传统弹性伸缩的困境
1 | 1. 简单理解,资源不够了加机器,资源多了减机器 |
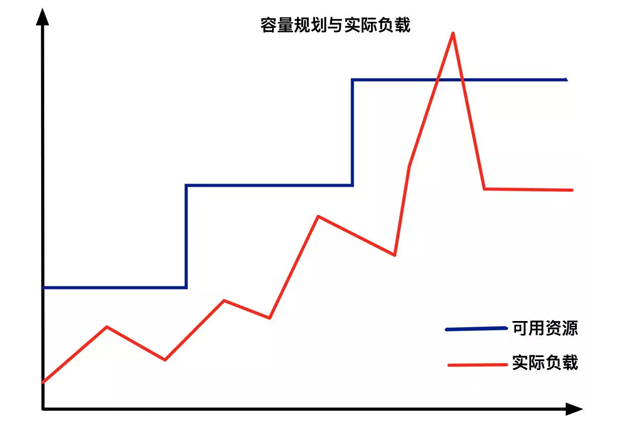
- 从传统意义上,弹性伸缩:主要解决的问题是 容量规划 与 实际负载 的矛盾。
- 蓝色水位线表示集群资源容量随着负载的增加不断扩容,红色曲线表示集群资源实际负载变化。
- 弹性伸缩就是要解决当实际负载增大,而集群资源容量没来得及反应的问题。
Kubernetes 中弹性伸缩存在的问题
- 常规的做法是给集群资源预留保障集群可用,通常20%左右。
- 这种方式看似没什么问题,但放到Kubernetes中,就会发现如下2个问题。
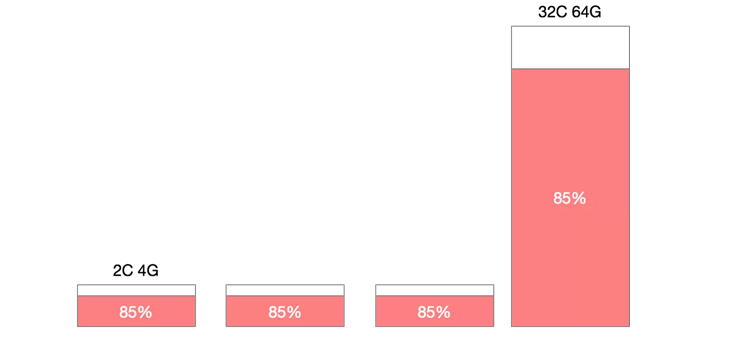
机器规格不统一,造成机器利用率百分比碎片化
- 在一个Kubernetes集群中,通常不只包含一种规格的机器,
- 假设集群中存在4C8G与16C32G两种规格的机器,对于10%的资源预留,这两种规格代表的意义是完全不同的。
- 特别是在缩容的场景下,为了保证缩容后集群稳定性,我们一般会一个节点一个节点从集群中摘除,
- 那么如何判断节点是否可以摘除其利用率百分比就是重要的指标。
- 此时如果大规格机器有较低的利用率被判断缩容,那么很有可能会造成节点缩容后,容器重新调度后的争抢。
- 如果优先缩容小规格机器,则可能造成缩容后资源的大量冗余。
机器利用率不能单纯依靠宿主机计算
- 在大部分生产环境中,资源利用率都不会保持一个高的水位,但从调度来讲,调度应该保持一个比较高的水位,这样才能保障集群稳定性,又不过多浪费资源。
弹性伸缩概念的延伸
- 不是所有的业务都存在峰值流量,越来越细分的业务形态带来更多成本节省和可用性之间的跳转。
- 不同类型的负载对于弹性伸缩的要求有所不同,在线负载对弹出时间敏感,离线任务对价格敏感,定时任务对调度敏感。
1 | 1. 在线负载型:微服务、网站、API |
kubernetes 弹性伸缩布局
- 在 Kubernetes 的生态中,在多个维度、多个层次提供了不同的组件来满足不同的伸缩场景。
- 有三种弹性伸缩:
1 | - CA(Cluster Autoscaler):Node级别自动扩/缩容 适用于,无状态应用 |
- 如果在云上建议 HPA 结合 cluster-autoscaler 的方式进行集群的弹性伸缩管理。
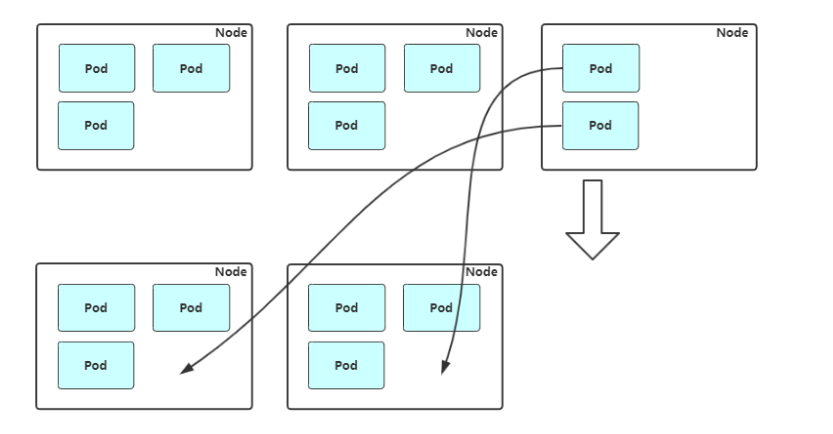
Node 自动扩容/缩容
Cluster AutoScaler
- 扩容:Cluster AutoScaler 定期检测是否有充足的资源来调度新创建的 Pod,当资源不足时会调用 Cloud Provider 创建新的 Node。
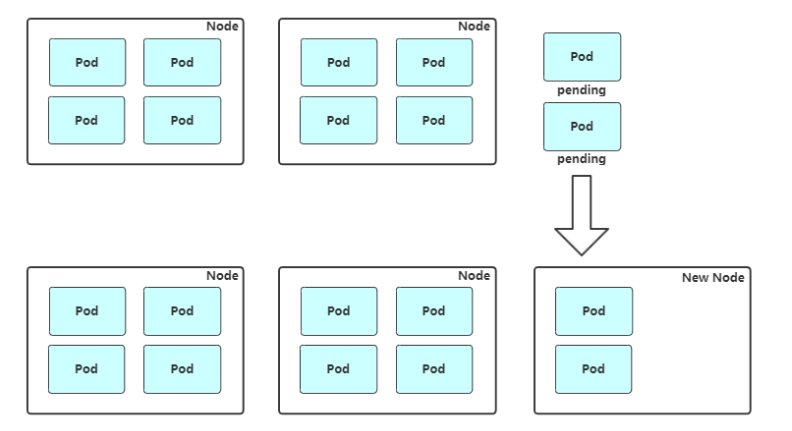
- 缩容:Cluster AutoScaler 也会定期监测 Node 的资源使用情况,当一个 Node 长时间资源利用率都很低时(低于 50%)自动将其所在虚拟机从云服务商中删除。此时,原来的 Pod 会自动调度到其他 Node 上面。
1 | 支持的云提供商: |
Ansible 扩容 Node
- 自动化流程:

1 | 1. 触发新增Node |
扩容
1 | # 模拟场景:创建超出当前资源的 pod,使当前k8s环境又需要扩容node的需求 |
1 | # 2. 创建超出当前资源的 pod |
1 | # 3. 准备 k8s-node3 节点 |
1 | # 4. 部署k8s-node3节点 |
1 | # 5. 手动加入集群 |
缩容
1 | # 考虑的较多 |
1 | # 平滑移除了一个 k8s 节点,正确流程如下: |
1 | # 2. 设置不可调度 |
1 | # 3. 驱逐这个节点上的已有的pod 到其他节点 |
1 | # 4. 移除节点 |
1 | # 总结: |
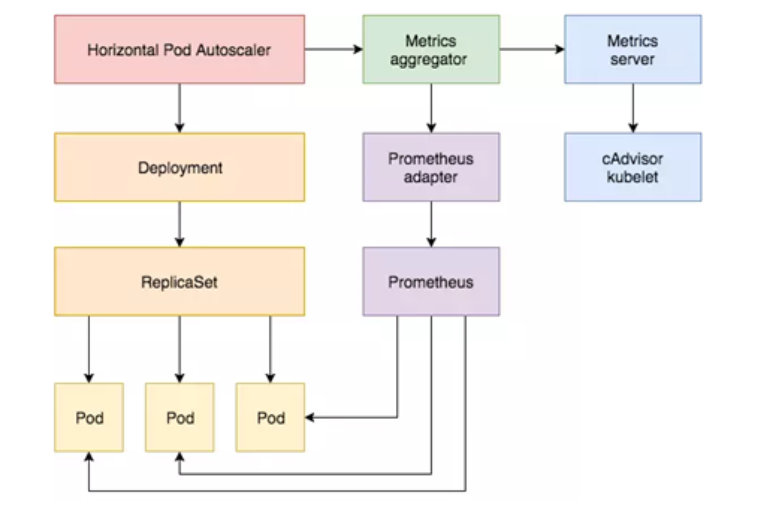
Pod 自动扩容/缩容(HPA)
- Horizontal Pod Autoscaler(HPA,Pod水平自动伸缩),根据资源利用率或者自定义指标自动调整 replication controller, deployment 或 replica set,
- 实现部署的自动扩展和缩减,让部署的规模接近于实际服务的负载。HPA不适于无法缩放的对象,例如DaemonSet。
1 | 1. 针对pod的利用率做计算 然后调整副本数量 |
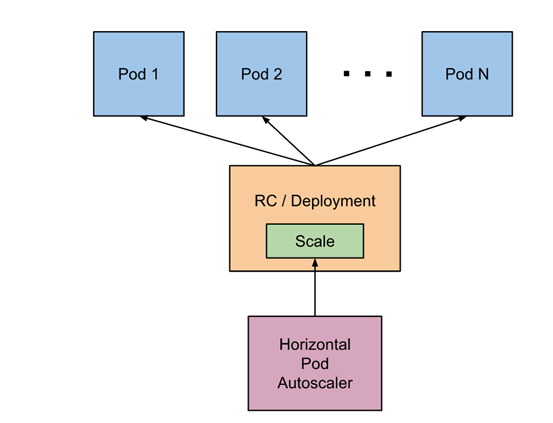
HPA 基本原理
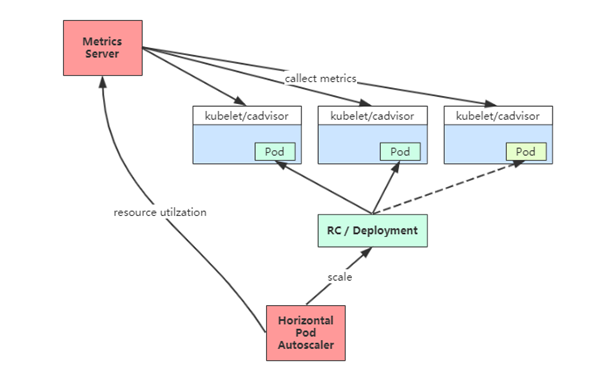
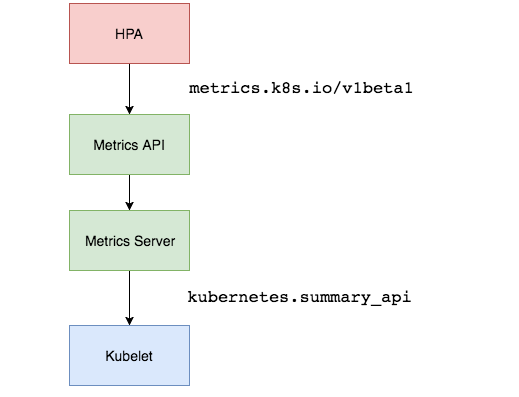
- Kubernetes 中的组件 Metrics Server 持续采集所有 Pod 副本的指标数据。 (heapster 在k8s 1.13 版本后 被弃用了)
- HPA 控制器通过 Metrics Server 的 API(Heapster 的 API 或聚合 API)获取这些数据,基于用户定义的扩缩容规则进行计算,得到目标 Pod 副本数量。
- 当目标 Pod 副本数量与当前副本数量不同时,HPA 控制器就向 Pod 的副本控制器(Deployment、RC 或 ReplicaSet)发起 scale 操作,调整 Pod 的副本数量,完成扩缩容操作。
1 | 1. HPA需要创建规则,里面定义好缩容和扩容范围,设置好对象,设置阈值 |
扩容冷却 和 缩容冷却
- 在弹性伸缩中,冷却周期是不能逃避的一个话题, 由于评估的度量标准是动态特性,副本的数量可能会不断波动。有时被称为颠簸,所以在每次做出扩容缩容后,冷却时间是多少。
- 在 HPA 中,默认的扩容冷却周期是 3 分钟,缩容冷却周期是 5 分钟。
- 可以通过调整 kube-controller-manager 组件启动参数设置冷却时间:
1 | --horizontal-pod-autoscaler-downscale-delay : 扩容冷却 |
1 | pod1 pod2 pod3 # cpu使用率 50% |
HPA 的演进历程
- 目前 HPA 已经支持了 autoscaling/v1、autoscaling/v2beta1 和 autoscaling/v2beta2 三个大版本。
- 目前大多数人比较熟悉是 autoscaling/v1 ,这个版本只支持 CPU 一个指标的弹性伸缩。
- 而 autoscaling/v2beta1 增加了支持自定义指标, 如第三方支持QPS
- autoscaling/v2beta2 又额外增加了外部指标支持。
- 而产生这些变化不得不提的是Kubernetes社区对监控与监控指标的认识与转变。从早期Heapster到Metrics Server再到将指标边界进行划分,一直在丰富监控生态。
1 | 1. autoscaling/v1版本 只暴露了cpu 为什么没有暴露内存 ? 因为内存不是很好的提现弹性伸缩的指标,都是应用在调整 |
基于 CPU 指标缩放
Kubernetes API Aggregation
- 在 Kubernetes 1.7 版本引入了聚合层,允许第三方应用程序通过将自己注册到kube-apiserver上,仍然通过 API Server 的 HTTP URL 对新的 API 进行访问和操作。
- 为了实现这个机制,Kubernetes 在 kube-apiserver 服务中引入了一个 API 聚合层(API Aggregation Layer),用于将扩展 API 的访问请求转发到用户服务的功能。
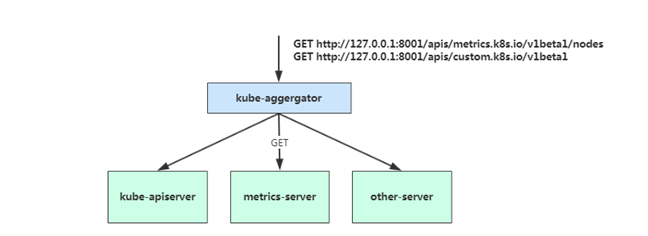
- 当你访问 apis/metrics.k8s.io/v1beta1 的时候,实际上访问到的是一个叫作 kube-aggregator 的代理。而 kube-apiserver,正是这个代理的一个后端;而 Metrics Server,则是另一个后端 。
- 通过这种方式,我们就可以很方便地扩展 Kubernetes 的 API 了。
- 如果你使用kubeadm部署的,默认已开启。
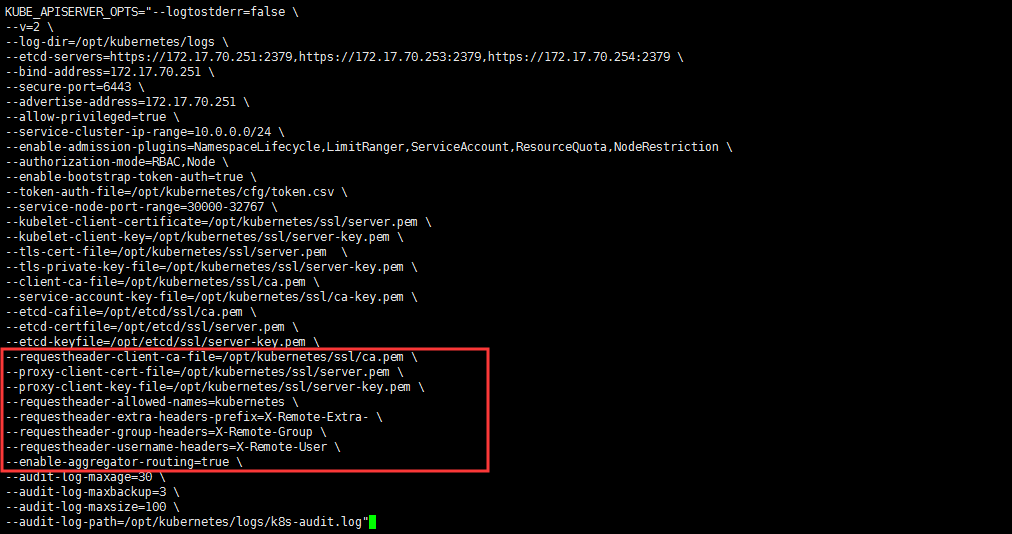
- 如果你使用二进制方式部署的话,需要在kube-APIServer中添加启动参数,增加以下配置:
1 | # vi /opt/kubernetes/cfg/kube-apiserver.conf |
- 在设置完成 重启 kube-apiserver 服务,就启用 API 聚合功能了。
开启 kube-apiserver 聚合层
1 | [root@k8s-master1 ~]# vim /opt/kubernetes/cfg/kube-apiserver.conf |
autoscaling/v1(CPU指标实践)
部署 Metrics Server
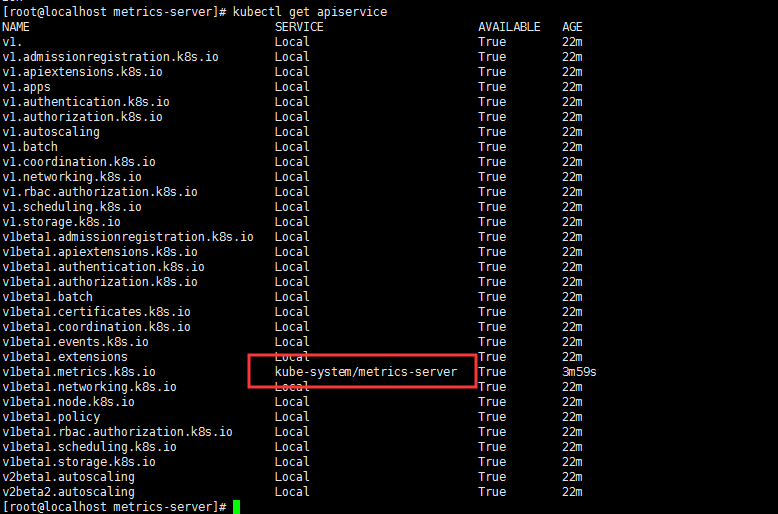
- Metrics Server 是一个集群范围的资源使用情况的数据聚合器。作为一个应用部署在集群中。
- Metrics Server 从每个节点上Kubelet(内置的cadvisor)公开的摘要API收集指标。
- Metrics Server 通过Kubernetes聚合器注册在Master APIServer中。
1 | HPA |
1 | [root@k8s-master1 ~]# yum install lrzsz unzip |
1 | # 获取资源利用率 metrics-server 工作正常 采集到了数据 |
1 | # 可通过Metrics API在Kubernetes中获得资源使用率指标,例如容器CPU和内存使用率。这些度量标准既可以由用户直接访问 |
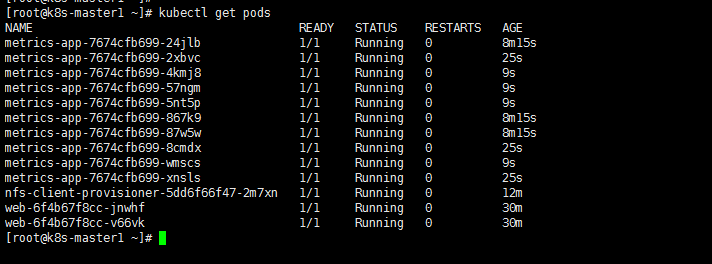
启动三个web副本
1 | [root@k8s-master1 hpa]# mkdir -p /root/hpa |
1 | [root@k8s-master1 hpa]# kubectl delete deploy web |
创建 HPA 策略
1 | # 自动创建 |
1 | # 创建并查看 需要等待一小会 hpa会去调用api汇总web的使用率 |
1 | # 长时间没有利用率 帮我们缩容了 |
1 | # 开启压测 |
工作流程:hpa -> apiserver -> kube aggregation -> metrics-server -> kubelet(cadvisor)
autoscaling/v2beta2(多指标)
- 为满足更多的需求,HPA 还有 autoscaling/v2beta1 和 autoscaling/v2beta2 两个版本。
- 这两个版本的区别是 autoscaling/v1beta1支持了 Resource Metrics(CPU)和 Custom Metrics(应用程序指标),
- 而在 autoscaling/v2beta2的版本中额外增加了 External Metrics 的支持。
1 | # v2版本支持 自定义指标 ,可以对接第三方监控的指标 |
1 | # 自动生成 |
1 | metrics中的type字段有四种类型的值:Object、Pods、Resource、External。 |
工作流程:hpa -> apiserver -> kube aggregation -> metrics-server -> kubelet(cadvisor)
工作流程:hpa -> apiserver -> kube aggregation -> prometheus-adapter -> prometheus -> pods
1 | prometheus-adapter 完成注册 和 数据格式的转换 |
基于 Prometheus 自定义指标缩放
- 资源指标只包含CPU、内存,一般来说也够了。但如果想根据自定义指标:如请求qps/5xx错误数来实现HPA,就需要使用自定义指标了,
- 目前比较成熟的实现是 Prometheus Custom Metrics。
- 自定义指标由Prometheus来提供,再利用k8s-prometheus-adpater聚合到apiserver,实现和核心指标(metric-server)同样的效果。

Prometheus 介绍
- Prometheus(普罗米修斯)是一个最初在SoundCloud上构建的监控系统。自2012年成为社区开源项目,拥有非常活跃的开发人员和用户社区。
- 为强调开源及独立维护,Prometheus于2016年加入云原生云计算基金会(CNCF),成为继Kubernetes之后的第二个托管项目。
Prometheus 特点:
多维数据模型:由度量名称和键值对标识的时间序列数据
PromSQL:一种灵活的查询语言,可以利用多维数据完成复杂的查询
不依赖分布式存储,单个服务器节点可直接工作
基于HTTP的pull方式采集时间序列数据
推送时间序列数据通过PushGateway组件支持
通过服务发现或静态配置发现目标
多种图形模式及仪表盘支持(grafana)
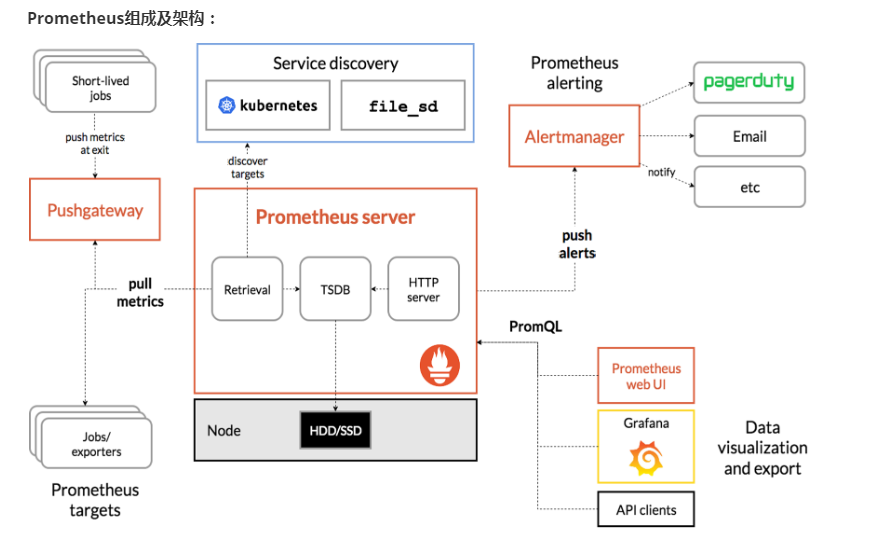
Prometheus Server:收集指标和存储时间序列数据,并提供查询接口
ClientLibrary:客户端库
Push Gateway:短期存储指标数据。主要用于临时性的任务
Exporters:采集已有的第三方服务监控指标并暴露metrics
Alertmanager:告警
Web UI:简单的Web控制台
Prometheus 部署
1 | # 只需要部署服务端 |
- 部署nfs自动供给
1 | # 安装nfs |
- 安装 Prometheus
1 | [root@k8s-master1 prometheus]# kubectl apply -f prometheus-rbac.yaml # 授权 |

1 | # 自定义指标逻辑很负载 做的不是很多 |
部署一个监控应用
1 | [root@k8s-master1 hpa]# vim metrics-app.yaml |
1 | [root@k8s-master1 hpa]# kubectl apply -f metrics-app.yaml |
查看监控指标
1 | [root@k8s-master1 hpa]# curl 10.0.0.36 |
查看采集数据
1 | # 1. 暴露指标 |
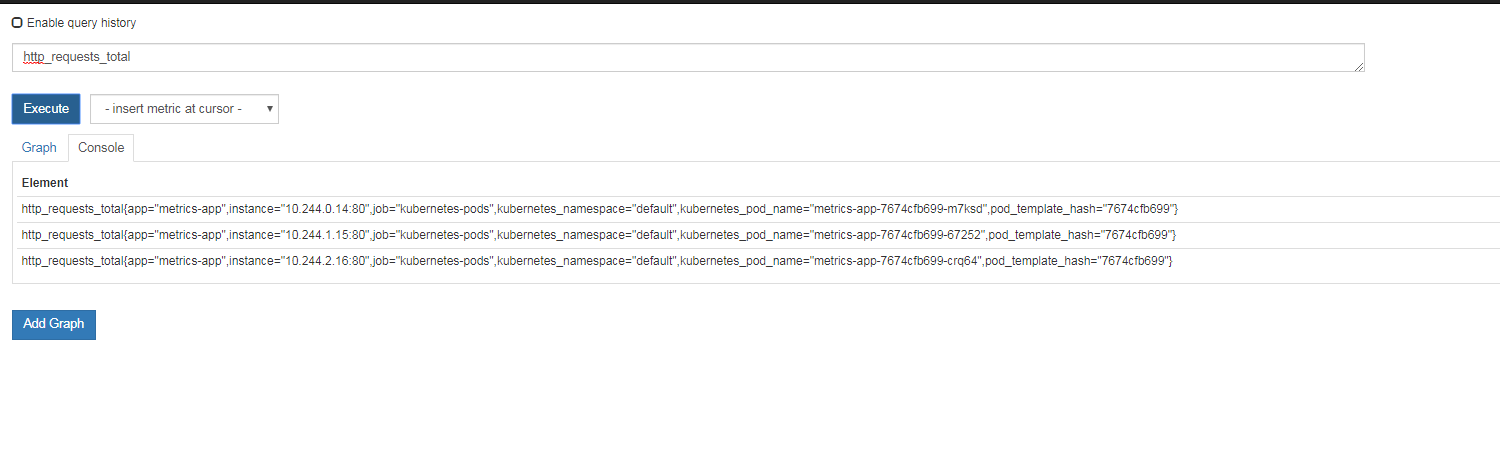
部署 Custom Metrics Adapter
1 | # 先准备下helm环境: |
1 | [root@k8s-master1 ~]# helm repo list |
1 | # 确保适配器注册到APIServer |
创建 HPA 策略
1 |
|
1 | [root@k8s-master1 hpa]# kubectl get hpa |
配置适配器收集特定的指标
- 用来数据转换
1 | # 该规则将http_requests在2分钟的间隔内收集该服务的所有Pod的平均速率。 |
1 | # 重启pod加载生效 |
1 | # 再测试数据 |
1 | [root@k8s-master1 hpa]# ab -n 100000 -c 100 http://10.0.0.136/metrics |
对接一个应用需要做哪些事
1 | # 总结 |