ELK 收集日志的几种方式
- ELK收集日志常用的有两种方式,分别是:
- 不修改源日志的格式,而是通过logstash的grok方式进行过滤、清洗,将原始无规则的日志转换为规则的日志。
- 修改源日志输出格式,按照需要的日志格式输出规则日志,logstash只负责日志的收集和传输,不对日志做任何的过滤清洗。
- 这两种方式各有优缺点,
- 第一种方式不用修改原始日志输出格式,直接通过logstash的grok方式进行过滤分析,
- 好处是对线上业务系统无任何影响,缺点是logstash的grok方式在高压力情况下会成为性能瓶颈,如果要分析的日志量超大时,日志过滤分析可能阻塞正常的日志输出。
- 因此,在使用logstash时,能不用grok的,尽量不使用grok过滤功能。
- 第二种方式缺点是需要事先定义好日志的输出格式,这可能有一定工作量,
- 但优点更明显,因为已经定义好了需要的日志输出格式,logstash只负责日志的收集和传输,这样就大大减轻了logstash的负担,可以更高效的收集和传输日志。
- 另外,目前常见的web服务器,例如apache、nginx等都支持自定义日志输出格式。因此,在企业实际应用中,第二种方式是首选方案。
1 | 主要看系统是否已上线,如果没有上线可与研发技术确认,使用定义好的日志输出格式,减少logstash压力, |
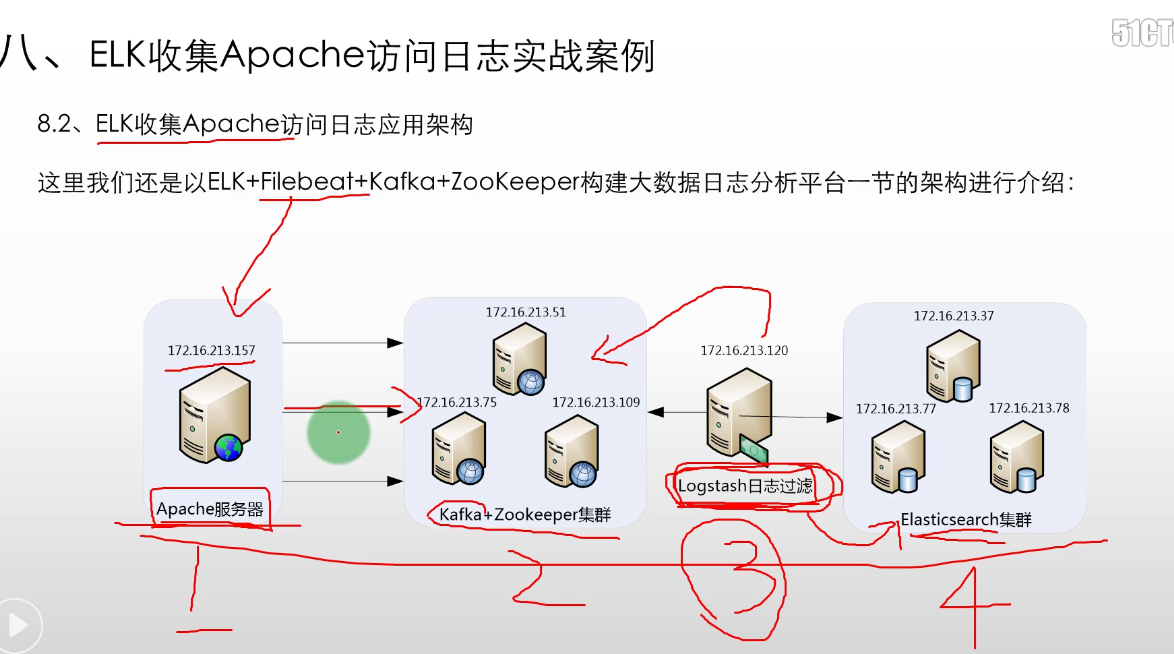
ELK 收集Apache访问日志应用架构
- ELK+Filebeat+Kafka+ZooKeeper构建大数据日志
- 前端是apache服务器
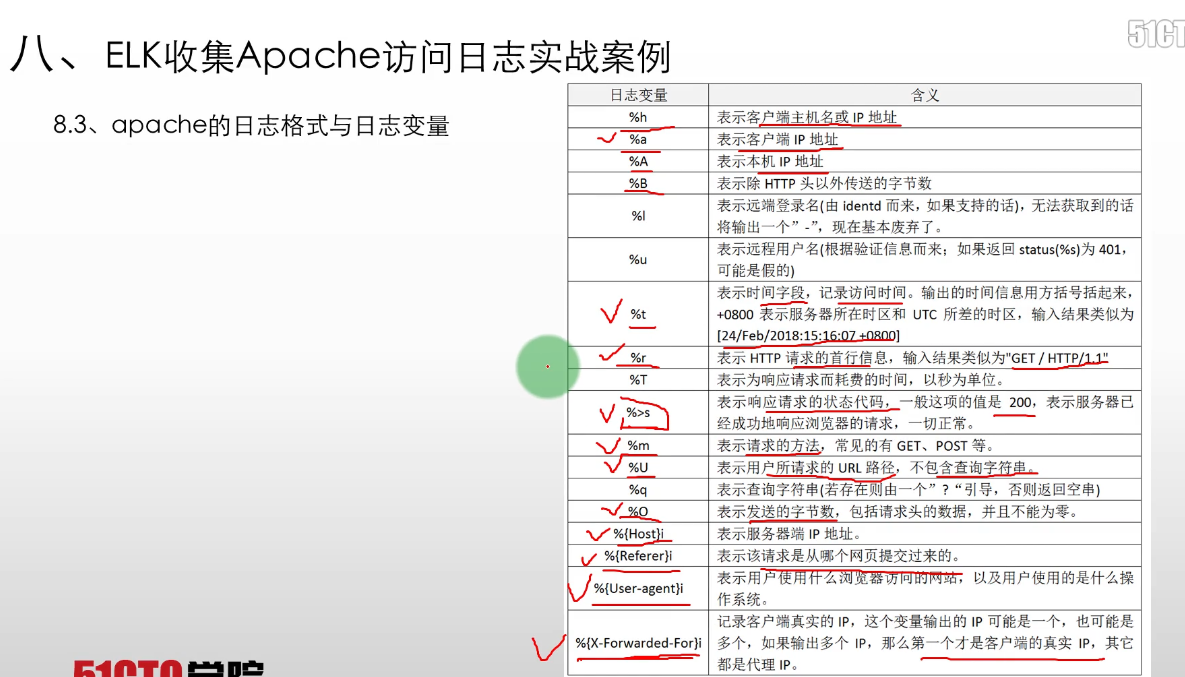
apache 的日志格式与日志变量
- apache支持自定义输出日志格式,但是,apache有很多日志变量字段,所以在收集日志前,需要首先确定哪些是我们需要的日志字段,然后将日志格式定下来。
- 要完成这个工作,需要了解apache日志字段定义的方法和日志变量的含义,在apache配置文件httpd.conf中,对日志格式定义的配置项为LogFormat,
- 默认的日志字段定义为如下内容:
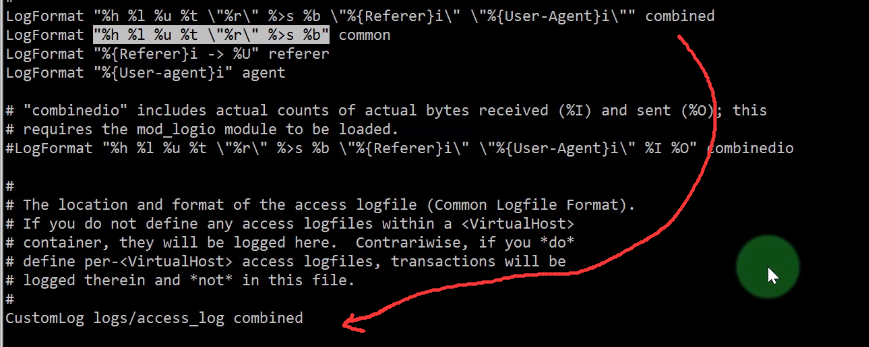
1 | LogFormat "%h %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined |
apache 的日志格式
自定义apache日志格式
- 这里定义将apache日志输出为json格式,下面仅列出apache配置文件httpd.conf中日志格式和日志文件定义部分,定义好的日志格式与日志文件如下:
1 | [root@filebeat1 ~]# vim /etc/httpd/conf/httpd.conf |
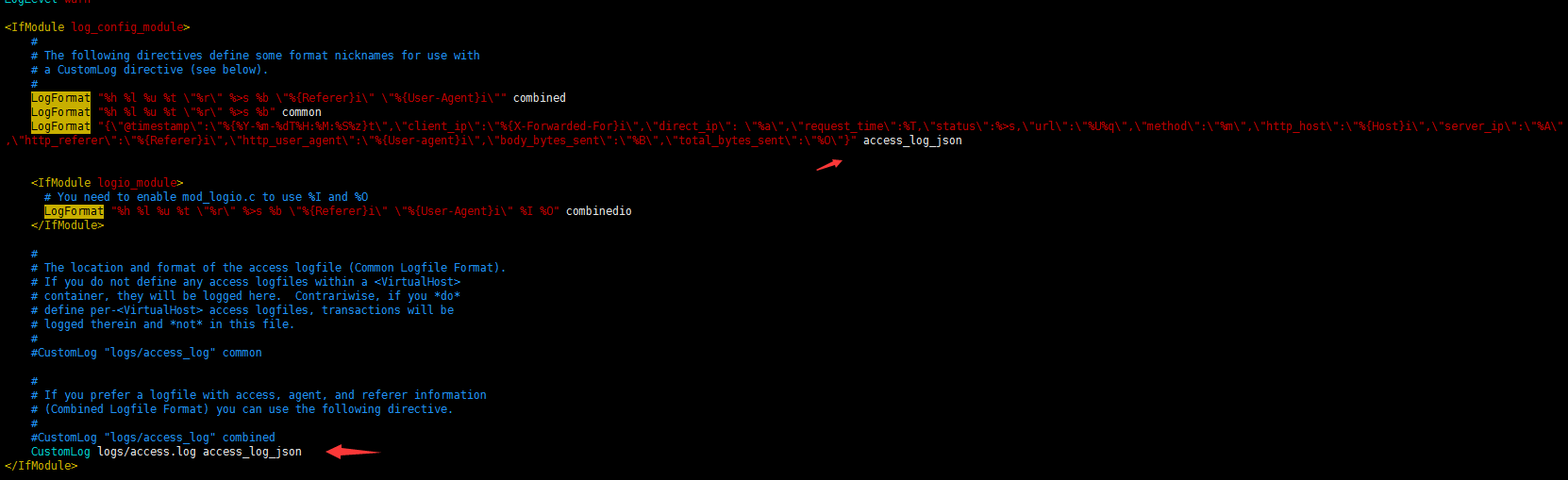
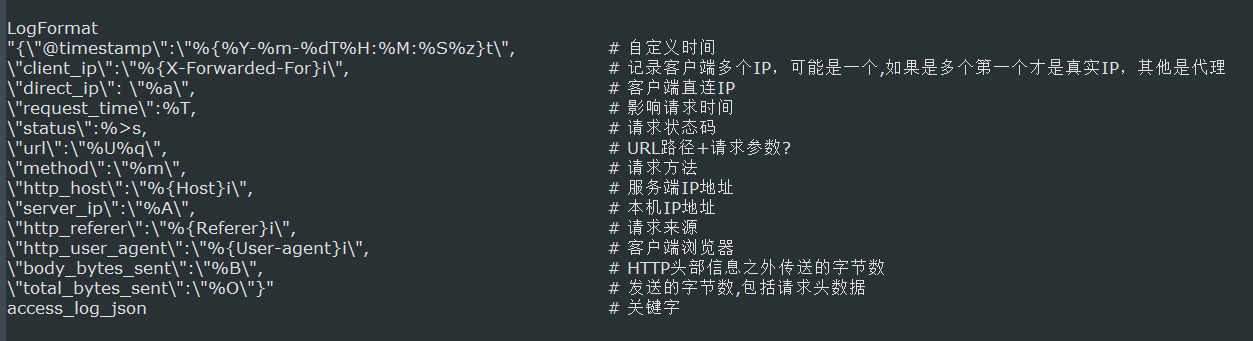
- 这里通过LogFormat指令定义了日志输出格式,在这个自定义日志输出中,定义了13个字段,定义方式为:字段名称:字段内容,字段名称是随意指定的,
- 能代表其含义即可,字段名称和字段内容都通过双引号括起来,而双引号是特殊字符,需要转移,因此,使用了转移字符“\”,每个字段之间通过逗号分隔。
- 此外,还定义了一个时间字段 @timestamp,这个字段的时间格式也是自定义的,此字段记录日志的生成时间,非常有用。
- CustomLog指令用来指定日志文件的名称和路径。
- 需要注意的是,上面日志输出字段中用到了body_bytes_sent和total_bytes_sent发送字节数统计字段,这个功能需要apache加载mod_logio.so模块,
- 如果没有加载这个模块的话,需要安装此模块并在httpd.conf文件中加载一下即可。
1 | # 重启服务 |

验证日志输出
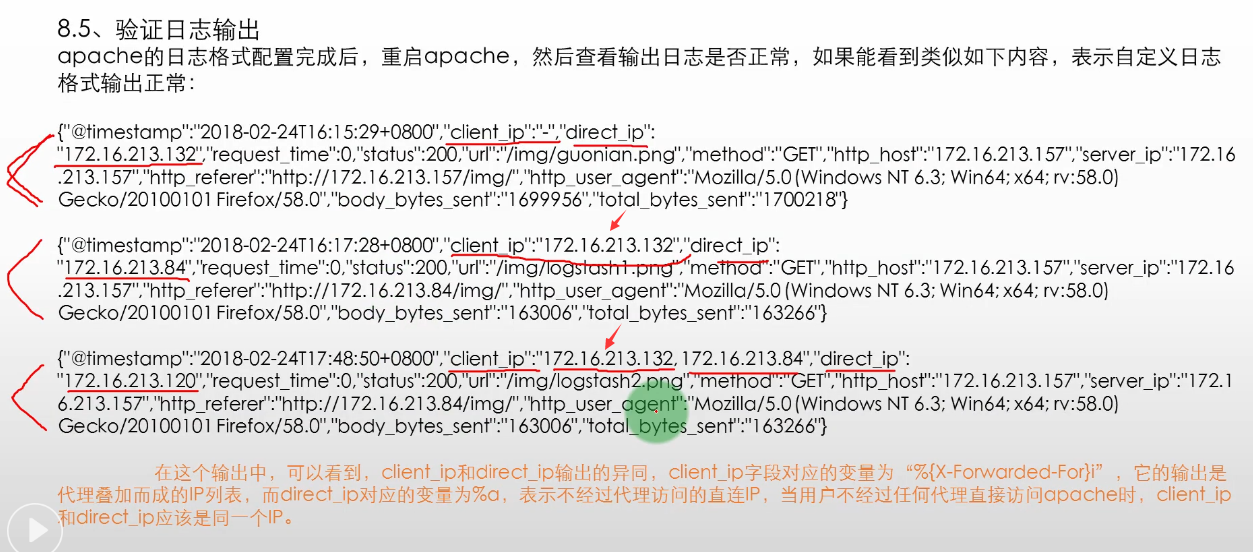
apache的日志格式配置完成后,重启apache,然后查看输出日志是否正常,如果能看到类似如下内容,表示自定义日志格式输出正常:
在这个输出中,可以看到,client_ip和direct_ip输出的异同,
- client_ip字段对应的变量为“%{X-Forwarded-For}i”,它的输出是代理叠加而成的IP列表,
- 而direct_ip对应的变量为%a,表示不经过代理访问的直连IP,当用户不经过任何代理直接访问apache时,client_ip和direct_ip应该是同一个IP。
配置 filebeat
修改配置文件
- filebeat是安装在apache服务器上
1 | [root@filebeat1 logs]# cd /usr/local/filebeat/ |
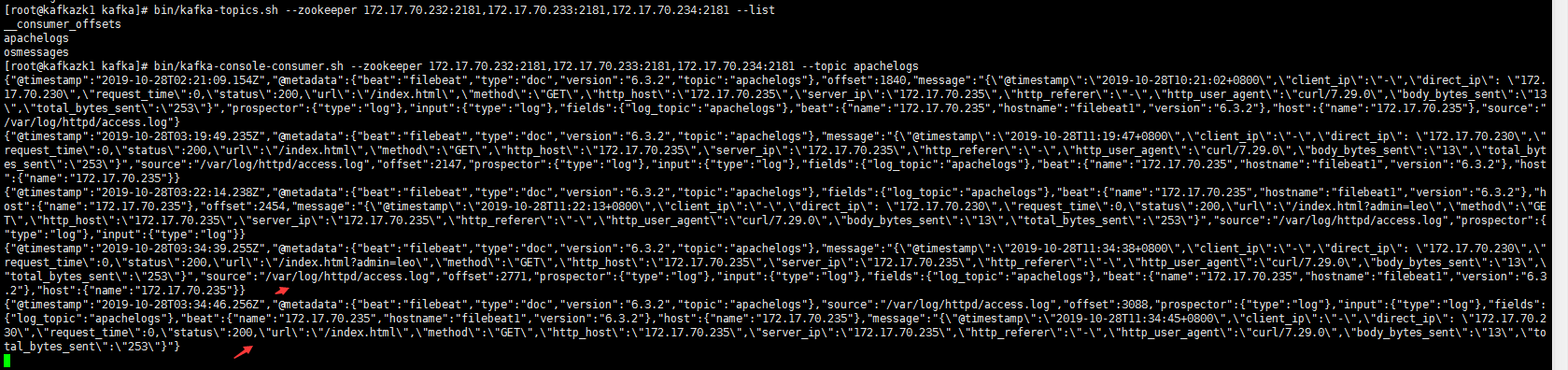
1 | 1. 这个配置文件中,是将apache的访问日志/var/log/httpd/access.log内容实时的发送到kafka集群topic为apachelogs中。 |
测试并启动
1 | # 启动 |

配置 logstash
- logstash事件配置文件kafka_apache_into_es.conf
1 | [root@logstash logstash]# cd /usr/local/logstash/ |
输入部分
1 | # 输入部分 |
过滤部分
1 | # 过滤部分 |
输出到终端测试
1 | # 放到终端输出测试 |
1 | ### 完整版本 |
1 | # 放到终端测试 |
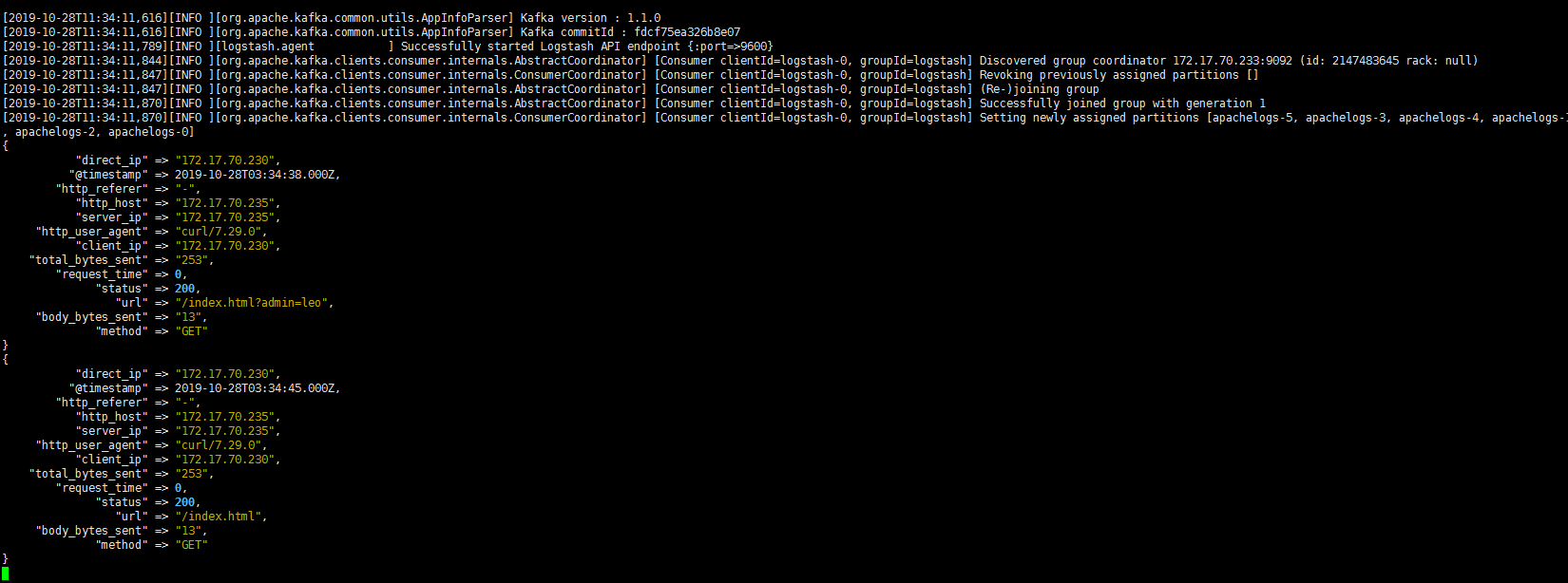
输出到 ES集群
1 | output { |

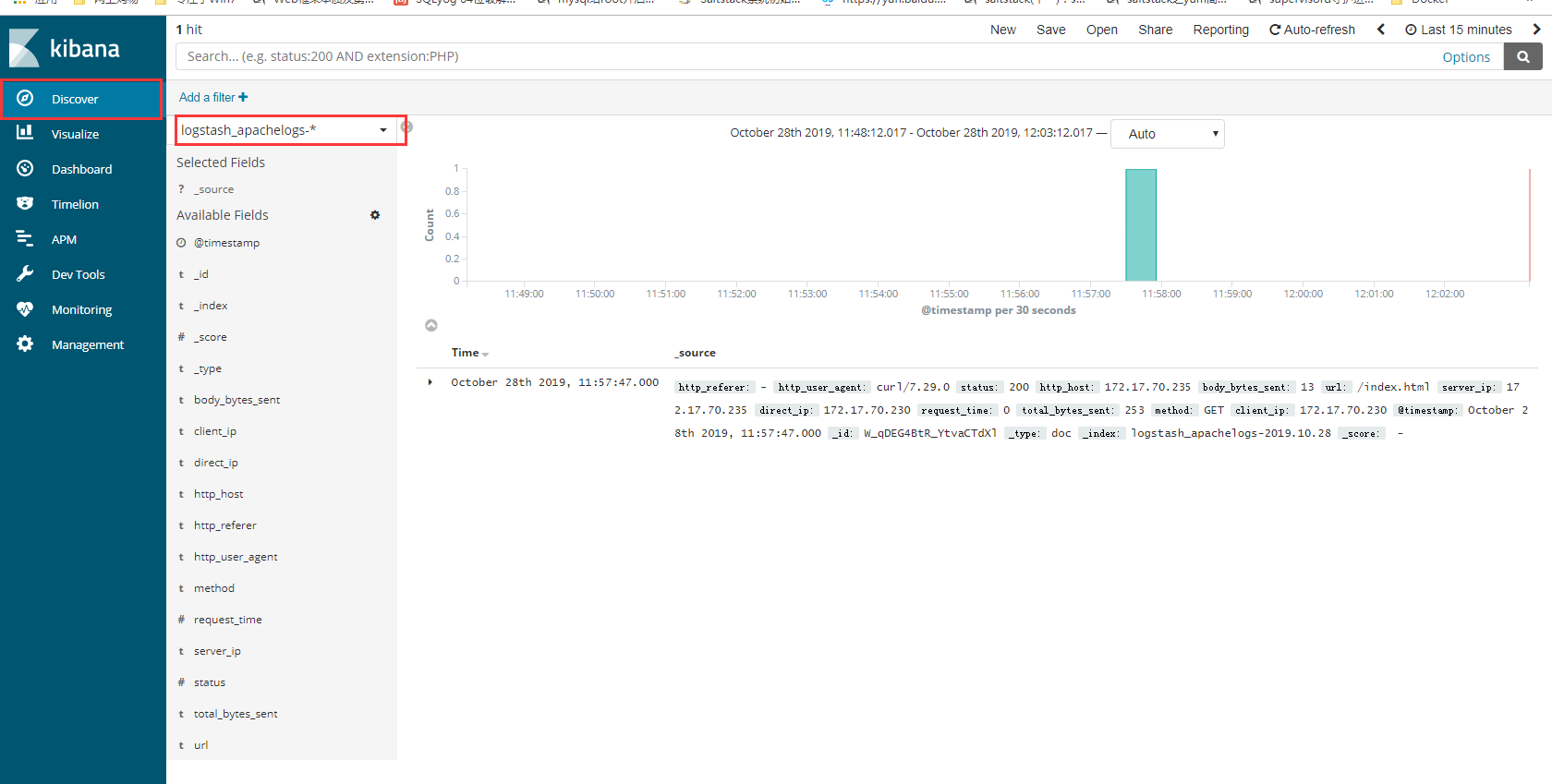
klbana 展示数据
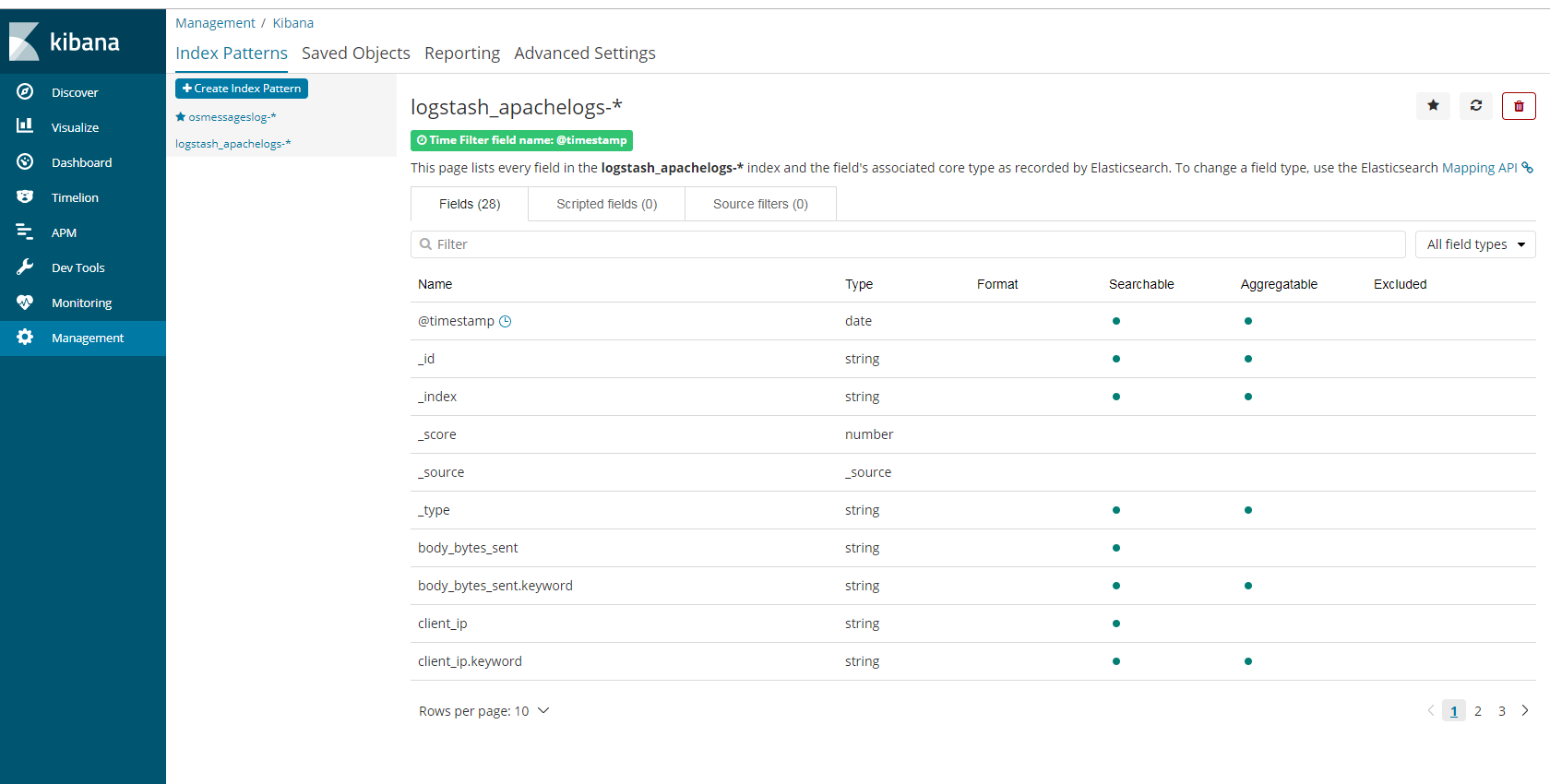
- filebeat收集数据到kafka,然后logstash从kafka拉取数据,如果数据能够正确发送到elasticsearch,
- 我们就可以在Kibana中配置索引了。
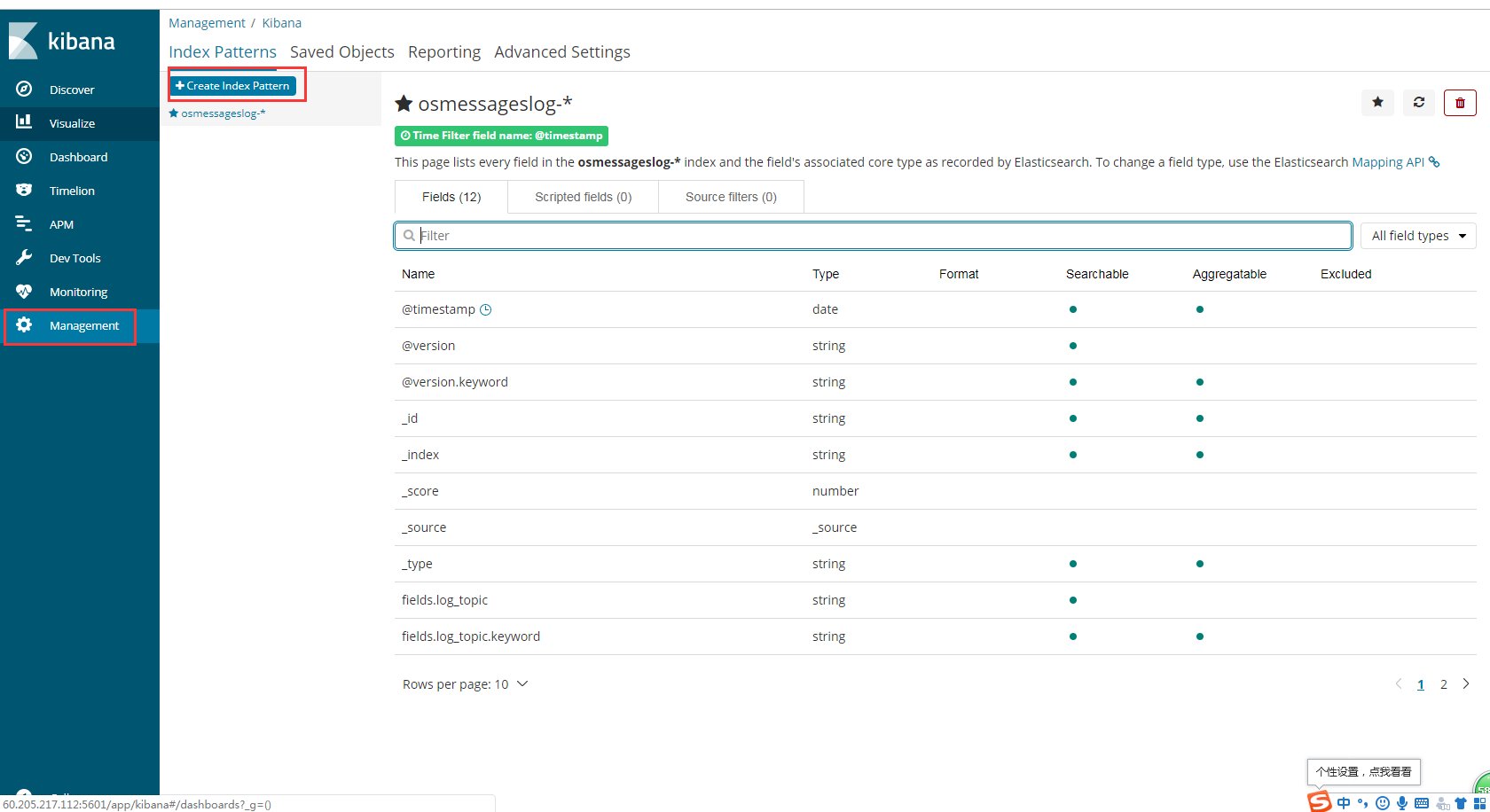
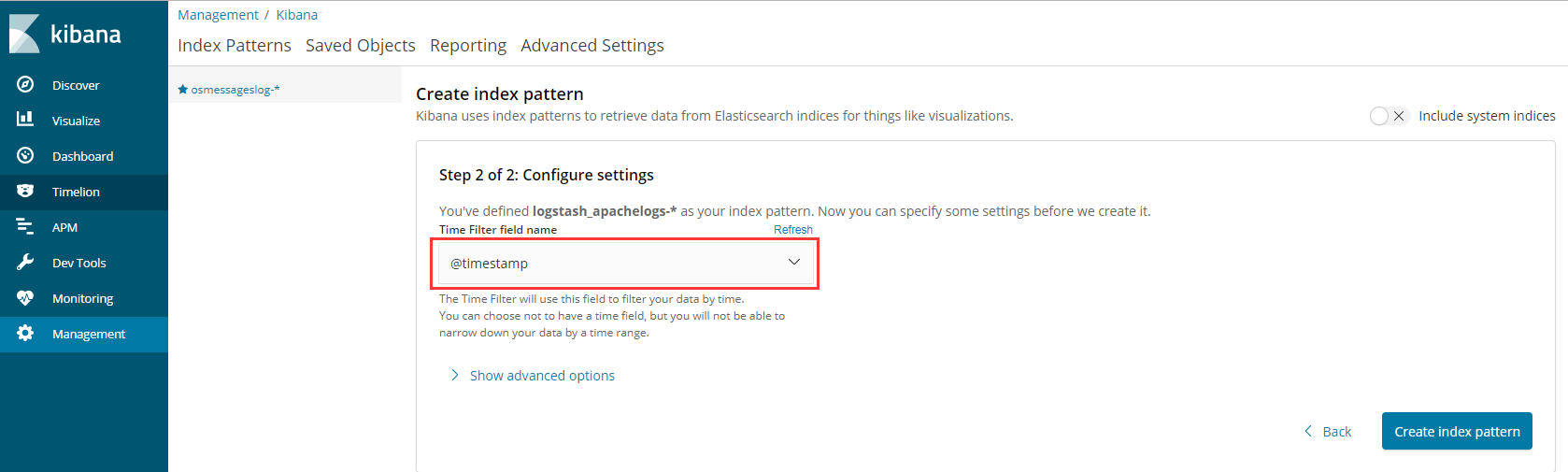
- 登录Kibana,首先配置一个index_pattern,点击kibana左侧导航中的Management菜单,
- 然后选择右侧的Index Patterns按钮,最后点击左上角的Create index pattern。
创建索引
1 | # 有数据才有索引 |
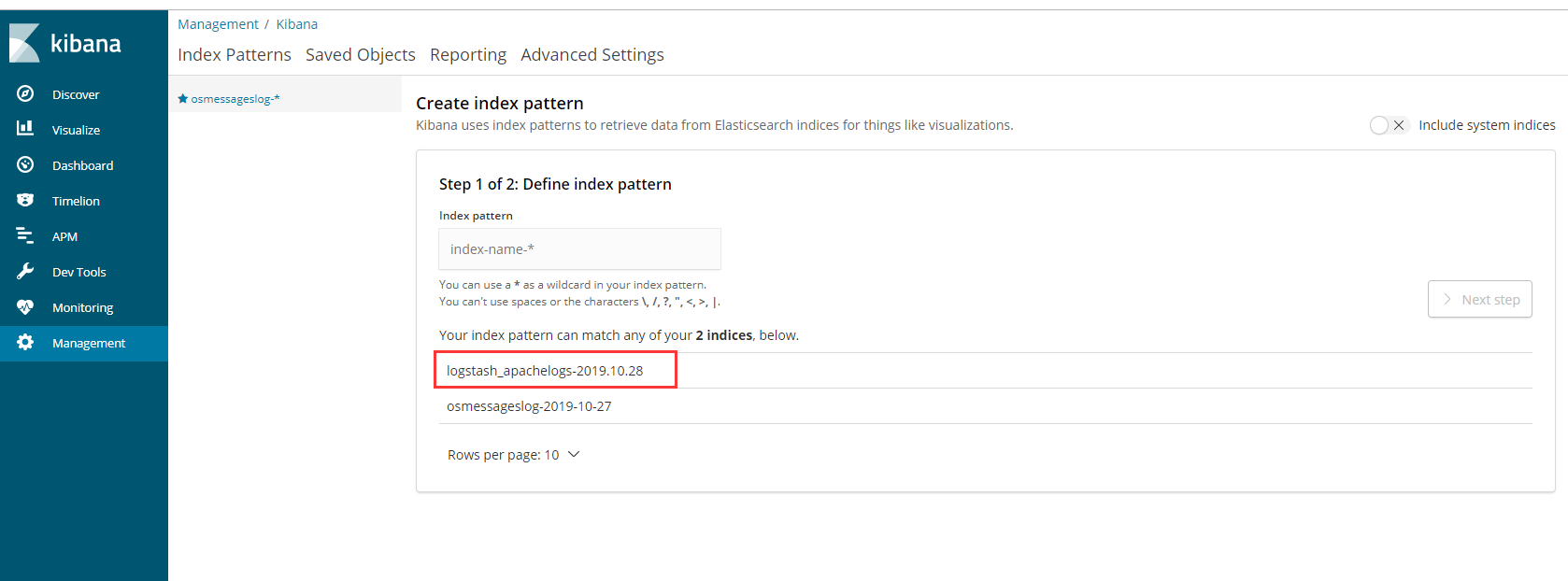
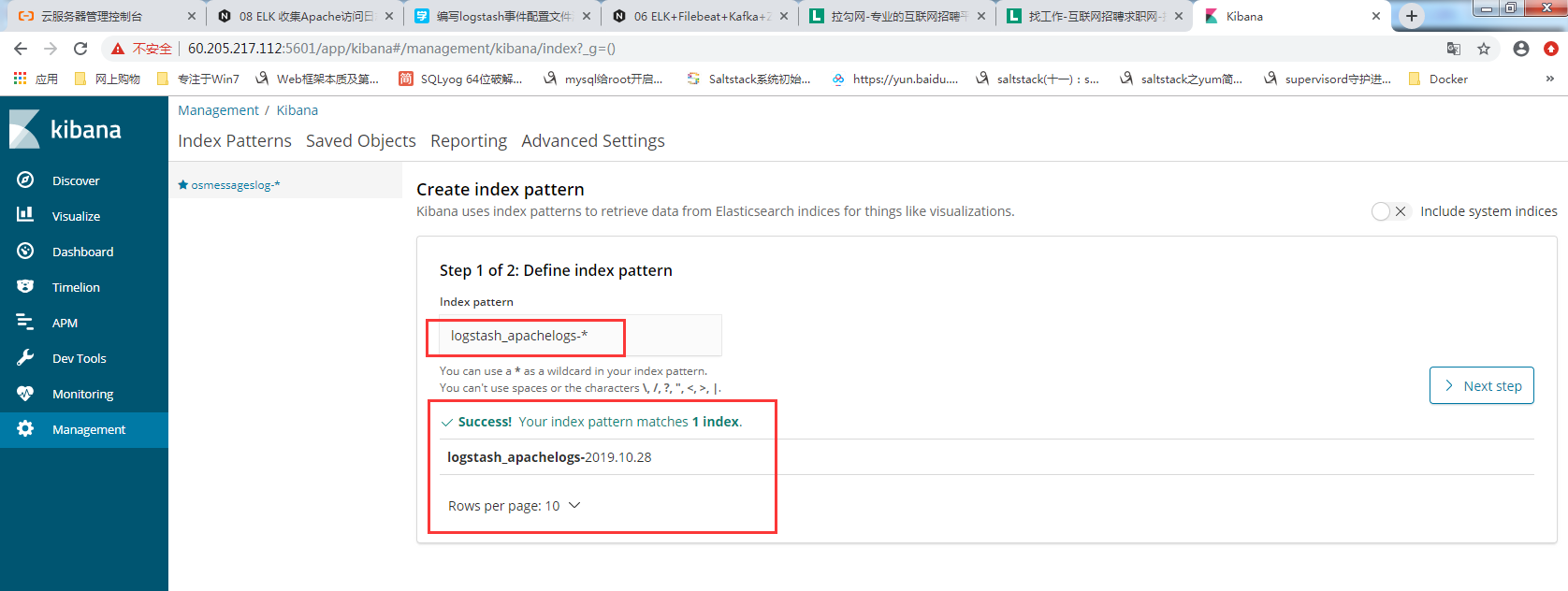
索引以什么排序
1 | 以时间字段@timestamp排序 |
展示