
K8S 监控方案
两种监控方案
1 | 1. cAdvisor+Heapster+InfluxDB+Grafana |
- 对于非容器化业务来说,像Zabbix,open-falcon已经在企业深入使用。
- 而Prometheus新型的监控系统的兴起来源容器领域,所以重点是放在怎么监控容器。随着容器化大势所趋,如果传统技术不随着改变,将会被淘汰,基础架构也会发生新的技术栈组合。
cAdvisor+Heapster+InfluxDB+Grafana
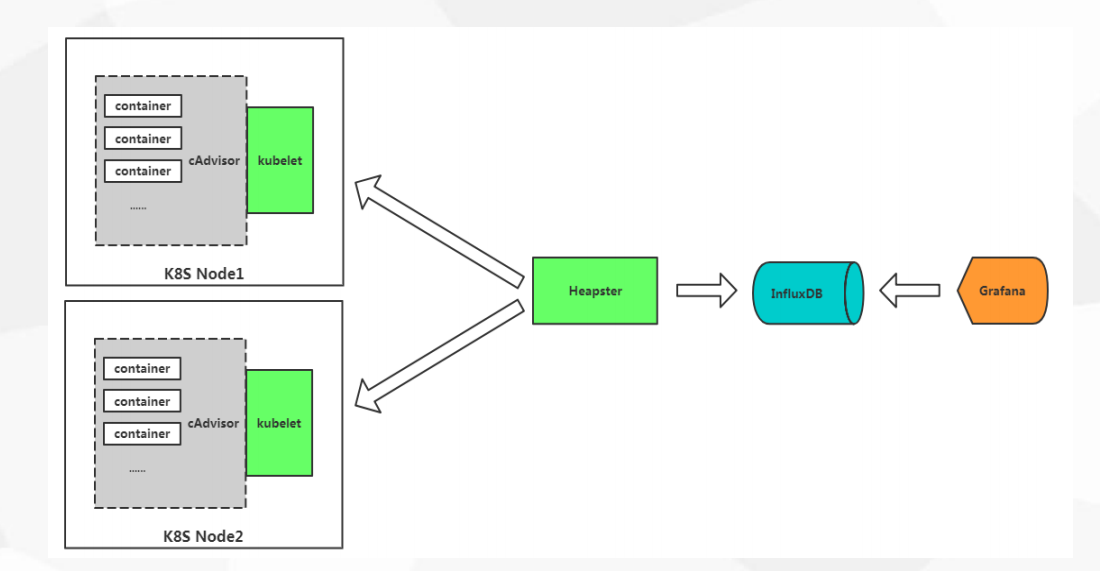
1 | 1. cAdvisor 采集所有容器的性能指标,与kubelet集成 |
cAdvisor/exporter+Prometheus+Grafana
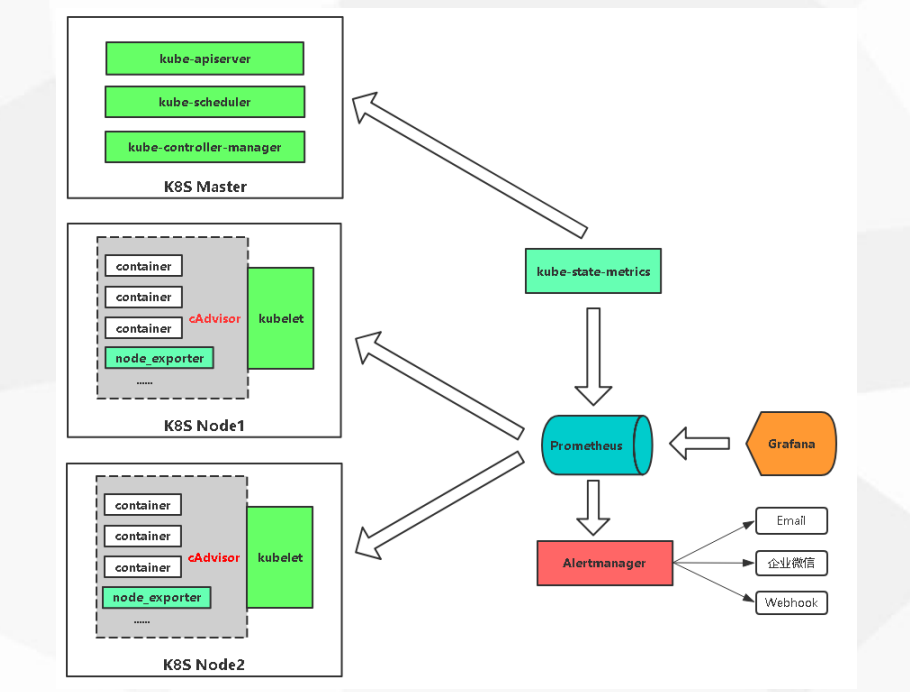
1 | 1. cAdvisor 采集容器性能指标 |
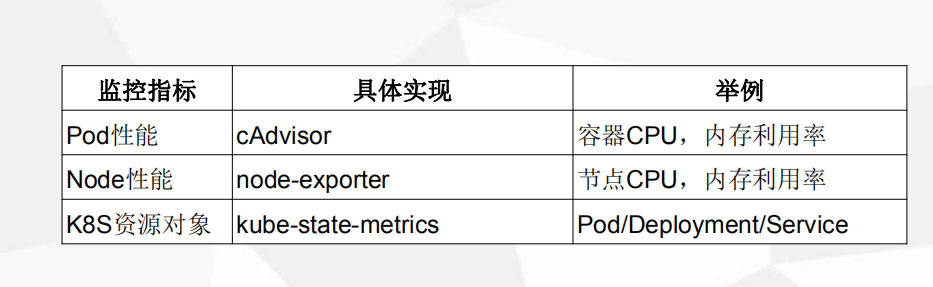
K8S 监控指标
Kubernetes本身监控
- Node资源利用率
- Node数量
- Pods数量(Node) • 资源对象状态• Node资源利用率
- Node数量
- Pods数量(Node) • 资源对象状态
Pod监控
- Pod数量(项目)
- 容器资源利用率
- 应用程序
实现思路
- k8s中的pod都是动态创建的,不能每次都在Prometheus配置文件中去写
- 所有要使用服务发现
- k8s的服务发现是从 k8sapi中发现目标 ,并且获取当前状态,随着pod的生命周期采集数据
1 | 服务发现: |
在 K8S 中部署 Prometheus
准备工作
1 | 1. k8s集群 |
1 | [root@k8s-master1 opt]# unzip prometheus-k8s\ .zip |
1 | # k8s 基础组件 |
1 | # nfs pv自动供给 |
1 | [root@k8s-master1 prometheus-k8s]# kubectl get sc |
k8s 部署 prometheus
1 | # rbac 访问kubeapi授权,无需变动 |
1 | # prometheus-statefulset.yaml 有状态部署 |
1 | # 部署: |
基于 K8S 服务发现的配置解析
1 | # 用于修改 configmap 后 重新加载 |
1 | # 进入容器 查看配置文件 |
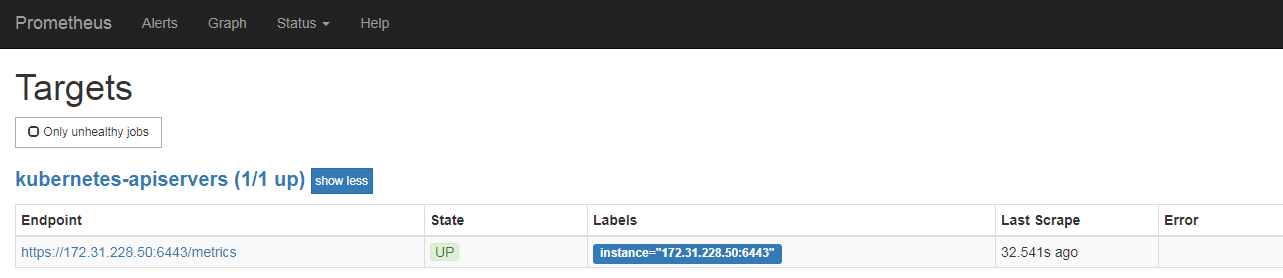
1 | # kubelet的服务端口是 10250 |
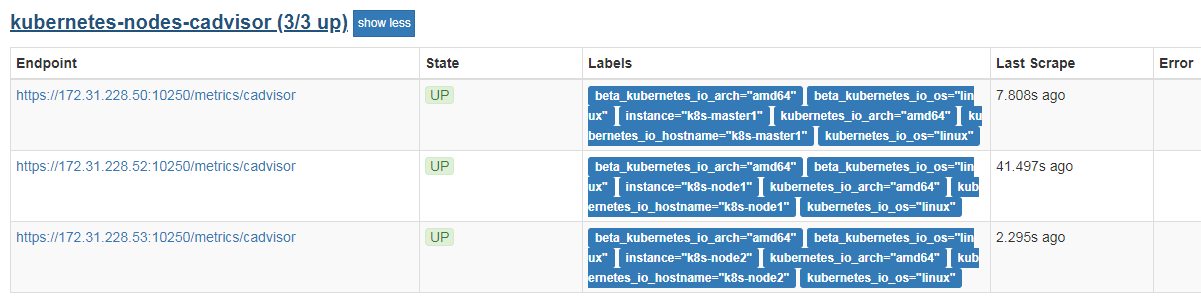
1 | - job_name: kubernetes-service-endpoints |
监控 K8S 集群中Pod
- kubelet的节点使用cAdvisor提供的metrics接口获取该节点所有容器相关的性能指标数据
- cAdvisor 已经集成到 kubelet 中
1 | 暴露接口地址: |
在 K8S中部署 Grafana
- Grafana是一个开源的度量分析和可视化系统。
- Grafana 也部署在 k8s 集群内
1 | 官网:https://grafana.com/grafana/download |
1 | [root@k8s-master1 prometheus-k8s]# kubectl apply -f grafana.yaml |
监控K8S集群Node
- node_exporter:用于*NIX系统监控,使用Go语言编写的收集器。
- node_exporter 在k8s中使用DaemonSet方式部署,每个node都会启动一个收集器
- 本次收集不通过yaml方式部署 yaml方式局限于数据获取不到,挂载麻烦
- 每台node节点都需要部署
1
2
3使用文档:https://prometheus.io/docs/guides/node-exporter/
GitHub:https://github.com/prometheus/node_exporter
exporter列表:https://prometheus.io/docs/instrumenting/exporters/
1 | # 部署脚本 |
1 | # 测试访问 |
1 | # 接入监控 修改配置文件 |

1 | # 导入模板: K8S Node监控 :9276 |
100 - (avg(irate(node_cpu_seconds_total{instance=~”$node”,mode=”idle”}[1m])) * 100)
监控 K8S 资源对象与Grafana可视化
1 | kube-state-metrics采集了k8s中各种资源对象的状态信息: |
1 | [root@k8s-master1 prometheus-k8s]# kubectl apply -f kube-state-metrics-rbac.yaml |
1 | # 导入模板 k8s 资源对象状态监控 :6417 |
在 K8S中部署 Alertmanager
- 部署Alertmanager
- 配置Prometheus与Alertmanager通信
- 配置告警
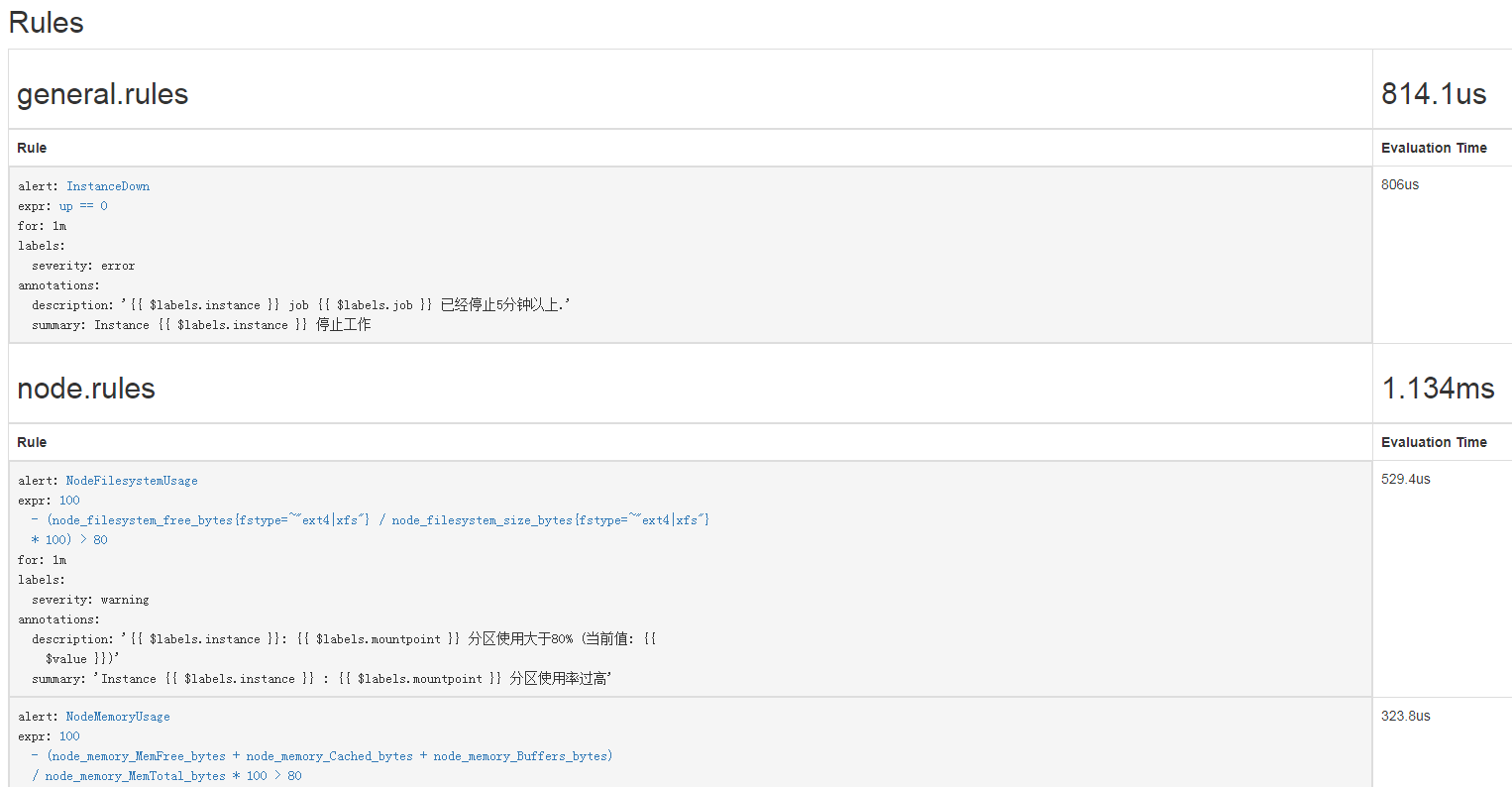
1 | 1. prometheus指定rules目录 |
1 | [root@k8s-master1 prometheus-k8s]# kubectl apply -f alertmanager-configmap.yaml |
1 | [root@k8s-master1 prometheus-k8s]# kubectl get pods,svc -n kube-system |
配置 Prometheus 与 Alertmanager 通信
[root@k8s-master1 prometheus-k8s]# vim prometheus-configmap.yaml
1 | alerting: |
配置告警
- prometheus指定rules目录
1 | [root@k8s-master1 prometheus-k8s]# vim prometheus-configmap.yaml |
configmap存储告警规则
1 | # 测试告警规则 无需修改 |
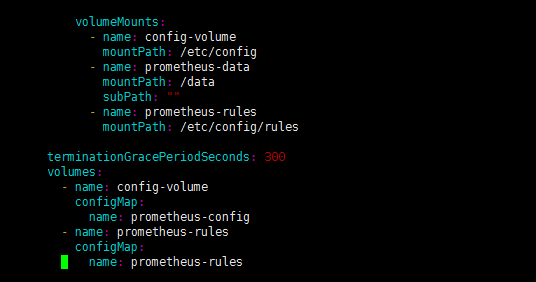
configmap挂载到容器rules目录
1 | [root@k8s-master1 prometheus-k8s]# kubectl apply -f prometheus-rules.yaml |
增加alertmanager告警配置
1 | [root@k8s-master1 prometheus-k8s]# vim alertmanager-configmap.yaml |

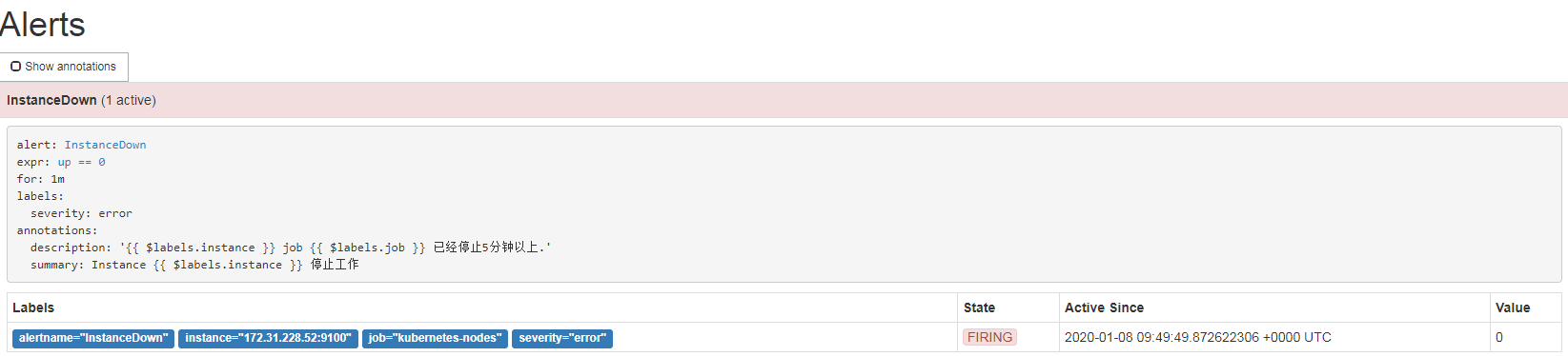
1 | # 关闭一个node_exporter 看看是否告警 |

小结
- 标签重要性(环境,部门,项目,管理者)
- Grafana灵活
- PromSQL
- 利用服务发现动态加入目标
下一步计划:Prometheus集群, PromSQL, Grafana,对业务监控