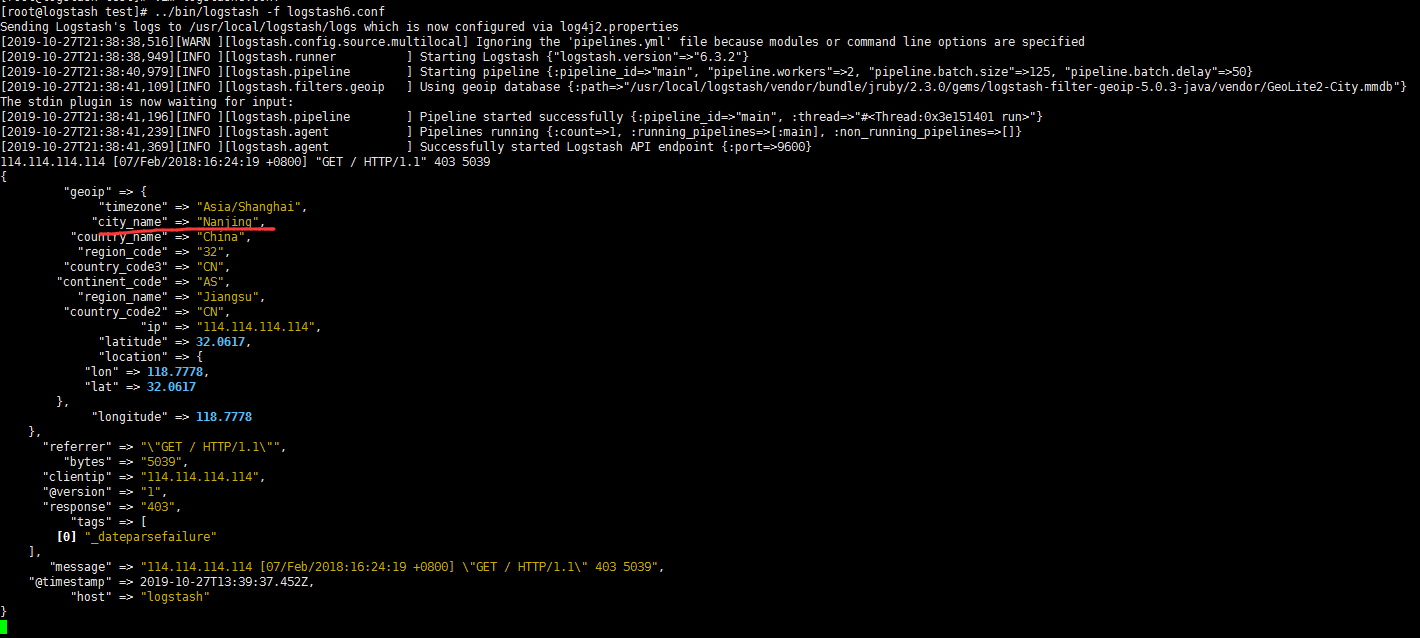
1 | # 精简 经度 纬度 时区 |
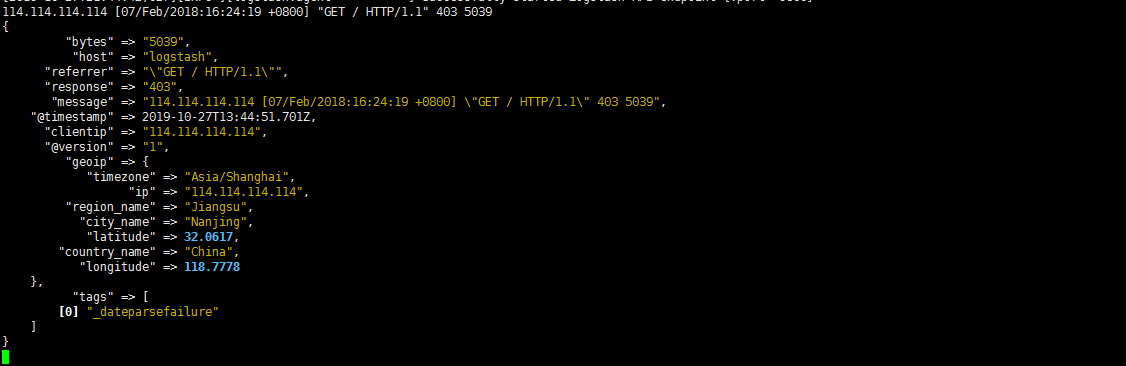
filter插件综合应用实例
- 下面给出一个业务系统输出的日志格式,由于业务系统输出的日志格式无法更改,
- 因此就需要我们通过logstash的filter过滤功能以及grok插件来获取需要的数据格式,
- 此业务系统输出的日志内容以及原始格式如下:
1 | 2018-02-09T10:57:42+08:00|~|123.87.240.97|~|Mozilla/5.0 (iPhone; CPU iPhone OS 11_2_2 like Mac OS X) AppleWebKit/604.4.7 Version/11.0 Mobile/15C202 Safari/604.1|~|http://m.sina.cn/cm/ads_ck_wap.html|~|1460709836200|~|DF0184266887D0E |
1 | # 分析 先看什么分割的 |
内容分割
1 | # 把内容分成了6个字段 |
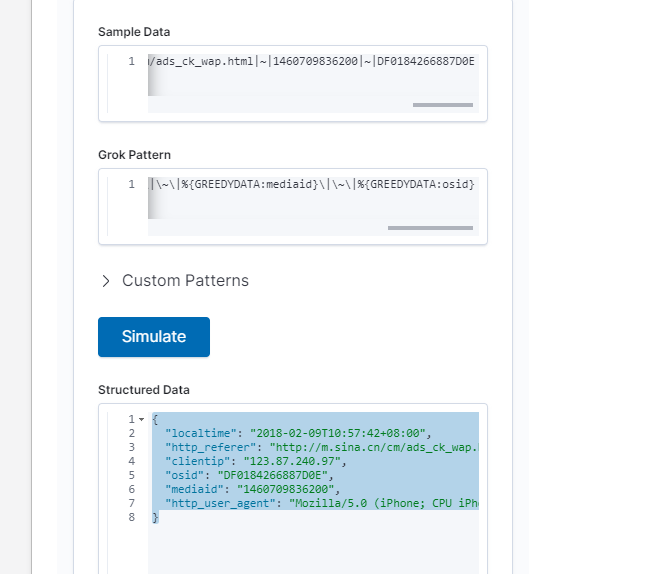
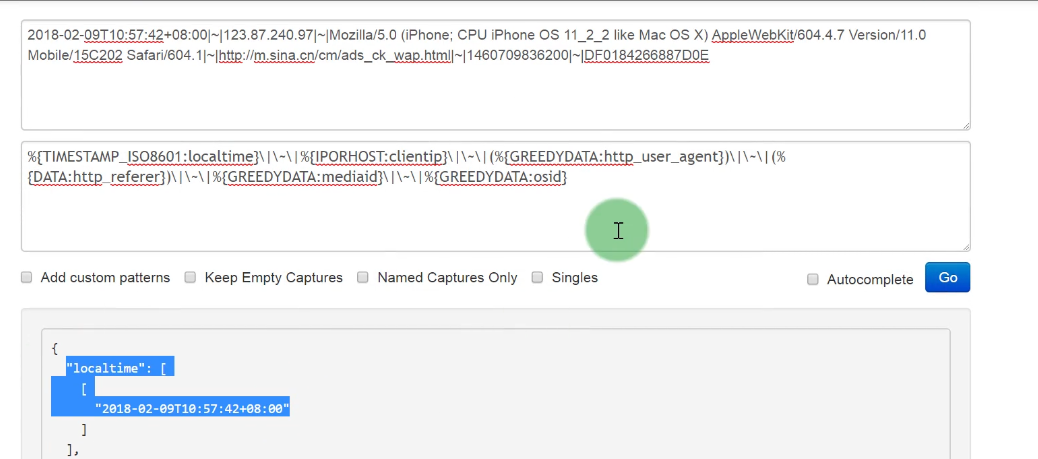
配置过滤检测
1 | # 流程 |
1 | [root@logstash test]# vim logstash7.conf |
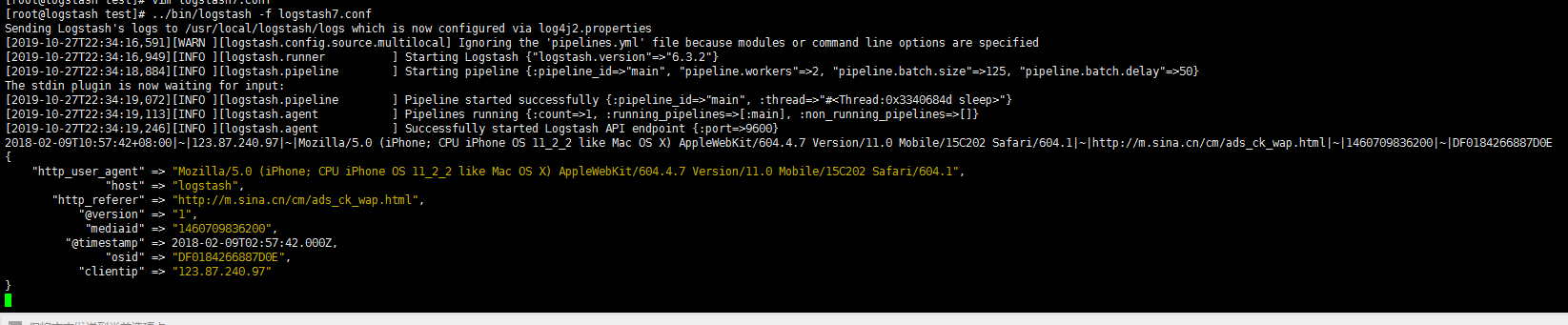
1 | ELK的难点就在于 日志的过滤,清晰 |
Logstash 输出插件(output)
- output是Logstash的最后阶段,一个事件可以经过多个输出,而一旦所有输出处理完成,整个事件就执行完成。
- 一些常用的输出包括:
1 | 1. file: 表示将日志数据写入磁盘上的文件。 |
- Logstash还支持输出到nagios、hdfs、email(发送邮件)和Exec(调用命令执行)
1 | # 官方文档 |
输出到标准输出(stdout)
- stdout与之前介绍过的stdin插件一样,它是最基础和简单的输出插件
1 | output { |
保存为文件(file)
- file插件可以将输出保存到一个文件中
- 很棒,相当于文件的实时备份
1 | # 使用了变量匹配,用于自动匹配时间和主机名,这在实际使用中很有帮助。 |
1 | [root@logstash test]# vim logstash8.conf |
完整同步日志
1 | [root@logstash test]# vim logstash8.conf |
输出到 elasticsearch
- Logstash将过滤、分析好的数据输出到elasticsearch中进行存储和查询,是最经常使用的方法。
1 | output { |
- 上面配置中每个配置项含义如下:
1 | host: |