
容器技术的核心功能
- 容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”
- 对于 Docker 等大多数 Linux 容器来说,Cgroups 技术是用来制造约束的主要手段,而 Namespace 技术则是用来修改进程视图的主要方法。
进程的静态表现和动态表现
- 对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;
- 而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。
docker 的边界是如何实现的
1 | [root@k8s-master1 ~]# docker run -it --rm --name test busybox sh |
- Docker 里最开始执行的 sh 就是这个容器内部的第 1 号进程(PID=1),而这个容器里一共只有两个进程在运行。
- 这就意味着,前面执行的 sh,以及我们刚刚执行的 ps,已经被 Docker 隔离在了一个跟宿主机完全不同的世界当中。
- 原本 每当我们在宿主机上运行了一个 /bin/sh 程序,操作系统都会给它分配一个进程编号,比如 PID=100
- 这个编号是进程的唯一标识,就像员工的工牌一样。所以 PID=100,可以粗略地理解为这个 /bin/sh 是我们公司里的第 100 号员工,而第 1 号员工就自然是比尔 · 盖茨这样统领全局的人物。
- 而现在,我们要通过 Docker 把这个 /bin/sh 程序运行在一个容器当中。这时候,Docker 就会在这个第 100 号员工入职时给他施一个“障眼法”,让他永远看不到前面的其他 99 个员工,更看不到比尔 · 盖茨。
- 这样,他就会错误地以为自己就是公司里的第 1 号员工。
- 这种机制,其实就是对被隔离应用的进程空间做了手脚,使得这些进程只能看到重新计算过的进程编号,比如 PID=1。
- 可实际上,他们在宿主机的操作系统里,还是原来的第 100 号进程。这种技术,就是 Linux 里面的 Namespace 机制。
Linux namespace
- Linux namespace 实现了 6 项资源隔离,基本上涵盖了一个小型操作系统的运行要素,包括主机名、用户权限、文件系统、网络、进程号、进程间通信。
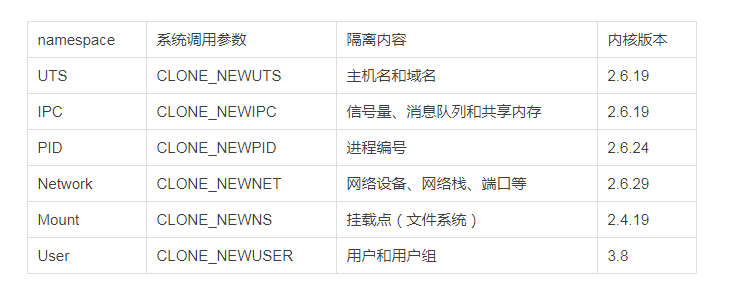
Namespace 的使用机制
- 这 6 项资源隔离分别对应 6 种系统调用,通过传入上表中的参数,调用 clone() 函数来完成。
- 它其实只是 Linux 创建新进程的一个可选参数
- 在 Linux 系统中创建线程的系统调用是 clone(),比如:
1 | int pid = clone(main_function, stack_size, CLONE_NEWPID | SIGCHLD, NULL); |
- 创建的这个进程将会“看到”一个全新的进程空间,在这个进程空间里,它的 PID 是 1。之所以说“看到”,
是因为这只是一个“障眼法”,在宿主机真实的进程空间里,这个进程的 PID 还是真实的数值,比如 100。
Docker 容器这个听起来玄而又玄的概念,实际上是在创建容器进程时,指定了这个进程所需要启用的一组 Namespace 参数。
- 这样,容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置。而对于宿主机以及其他不相关的程序,它就完全看不到了。
- 所以说,容器,其实是一种特殊的进程而已。
1 | [root@k8s-master1 ~]# ps -ef|grep busy |
虚拟机和容器
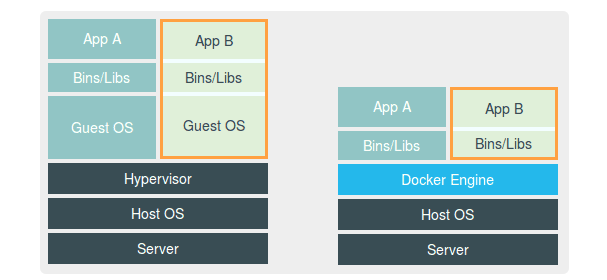
虚拟机的工作原理
- Hypervisor 的软件是虚拟机最主要的部分。它通过硬件虚拟化功能,模拟出了运行一个操作系统需要的各种硬件,比如 CPU、内存、I/O 设备等等。
- 然后,它在这些虚拟的硬件上安装了一个新的操作系统,即 Guest OS。
- 用户的应用进程就可以运行在这个虚拟的机器中,它能看到的自然也只有 Guest OS 的文件和目录,以及这个机器里的虚拟设备。
- 这就是为什么虚拟机也能起到将不同的应用进程相互隔离的作用。
容器的工作原理
- 跟真实存在的虚拟机不同,在使用 Docker 的时候,并没有一个真正的“Docker 容器”运行在宿主机里面。Docker 项目帮助用户启动的,还是原来的应用进程。
- 只不过在创建这些进程时,Docker 为它们加上了各种各样的 Namespace 参数。
- 这些进程就会觉得自己是各自 PID Namespace 里的第 1 号进程,只能看到各自 Mount Namespace 里挂载的目录和文件,只能访问到各自 Network Namespace 里的网络设备,就仿佛运行在一个个“容器”里面,与世隔绝。
隔离与限制
- Namespace 技术实际上修改了应用进程看待整个计算机“视图”,即它的“视线”被操作系统做了限制,只能“看到”某些指定的内容。但对于宿主机来说,这些被“隔离”了的进程跟其他进程并没有太大区别。
- 不应该把 Docker Engine 或者任何容器管理工具放在跟 Hypervisor 相同的位置,因为它们并不像 Hypervisor 那样对应用进程的隔离环境负责,也不会创建任何实体的“容器”,真正对隔离环境负责的是宿主机操作系统本身
- 用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。
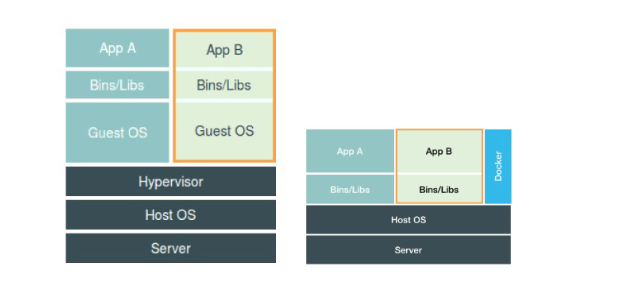
- 使用虚拟化技术作为应用沙盒,就必须要由 Hypervisor 来负责创建虚拟机,这个虚拟机是真实存在的,并且它里面必须运行一个完整的 Guest OS 才能执行用户的应用进程。这就不可避免地带来了额外的资源消耗和占用。
- 容器化后的用户应用,却依然还是一个宿主机上的普通进程,这就意味着这些因为虚拟化而带来的性能损耗都是不存在的;而另一方面,使用 Namespace 作为隔离手段的容器并不需要单独的 Guest OS,这就使得容器额外的资源占用几乎可以忽略不计。
- 所以说,“敏捷”和“高性能”是容器相较于虚拟机最大的优势,也是它能够在 PaaS 这种更细粒度的资源管理平台上大行其道的重要原因。
- 基于 Linux Namespace 的隔离机制相比于虚拟化技术也有很多不足之处,其中最主要的问题就是:隔离得不彻底。
哪些地方没有进行隔离
- 首先,既然容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。
这意味着,如果你要在 Windows 宿主机上运行 Linux 容器,或者在低版本的 Linux 宿主机上运行高版本的 Linux 容器,都是行不通的。
在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,最典型的例子就是:时间。
- 在生产环境中,没有人敢把运行在物理机上的 Linux 容器直接暴露到公网上。
容器的限制
- 虽然容器内的第 1 号进程在“障眼法”的干扰下只能看到容器里的情况,但是宿主机上,它作为第 100 号进程与其他所有进程之间依然是平等的竞争关系。
- 这就意味着,虽然第 100 号进程表面上被隔离了起来,但是它所能够使用到的资源(比如 CPU、内存),却是可以随时被宿主机上的其他进程(或者其他容器)占用的。
- 当然,这个 100 号进程自己也可能把所有资源吃光。这些情况,显然都不是一个“沙盒”应该表现出来的合理行为。
- 而 Linux Cgroups 就是 Linux 内核中用来为进程设置资源限制的一个重要功能。
Linux Cgroups
- Linux Cgroups 的全称是 Linux Control Group。
- 它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
- 在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
- 它的输出结果,是一系列文件系统目录
1 | [root@k8s-master1 containers]# mount -t cgroup |
- 在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类
- 子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
1 | [root@k8s-master1 containers]# ls /sys/fs/cgroup/cpu |
限制一个docker容器的资源使用
- Linux Cgroups 的设计还是比较易用的,简单粗暴地理解呢,它就是一个子系统目录加上一组资源限制文件的组合。
- 而对于 Docker 等 Linux 容器项目来说,它们只需要在每个子系统下面,为每个容器创建一个控制组(即创建一个新目录),
- 然后在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中就可以了。
- 而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
1 | # docker run -it --cpu-period=100000 --cpu-quota=20000 ubuntu /bin/bash |
1 | 1. 它意味着在每 100 ms 的时间里,被该控制组限制的进程只能使用 50 ms 的 CPU 时间,也就是说这个进程只能使用到 50% 的 CPU 带宽。 |
1 | # 容器里跑一个死循环 吃死CPU 再去查看使用率 |
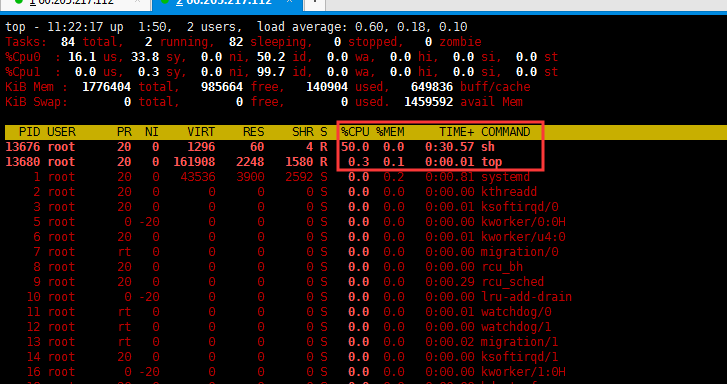
1 | # 被限制的进程的 PID 写入 container 组里的 tasks 文件 |
总结
- 一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。
- 使用namespace 在docker进程启动的时候做隔离,让容器就只能“看”到当前 Namespace 所限定的资源、文件、设备、状态,或者配置
- 然后使用 cgroup 为每个容器创建一个控制组 在启动容器进程之后,把这个进程的 PID 填写到对应控制组的 tasks 文件中 控制他们的资源使用率。
- 这也是容器技术中一个非常重要的概念,即:容器是一个“单进程”模型。
1 | 1. 由于一个容器的本质就是一个进程,用户的应用进程实际上就是容器里 PID=1 的进程,也是其他后续创建的所有进程的父进程。 |
1 | 1. 但是,在后面分享容器设计模式时,我还会推荐其他更好的解决办法。 |
- 另外,跟 Namespace 的情况类似,Cgroups 对资源的限制能力也有很多不完善的地方,被提及最多的自然是 /proc 文件系统的问题。
- 众所周知,Linux 下的 /proc 目录存储的是记录当前内核运行状态的一系列特殊文件,用户可以通过访问这些文件,查看系统以及当前正在运行的进程的信息,
- 比如 CPU 使用情况、内存占用率等,这些文件也是 top 指令查看系统信息的主要数据来源。
- 但是,你如果在容器里执行 top 指令,就会发现,它显示的信息居然是宿主机的 CPU 和内存数据,而不是当前容器的数据。
- 造成这个问题的原因就是,/proc 文件系统并不知道用户通过 Cgroups 给这个容器做了什么样的资源限制,即:/proc 文件系统不了解 Cgroups 限制的存在。
- 生产环境中,这个问题必须进行修正,否则应用程序在容器里读取到的 CPU 核数、可用内存等信息都是宿主机上的数据,这会给应用的运行带来非常大的困惑和风险。
- 这也是在企业中,容器化应用碰到的一个常见问题,也是容器相较于虚拟机另一个不尽如人意的地方。
问题
- 如何修复容器中的 top 指令以及 /proc 文件系统中的信息
深入理解容器镜像
- Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
- 用到了一种叫作联合文件系统(Union File System)的能力。
- Union File System 也叫 UnionFS,最主要的功能是将多个不同位置的目录联合挂载(union mount)到同一个目录下。
- centos:7使用的UnionFS 为 overlay2
1 | [root@k8s-master1 docker]# docker info |
- Docker 镜像使用的 rootfs,往往由多个“层”组成
- 通过结合使用 Mount Namespace 和 rootfs,容器就能够为进程构建出一个完善的文件系统隔离环境。
- 当然,这个功能的实现还必须感谢 chroot 和 pivot_root 这两个系统调用切换进程根目录的能力。
- 而在 rootfs 的基础上,Docker 公司创新性地提出了使用多个增量 rootfs 联合挂载一个完整 rootfs 的方案,这就是容器镜像中“层”的概念。
Docker 容器的本质
Flask小例子
- 使用 Flask 框架启动了一个 Web 服务器,功能是:
- 如果当前环境中有“NAME”这个环境变量,就把它打印在“Hello”后,否则就打印“Hello world”,最后再打印出当前环境的 hostname。
1 | [root@k8s-master1 runtime]# vim app.py |
1 | # python依赖 |
应用容器化的第一步,制作容器镜像
- 制作镜像有两个方法,手动构建 和 Dockerfile 构建
- 手动构建就是基于base镜像一点一点的制作容器,最后提交为镜像
1 | # 提交本地镜像 |
- 使用Dockfile 制作镜像
1 | [root@k8s-master1 runtime]# vim Dockerfile |
- Dockerfile 的设计思想,是使用一些标准的原语(即大写高亮的词语),描述我们所要构建的 Docker 镜像。并且这些原语,都是按顺序处理的。
1 | 1. 比如 FROM 原语,指定了“python:2.7-slim”这个官方维护的基础镜像,从而免去了安装 Python 等语言环境的操作。否则,这一段我们就得这么写了: |
1 | [root@k8s-master1 runtime]# ls -l |
- 需要注意的是,Dockerfile 中的每个原语执行后,都会生成一个对应的镜像层
- 即使原语本身并没有明显地修改文件的操作(比如,ENV 原语),它对应的层也会存在。只不过在外界看来,这个层是空的。
docker run 命令启动容器
1 | [root@k8s-master1 docker]# docker run -d --name hello -p 4000:80 helloworld |
docker exec 是怎么做到进入容器里的呢?
- Linux Namespace 创建的隔离空间虽然看不见摸不着,但一个进程的 Namespace 信息在宿主机上是确确实实存在的,并且是以一个文件的方式存在。
- Docker 容器的进程号(PID)
1 | [root@k8s-master1 docker]# docker inspect --format '{{.State.Pid }}' hello |
1 | [root@k8s-master1 docker]# ls -l /proc/14883/ns |
- 这也就意味着:一个进程,可以选择加入到某个进程已有的 Namespace 当中,从而达到“进入”这个进程所在容器的目的,这正是 docker exec 的实现原理。
- Docker 还专门提供了一个参数,可以让你启动一个容器并“加入”到另一个容器的 Network Namespace 里,这个参数就是 -net,比如:
- docker commit,实际上就是在容器运行起来后,把最上层的“可读写层”,加上原先容器镜像的只读层,打包组成了一个新的镜像。
Volume(数据卷)
- 容器里进程新建的文件,怎么才能让宿主机获取到?
- 宿主机上的文件和目录,怎么才能让容器里的进程访问到?
- 这正是 Docker Volume 要解决的问题:Volume 机制,允许你将宿主机上指定的目录或者文件,挂载到容器里面进行读取和修改操作。
- 在 Docker 项目里,它支持两种 Volume 声明方式,可以把宿主机目录挂载进容器的 /test 目录当中:
1 | $ docker run -v /test ... |
- 而这两种声明方式的本质,实际上是相同的:都是把一个宿主机的目录挂载进了容器的 /test 目录。
- 只不过,在第一种情况下,由于你并没有显示声明宿主机目录,那么 Docker 就会默认在宿主机上创建一个临时目录 /var/lib/docker/volumes/[VOLUME_ID]/_data,然后把它挂载到容器的 /test 目录上。
- 而在第二种情况下,Docker 就直接把宿主机的 /home 目录挂载到容器的 /test 目录上。