
Ceph 介绍
为什么要用 Ceph
- Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs)。
- Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。
- 目前也是OpenStack的主流后端存储,随着OpenStack在云计算领域的广泛使用,ceph也变得更加炙手可热。
- 国内目前使用ceph搭建分布式存储系统较为成功的企业有x-sky,深圳元核云,上海UCloud等三家企业。
- Ceph设计思想:集群可靠性、集群可扩展性、数据安全性、接口统一性、充分发挥存储设备自身的计算能力、去除中心化。
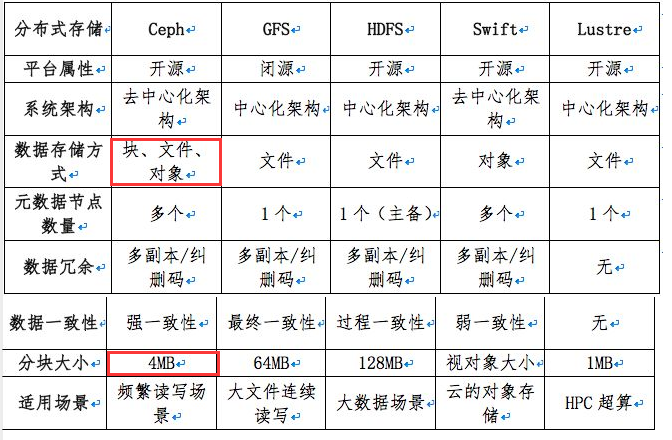
Ceph 架构介绍
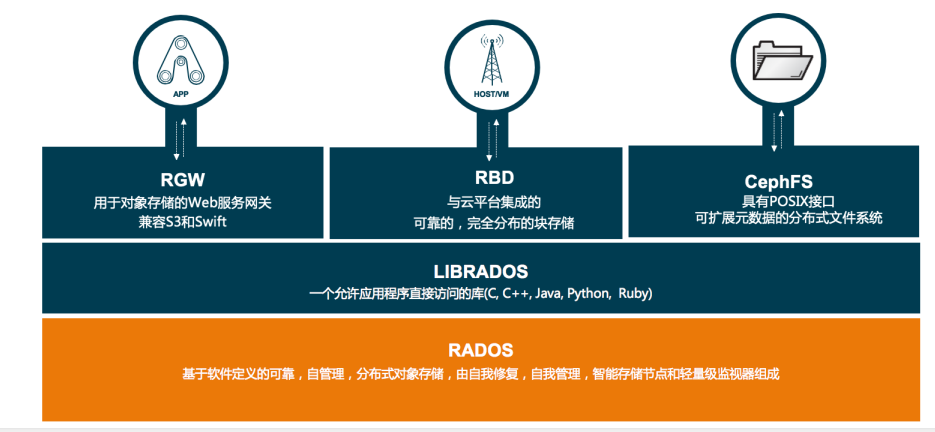
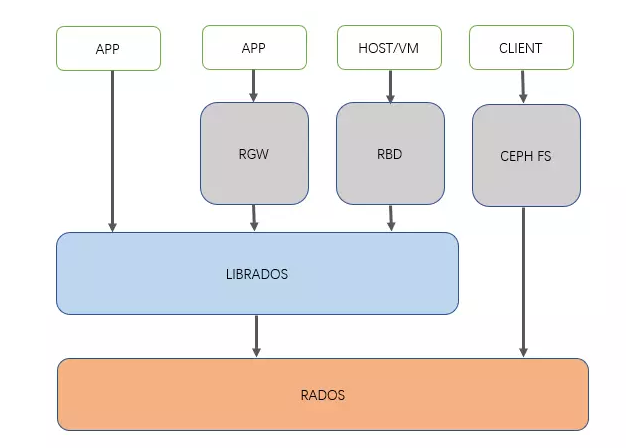
- Ceph使用RADOS提供对象存储,通过librados封装库提供多种存储方式的文件和对象转换。
- 外层通过RGW(Object,有原生的API,而且也兼容Swift和S3的API,适合单客户端使用)、RBD(Block,支持精简配置、快照、克隆,适合多客户端有目录结构)、CephFS(File,Posix接口,支持快照,适合更新变动少的数据,没有目录结构不能直接打开)将数据写入存储。
1 | - 高性能 |
Ceph 核心概念
RADOS
- 全称Reliable Autonomic Distributed Object Store,即可靠的、自动化的、分布式对象存储系统。
- RADOS是Ceph集群的精华,用户实现数据分配、Failover等集群操作。
Librados
- Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的。
- 目前提供PHP、Ruby、Java、Python、C和C++支持。
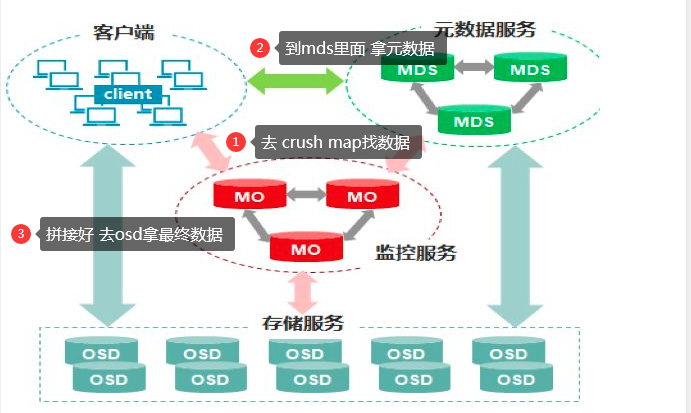
Crush
- Crush算法是Ceph的两大创新之一,通过Crush算法的寻址操作,Ceph得以摒弃了传统的集中式存储元数据寻址方案。
- 而Crush算法在一致性哈希基础上很好的考虑了容灾域的隔离,使得Ceph能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
- 同时,Crush算法有相当强大的扩展性,理论上可以支持数千个存储节点,这为Ceph在大规模云环境中的应用提供了先天的便利。
1 | 1. Crush 算法 数据平均分配到各个节点上,访问的时候把数据拼起来获取 |
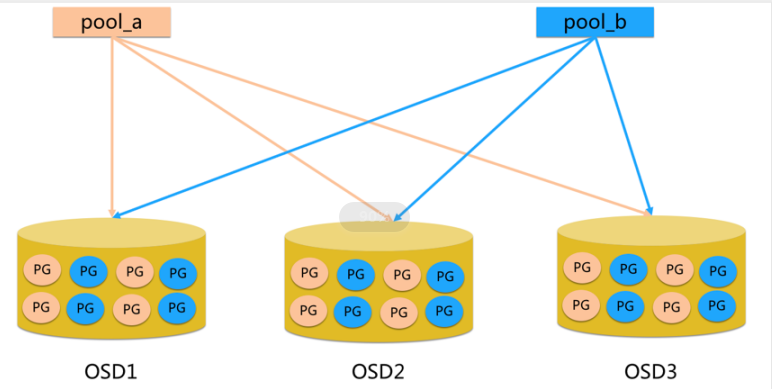
Pool
- Pool是存储对象的逻辑分区,它规定了数据冗余的类型和对应的副本分布策略(默认3副本 )。
- 支持两种类型:副本(replicated)和 纠删码( Erasure Code)
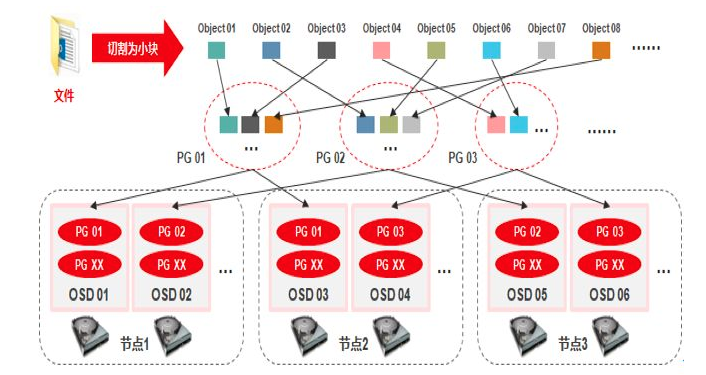
PG
- PG( placement group)是一个放置策略组,它是对象的集合,该集合里的所有对象都具有相同的放置策略。
- 简单点说就是相同PG内的对象都会放到相同的硬盘上,PG是ceph的逻辑概念,服务端数据均衡和恢复的最小粒度就是PG。
- 一个PG包含多个OSD,引入PG这一层其实是为了更好的分配数据和定位数据;
Object
- 简单来说块存储读写快,不利于共享,文件存储读写慢,利于共享。
- 能否弄一个读写快,利于共享的出来呢。于是就有了对象存储。最底层的存储单元,包含元数据和原始数据。
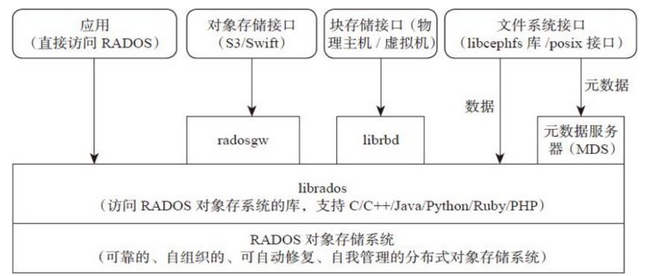
Ceph 核心组件
OSD
- OSD是负责物理存储的进程,一般配置成和磁盘一一对应,一块磁盘启动一个OSD进程。
- 主要功能是存储数据、复制数据、平衡数据、恢复数据,以及与其它OSD间进行心跳检查,负责响应客户端请求返回具体数据的进程等;
1 | # Pool、PG和OSD的关系: |
Monitor
- 1个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据。
- 负责坚实整个Ceph集群运行的Map视图(如OSD Map、Monitor Map、PG Map和CRUSH Map),维护集群的健康状态,维护展示集群状态的各种图表,管理集群客户端认证与授权;
- Monitor生产上至少3个组成高可用。
- 定期探测组件的健康状态。
1 | 1. osd想要什么数据 去 Monitor 里的 OSD Map 里面获取 |
MDS
- MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
- 负责保存文件系统的元数据,管理目录结构。
- 对象存储和块设备存储不需要元数据服务;
Mgr
- ceph 官方开发了 ceph-mgr,主要目标实现 ceph 集群的管理,为外界提供统一的入口。
- 例如 cephmetrics、zabbix、calamari、promethus。
- Mgr可以作为主从模式,挂了不影响集群使用。
RGW
- RGW 全称RADOS gateway,是Ceph对外提供的对象存储服务,接口与S3和Swift兼容。
Admin
- Ceph常用管理接口通常都是命令行工具,如rados、ceph、rbd等命令 。
- 另外Ceph还有可以有一个专用的管理节点,在此节点上面部署专用的管理工具来实现近乎集群的一些管理工作,如集群部署,集群组件管理等。
Ceph 三种存储类型
块存储(RBD)
1 | - 优点: |
文件存储(CephFS)
1 | - 优点: |
对象存储(Object)(适合更新变动较少的数据)
1 | - 优点: |
io ceph 流程
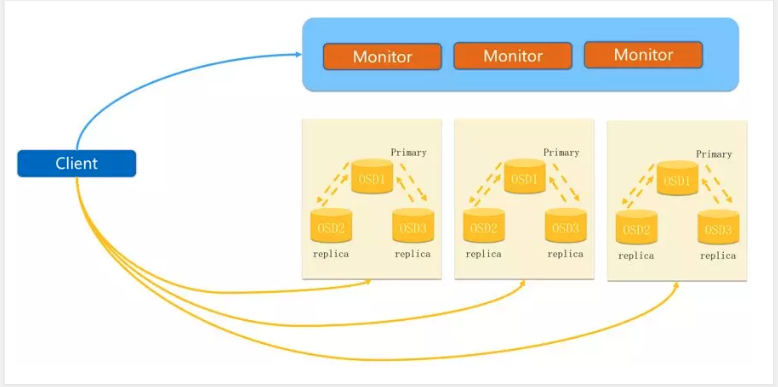
- client 访问 Monitor map 拿数据
- 然后去OSD去找文件,OSD里面有主从概念,主提供服务,副本不做改动,通过盘符标识(SSD/HDD),分配主从节点。
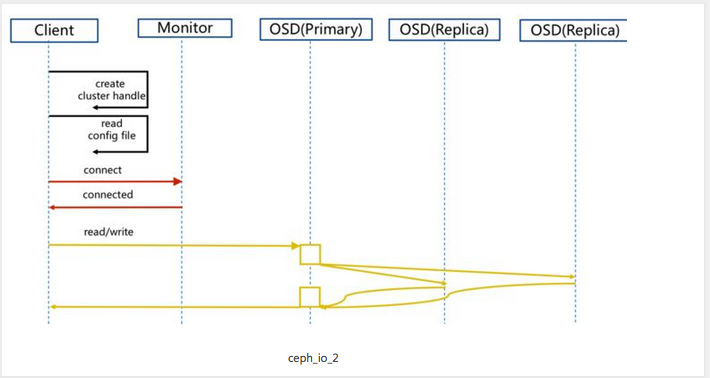
- 读数据 流程到返回
- 写数据 强一致性,主副本先写,写完后同步从副本,三个副本之间通信数据一致后,数据才可以继续读取
小总结
- 为什么用ceph: 可扩展,节省成本,支持接口多
- 架构:分布式架构,多接口,RADOS -> Librados -> RGW,RBD,CephFS ,每个组件分布式,数据也是分布式
- 三种存储类型: RBD(块存储),CephFS(文件存储),对象存储(object)
Ceph 集群部署
Ceph 版本选择
- 官网安装 最新版本
- 手动安装 内网yum源 安装指定版本
Ceph版本来源介绍
- Ceph 社区最新版本是 14,而 Ceph 12 是市面用的最广的稳定版本。
- 第一个 Ceph 版本是 0.1 ,要回溯到 2008 年 1 月。
- 多年来,版本号方案一直没变,直到 2015 年 4 月 0.94.1 ( Hammer 的第一个修正版)发布后,为了避免 0.99 (以及 0.100 或 1.00 ?),制定了新策略。
1 | x.0.z - 开发版(给早期测试者和勇士们) |
| 版本名称 | 版本号 | 发布时间 |
|---|---|---|
| Argonaut | 0.48版本(LTS) | 2012年6月3日 |
| Bobtail | 0.56版本(LTS) | 2013年5月7日 |
| Cuttlefish | 0.61版本 | 2013年1月1日 |
| Dumpling | 0.67版本(LTS) | 2013年8月14日 |
| Emperor | 0.72版本 | 2013年11月9 |
| Firefly | 0.80版本(LTS) | 2014年5月 |
| Giant | Giant | October 2014 - April 2015 |
| Hammer | Hammer | April 2015 - November 2016 |
| Infernalis | Infernalis | November 2015 - June 2016 |
| Jewel | 10.2.9 | 2016年4月 |
| Kraken | 11.2.1 | 2017年10月 |
| Luminous | 12.2.12 | 2017年10月 |
| mimic | 13.2.7 | 2018年5月 |
| nautilus | 14.2.5 | 2019年2月 |
1 | # 本次实验 nautilus |
Luminous 新版本特性
1. Bluestore
1 | 1. ceph-osd的新后端存储BlueStore已经稳定,是新创建的OSD的默认设置。 |
安装前准备
1 | # 我自己重新创建了3台 阿里云主机 |
1 | (1)关闭防火墙: |
安装内网yum源
这一步有问题 直接用下面的 阿里云源
1. 安装httpd、createrepo 和 epel源
1 | yum install httpd createrepo epel-release -y |
2. 编辑yum源文件
1 | [root@cephnode01 ~]# vim /etc/yum.repos.d/ceph.repo |
3. 下载Ceph 相关rpm包
1 | [root@cephnode01 ~]# yum --downloadonly --downloaddir=/var/www/html/ceph/rpm-nautilus/el7/x86_64/ install ceph ceph-radosgw |
4. 下载Ceph依赖文件
1 | # 自作源的时候 要下载这些依赖 |
更新yum源
1 | createrepo --update /var/www/html/ceph/rpm-nautilus |
1 | [root@cephnode01 rpm-nautilus]# systemctl start httpd |
使用阿里云yum源 安装Ceph集群
1. 编辑yum源
- 将yum源同步到其它节点并提前做好 yum makecache
1 | # 三台都操作 |
1 | yum clean all |
2. 安装ceph-deploy(确认ceph-deploy版本是否为2.0.1)
1 | [root@cephnode01 rpm-nautilus]# yum list|grep ceph |
3. 创建一个my-cluster目录
- 所有命令在此目录下进行(文件位置和名字可以随意)
- 生产上按照项目启目录名字也可以,这个是测试用的
1 | mkdir /my-cluster |
4. 创建一个Ceph集群
1 | [root@cephnode01 my-cluster]# ceph-deploy new cephnode01 cephnode02 cephnode03 |
5. 安装Ceph软件(每个节点执行)
1 | [root@cephnode01 my-cluster]# yum -y install epel-release |
6. 生成monitor检测集群所使用的的秘钥
1 | [root@cephnode01 my-cluster]# ceph-deploy mon create-initial |
7. 查看基本配置
1 | [root@cephnode01 my-cluster]# ls -l |
8. 安装Ceph CLI,方便执行一些管理命令
1 | [root@cephnode01 my-cluster]# ceph-deploy admin cephnode01 cephnode02 cephnode03 |
1 | # 其他节点下会生成 |
9. 配置mgr,用于管理集群
1 | [root@cephnode01 my-cluster]# ceph-deploy mgr create cephnode01 cephnode02 cephnode03 |
10. 部署rgw
1 | # 生产上多机器安装 rgw 对象存储 用nginx做负载均衡代理 |
11. 部署MDS(CephFS)
1 | [root@cephnode01 my-cluster]# ceph-deploy mds create cephnode01 cephnode02 cephnode03 |
12. 阿里云购买云盘
- 为每台实例购买云盘,按照分区购买后,挂载到实例上
- 高效云盘,20G,可用区C
1 | [root@cephnode01 my-cluster]# lsblk |
13. 添加osd
1 | # 该命令可以将 裸盘 vdb 自动格式化成ceph BlueStore 认识的格式 |
1 | [root@cephnode01 my-cluster]# ceph osd tree |
1 | # 查看集群状态 |
把其他实例上的盘也加入到集群里
1 | # 别忘记购买啊... |
1 | # 三块盘 每台实例加入一块 |
1 | # 在磁盘不平衡或者新加盘的时候 会出现 WARN状态 |
1 | # 有报错的话 会看到详细报错 |
1 | # 查看pool |
1 | # 查看pg,pg是逻辑概念,磁盘规置 |
添加硬盘业务无感知
- 如果新加盘需要清空再键入
- 最好直接加入裸盘
ceph.conf
1 | # 原始配置文件 |
书写格式
- 该配置文件采用init文件语法,#和;为注释,ceph集群在启动的时候会按照顺序加载所有的conf配置文件。 配置文件分为以下几大块配置。
1 | global: 全局配置。 |
- 配置文件可以从多个地方进行顺序加载,如果冲突将使用最新加载的配置,其加载顺序为。
1 | # 不需要改动 |
- 配置文件还可以使用一些元变量应用到配置文件,如
1 | $cluster: 当前集群名。 |
- ceph.conf 详细参数
1 | # 全局设置 默认接口 不用调整太多 |
Ceph RBD
RBD 介绍
- RBD即RADOS Block Device的简称,RBD块存储是最稳定且最常用的存储类型。
- RBD块设备类似磁盘可以被挂载。
- RBD块设备具有快照、多副本、克隆和一致性等特性,数据以条带化的方式存储在Ceph集群的多个OSD中。
- 如下是对Ceph RBD的理解。
1 | 1. RBD: 就是 Ceph 里的块设备,一个 4T 的块设备的功能和一个 4T 的 SATA 类似,挂载的 RBD 就可以当磁盘用; |
- 块存储本质就是将裸磁盘或类似裸磁盘(lvm)设备映射给主机使用,主机可以对其进行格式化并存储和读取数据,块设备读取速度快但是不支持共享。
1 | 1. ceph可以通过内核模块和librbd库提供块设备支持。 |
- 使用场景:
1 | 1. 云平台(OpenStack做为云的存储后端提供镜像存储) |
RBD 常用命令
| 命令 | 功能 |
|---|---|
| rbd create | 创建块设备映像 |
| rbd ls | 列出 rbd 存储池中的块设备 |
| rbd info | 查看块设备信息 |
| rbd diff | 可以统计 rbd 使用量 |
| rbd map | 映射块设备 |
| rbd showmapped | 查看已映射块设备 |
| rbd remove | 删除块设备 |
| rbd resize | 更改块设备的大小 |
RBD 配置操作
RBD 挂载到操作系统
创建rbd使用的pool
1 | # 32 pg_num 32 pgp_num 随着容量在增加扩容 生产要做规划 |
1 | [root@cephnode01 my-cluster]# ceph osd pool create rbd 32 32 |
创建一个块设备
1 | [root@cephnode01 my-cluster]# rbd create --size 10240 image01 |
查看快设备
1 | [root@cephnode01 my-cluster]# rbd ls |
禁用当前系统内核不支持的feature
1 | [root@cephnode01 my-cluster]# rbd feature disable image01 exclusive-lock, object-map, fast-diff, deep-flatten |
将块设备映射到系统内核
1 | [root@cephnode01 my-cluster]# rbd map image01 |
格式化块设备镜像
1 | [root@cephnode01 my-cluster]# mkfs.xfs /dev/rbd0 |
mount到本地
1 | [root@cephnode01 my-cluster]# mount /dev/rbd0 /mnt |
取消挂载
1 | [root@cephnode01 mnt]# rbd showmapped |
删除RBD块设备
1 | [root@cephnode01 /]# rbd rm image01 |
其他机器需要创建
1 | ceph common k8s会讲到 |
RBD 快照配置
1 | [root@cephnode01 my-cluster]# rbd create --size 10240 image02 |
创建快照
1 | [root@cephnode01 my-cluster]# rbd snap create image02@image02_snap01 |
列出创建的快照
1 | [root@cephnode01 my-cluster]# rbd snap list image02 |
查看快照详细信息
1 | [root@cephnode01 my-cluster]# rbd info image02@image02_snap01 |
克隆快照(快照必须处于被保护状态才能被克隆)
1 | # 保护状态就无法操作了 |
查看快照的children
1 | # 查看快照的子快照 |
去掉快照的parent
1 | # 取消克隆关系 |
恢复快照
1 | # 回滚 一开始有5个文件 一直写 想回滚 |
删除快照
1 | # 取消保护 |
RBD 镜像导出导入
导出RBD镜像
1 | [root@cephnode01 my-cluster]# rbd export image02 /tmp/image02 |
导入RBD镜像
1 | [root@cephnode01 tmp]# rbd ls |
RBD 扩容
1 | [root@cephnode01 tmp]# rbd info image02|grep size |
总结
1 | 1. 把rbd映射到文件系统挂载 |
Ceph 文件系统 CephFS
- Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问.
- Jewel 版本 (10.2.0) 是第一个包含稳定 CephFS 的 Ceph 版本.
- CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问。
- 对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。
CephFS 架构
- 底层是核心集群所依赖的, 包括:
1 | 1. OSDs (ceph-osd): CephFS 的数据和元数据就存储在 OSDs 上 |
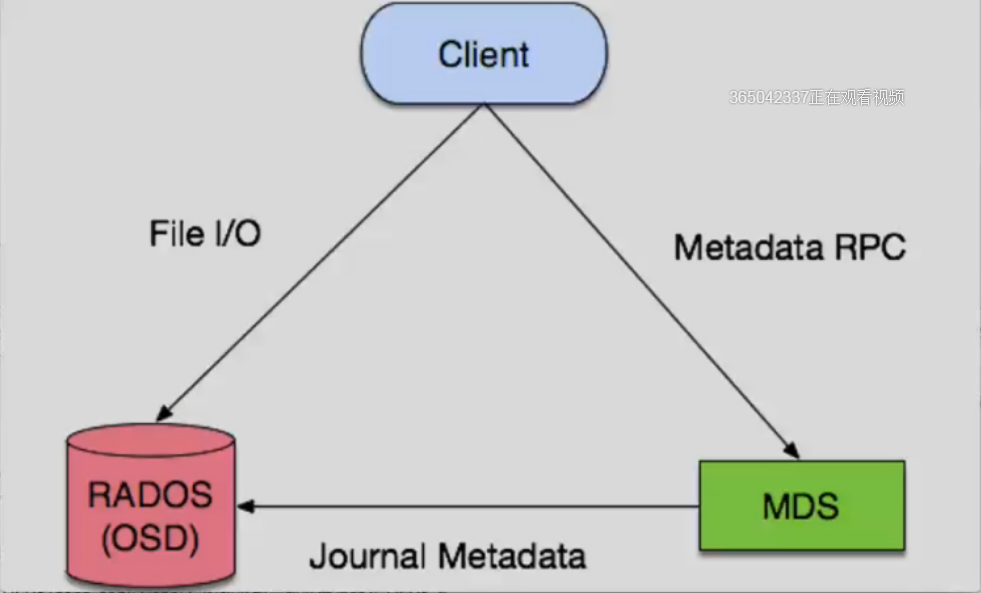
- 数据访问流程
1 | 1. client 访问MDS 获取数据的元数据(文件名,大小等信息) |
配置 CephFS MDS
1 | # 当前集群状态 |
1 | 1. 要使用 CephFS, 至少就需要一个 metadata server 进程。 |
部署 Ceph 文件系统
- 部署一个 CephFS, 步骤如下:
1 | 1. 在一个 Mon 节点上创建 Ceph 文件系统. |
创建一个 Ceph 文件系统
1. CephFS 需要两个 Pools
1 | # cephfs-data 和 cephfs-metadata, 分别存储文件数据和文件元数据 |
1 | [root@cephnode01 my-cluster]# ceph osd pool create cephfs-data 16 16 |
1 | # 注意 |
2. 创建一个 CephFS, 名字为 cephfs
1 | [root@cephnode01 my-cluster]# ceph fs new cephfs cephfs-metadata cephfs-data |
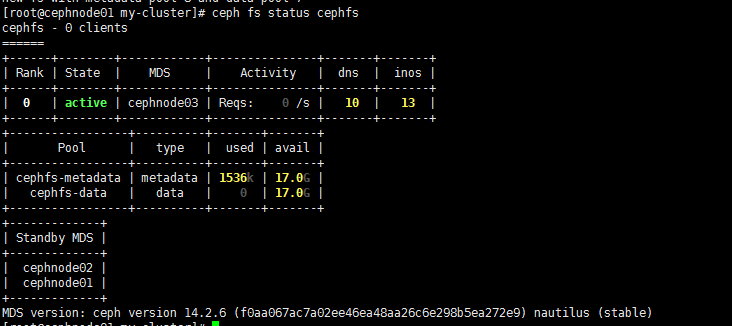
3. 验证至少有一个 MDS 已经进入 Active 状态
1 | [root@cephnode01 my-cluster]# ceph fs status cephfs |
4. 在 Monitor 上, 创建一个用户,用于访问CephFs
1 | [root@cephnode01 my-cluster]# ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rw pool=cephfs-data, allow rw pool=cephfs-metadata' |
5. 验证key是否生效
1 | [root@cephnode01 my-cluster]# ceph auth get client.cephfs |
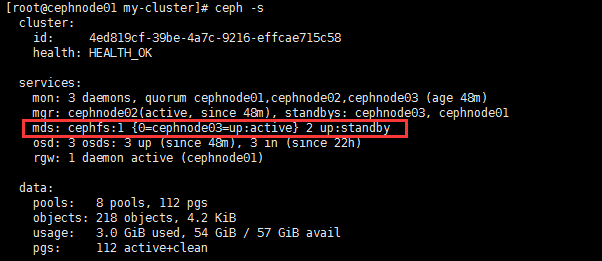
6. 检查CephFs和mds状态
1 | [root@cephnode01 my-cluster]# ceph -s |
挂载 CephFS 文件系统
以 kernel client 形式挂载 CephFS
1 | # 找一台不在集群中的服务器测试挂载 |
1 | # secret 就是刚生成的秘钥 key = AQCluh9eDsknLBAAjxABEQpF8vJeUt8Buk22Dg== |

1 | # 开机自动挂载 |
1 | 4. 验证是否挂载成功 |
以 FUSE client 形式挂载 CephFS
1 | 1. 安装ceph-common |
1 | 2. 安装ceph-fuse |
1 | 3. 将集群的ceph.conf拷贝到客户端 |
1 | 4. 使用 ceph-fuse 挂载 CephFS |

1 | # 验证 CephFS 已经成功挂载 |
1 | # 自动挂载 |
1 | # 卸载 |
存储文件测试并查看
1 | # 在目录下写点东西 |
挂载小总结
1 | # 推荐ceph-fuse 效率更高 |
MDS主备与主主切换
配置主主模式
- 当cephfs的性能出现问题时,就应该配置多个活动的MDS。
- 通常是多个客户机应用程序并行的执行大量元数据操作,并且它们分别有自己单独的工作目录。这种情况下很适合使用多主MDS模式。
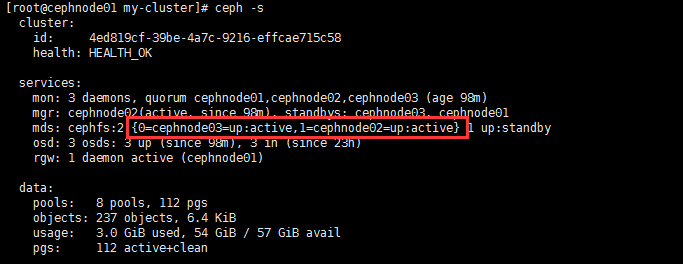
- 配置MDS多主模式
- 每个cephfs文件系统都有一个max_mds设置,可以理解为它将控制创建多少个主MDS。注意只有当实际的MDS个数大于或等于max_mds设置的值时,mdx_mds设置才会生效。
- 例如,如果只有一个MDS守护进程在运行,并且max_mds被设置为两个,则不会创建第二个主MDS。
1 | # 设置完成后 存在两个主 |
配置备用 MDS
- 即使有多个活动的MDS,如果其中一个MDS出现故障,仍然需要备用守护进程来接管。因此,对于高可用性系统,实际配置max_mds时,最好比系统中MDS的总数少一个。
- 但如果你确信你的MDS不会出现故障,可以通过以下设置来通知ceph不需要备用MDS,否则会出现insufficient standby daemons available告警信息:
1 | # 设置不需要备用MDS |
Ceph Dashboard
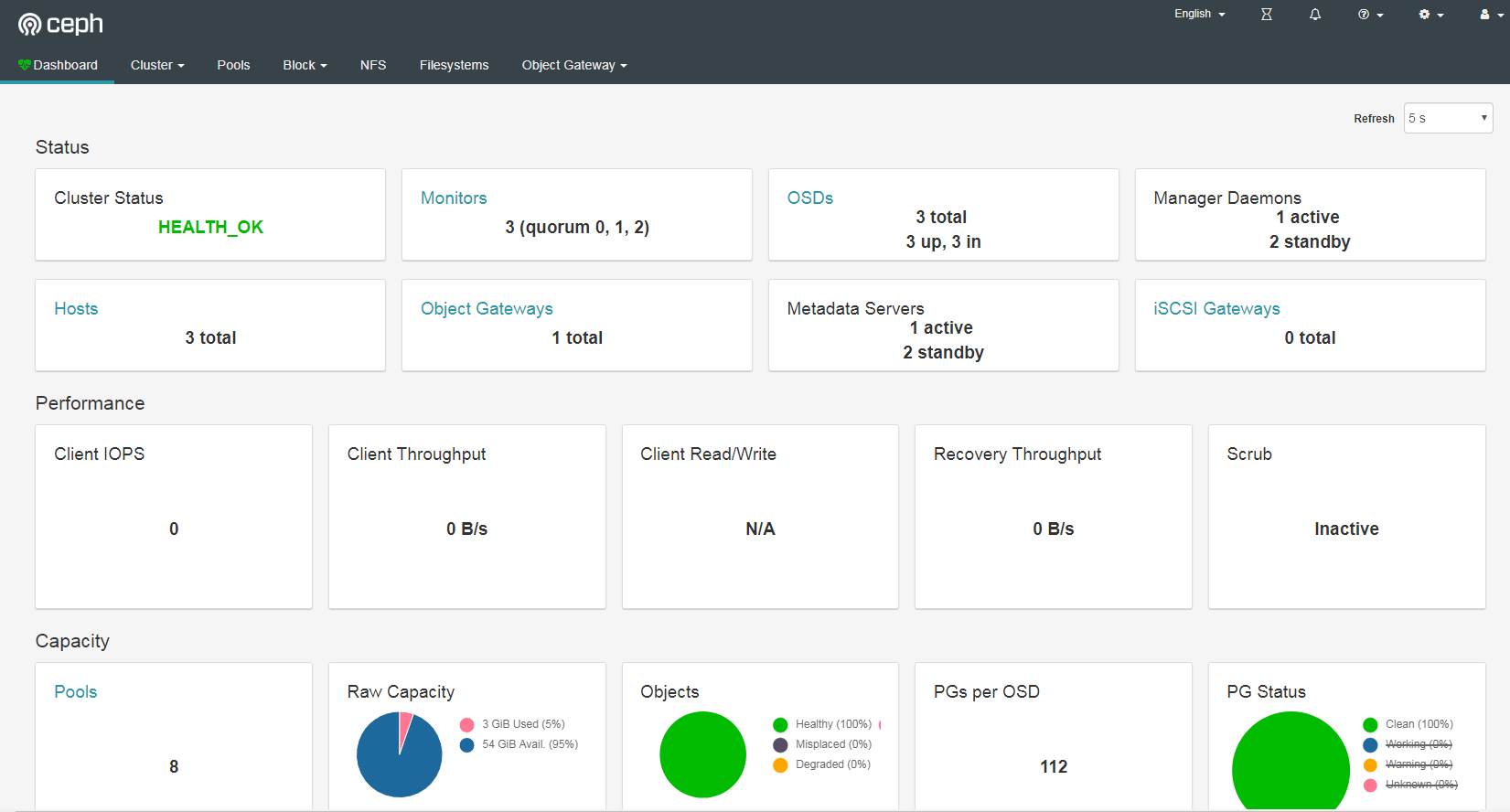
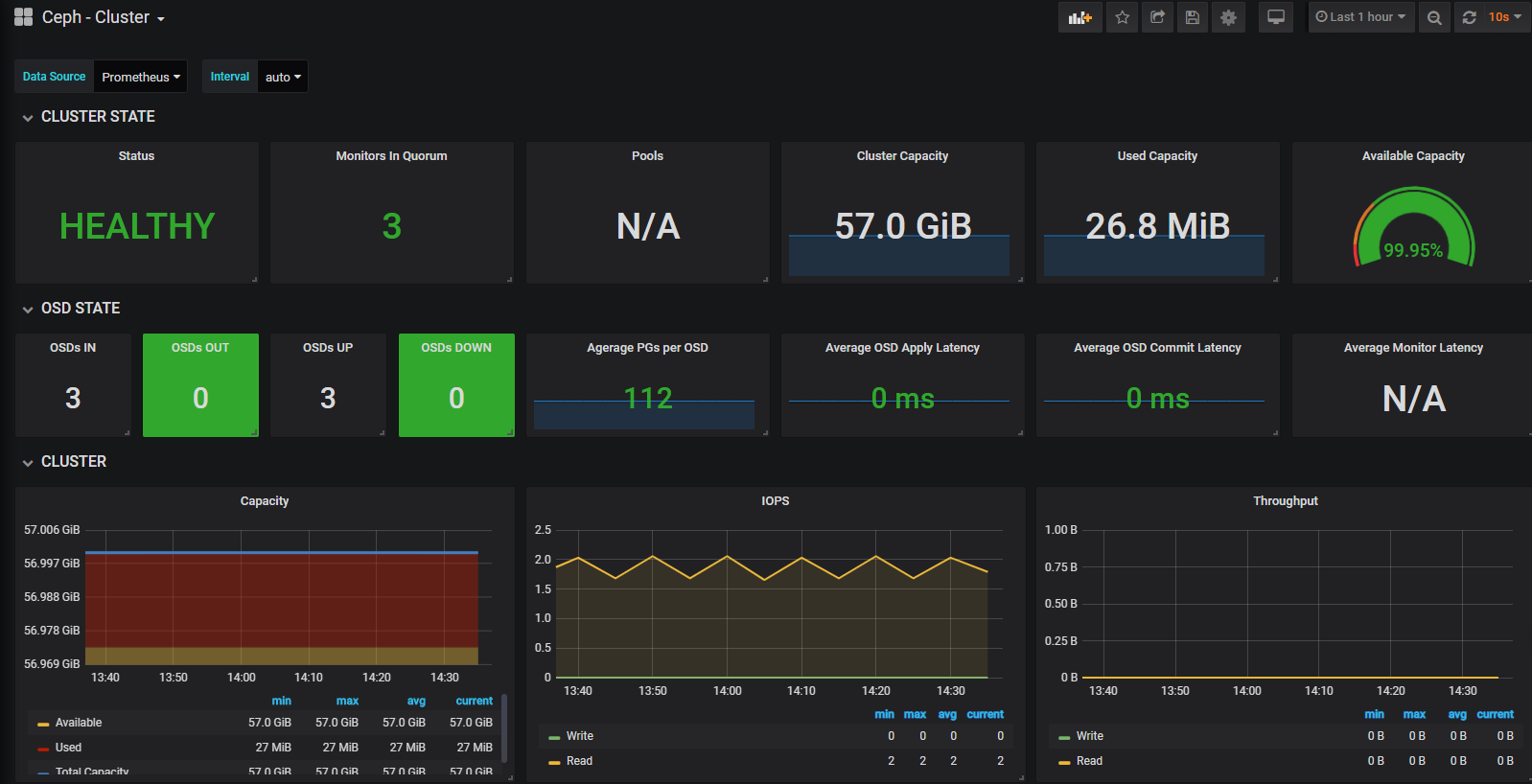
- Ceph 的监控可视化界面方案很多—-grafana、Kraken。但是从Luminous开始,Ceph 提供了原生的Dashboard功能
- 通过Dashboard可以获取Ceph集群的各种基本状态信息。
- mimic版 (nautilus版) dashboard 安装。如果是 (nautilus版) 需要安装 ceph-mgr-dashboard
配置 Ceph Dashboard
1 | 1. 在每个mgr节点安装 |
1 | # 出现问题 ImportError: cannot import name UnrewindableBodyError |
修改默认配置命令
1 | 指定集群dashboard的访问端口 |
开启Object Gateway管理功能
1 | # 这块可能有问题 需要用到对象存储的时候 再网上查查 |
Promethus+Grafana 监控 Ceph
安装 grafana
1 | 1、配置yum源文件 |
安装 promethus
1 | 1、下载安装包,下载地址 |
ceph mgr prometheus插件配置
1 | # ceph mgr module enable prometheus |
配置 promethus
1 | [root@cephnode04 prometheus]# vim /opt/prometheus/prometheus.yml |
1 | # 重启promethus服务 |
1 | # 检查prometheus服务器中是否添加成功 |
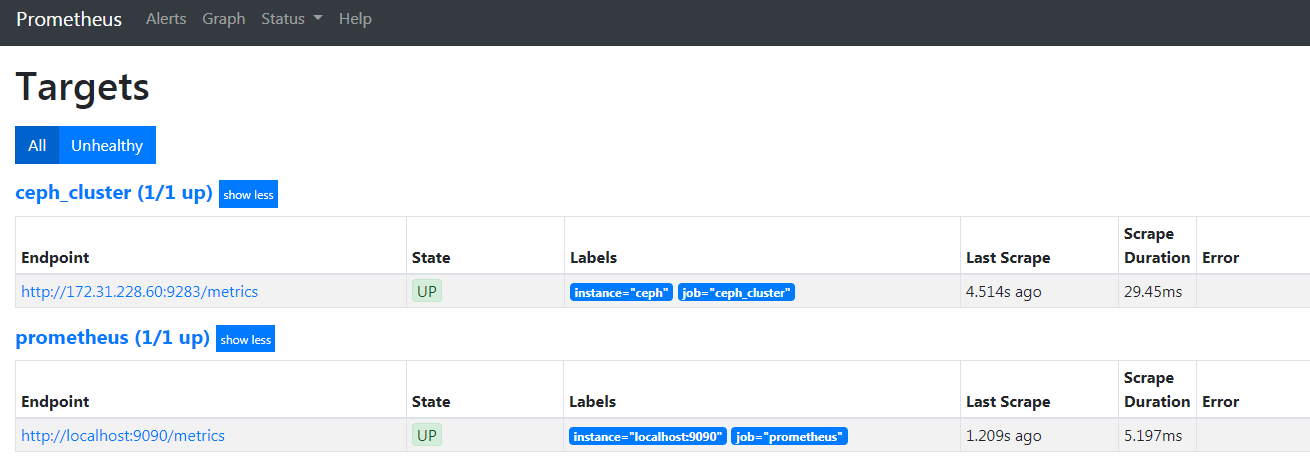
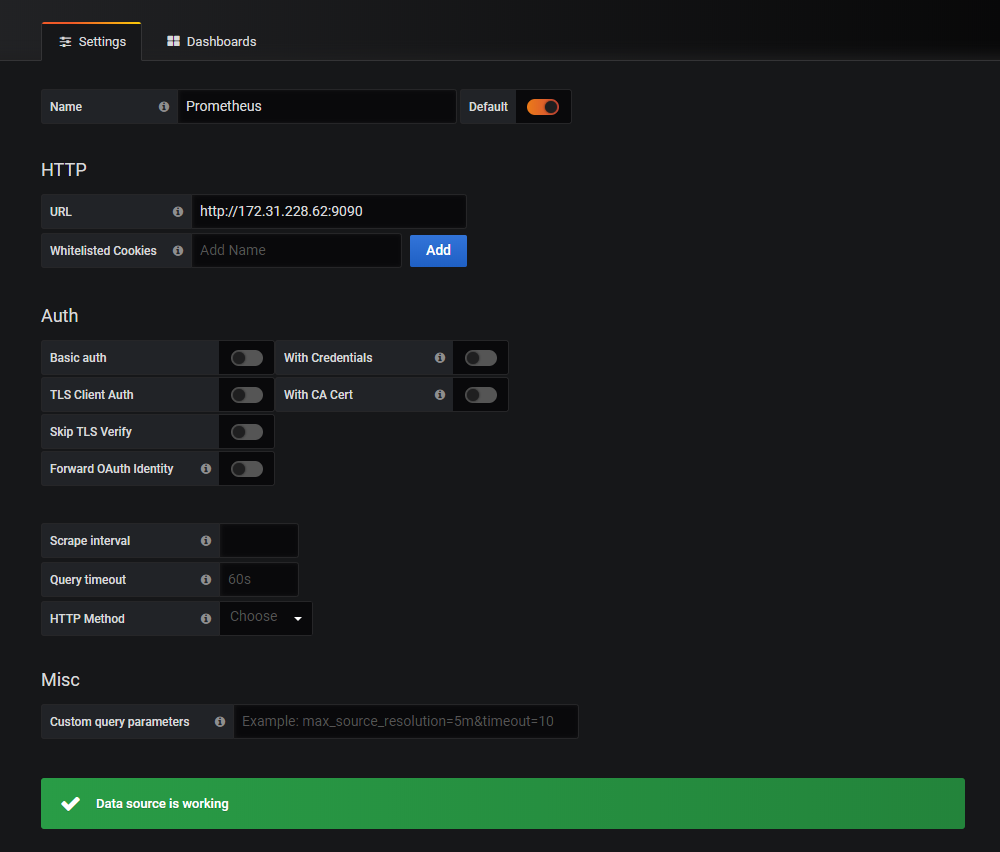
配置 grafana
1 | 1. 浏览器登录 grafana 管理界面 |
K8S 接入 Ceph 存储
PV、PVC 概述
- 管理存储是管理计算的一个明显问题。PersistentVolume子系统为用户和管理员提供了一个API,用于抽象如何根据消费方式提供存储的详细信息。
- 于是引入了两个新的API资源:PersistentVolume和PersistentVolumeClaim
1 | 1. PersistentVolume(PV)是集群中已由管理员配置的一段网络存储。 |
POD 动态供给
- 动态供给主要是能够自动帮你创建pv,需要多大的空间就创建多大的pv。
- k8s帮助创建pv,创建pvc就直接api调用存储类来寻找pv。
- 如果是存储静态供给的话,会需要我们手动去创建pv,如果没有足够的资源,找不到合适的pv,那么pod就会处于pending等待的状态。
- 而动态供给主要的一个实现就是StorageClass存储对象,其实它就是声明你使用哪个存储,然后帮你去连接,再帮你去自动创建pv。
小总结
- pv去存储里申请的一块空间,映射到pv上,作为物理卷存活在容器里
- POD使用pvc联系pv拿到存储
- 动态供给,省却手动创建pv,而是调用StorageClass帮我们去创建
POD 使用 RBD 做为持久数据卷
安装与配置
- RBD支持ReadWriteOnce,ReadOnlyMany两种模式
1 | # 访问模式包括: |
配置 rbd-provisioner
1 | # 配置rbd-provisioner |
1 | [root@k8s-master1 ceph]# kubectl apply -f external-storage-rbd-provisioner.yaml |
配置 storageclass
- 创建pod时,kubelet需要使用rbd命令去检测和挂载pv对应的ceph image,所以要在所有的worker节点安装ceph客户端ceph-common。
- 将ceph的ceph.client.admin.keyring和ceph.conf文件拷贝到所有工作节点的/etc/ceph目录下
1 | [root@k8s-master1 ceph]# vim /etc/yum.repos.d/ceph.repo |
1 | yum -y install ceph-common |
创建 osd pool
1 | [root@cephnode01 my-cluster]# ceph osd pool create kube 16 16 |
创建k8s访问ceph的用户
1 | ceph auth get-or-create client.kube mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=kube' -o ceph.client.kube.keyring |
查看 key
1 | [root@cephnode01 my-cluster]# ceph auth get-key client.admin |
创建 admin secret
1 | kubectl create secret generic ceph-secret --type="kubernetes.io/rbd" \ |
在 default 命名空间创建 pvc 用于访问ceph的 secret
1 | kubectl create secret generic ceph-user-secret --type="kubernetes.io/rbd" \ |
1 | [root@k8s-master1 ceph]# kubectl get secret --all-namespaces |
配置 StorageClass
- 源码中,monitors需要k8s dns解析,我这里使用外部ceph,肯定没有相关解析。
- 所以手动添加解析。
- 而且storageclass配置默认不支持直接修改(只能删除再添加),维护解析比维护storageclass配置要好些。
1 | [root@k8s-master1 ceph]# kubectl create ns ceph |
1 | [root@k8s-master1 ceph]# vim storageclass-ceph-rdb.yaml |
1 | [root@k8s-master1 ceph]# kubectl apply -f storageclass-ceph-rdb.yaml |
测试使用
创建 pvc 测试
1 | cat >ceph-rdb-pvc-test.yaml<<EOF |
1 | [root@k8s-master1 ceph]# kubectl apply -f ceph-rdb-pvc-test.yaml |
1 | [root@k8s-master1 ceph]# kubectl describe pvc ceph-rdb-claim |
创建 nginx pod 挂载测试
1 | cat >nginx-pod.yaml<<EOF |
1 | [root@k8s-master1 ceph]# kubectl apply -f nginx-pod.yaml |
1 | # 修改文件内容 |
1 | # 清理 |
POD 使用 CephFS 做为持久数据卷
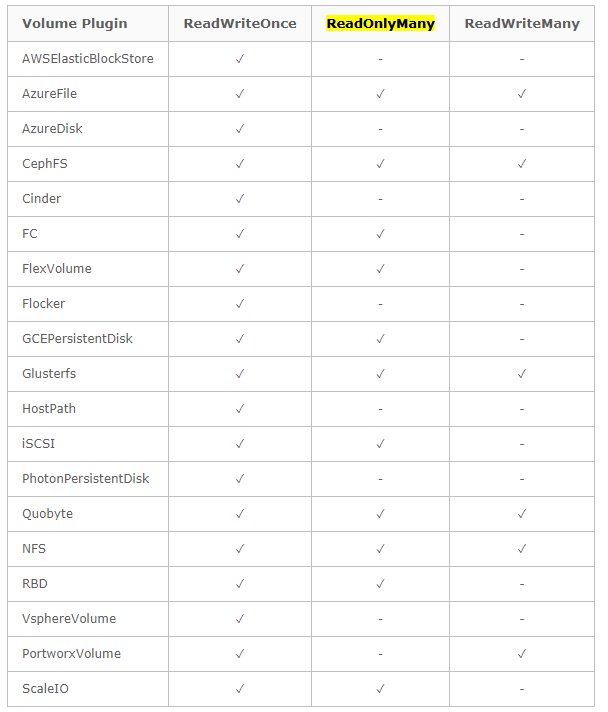
- CephFS方式支持k8s的pv的3种访问模式ReadWriteOnce,ReadOnlyMany ,ReadWriteMany
1 | 访问模式包括: |
- Pod挂载cephfs有时候会用fuse挂载 如果宿主机没有这个工具会导致挂载失败 pod无法启动
1 | yum install -y ceph-fuse |
Ceph 端创建 CephFS pool
- 在ceph节点,CephFS需要使用两个Pool来分别存储数据和元数据
1 | [root@cephnode01 my-cluster]# ceph osd pool create fs_data 16 |
1 | # 创建一个CephFS |
部署 cephfs-provisioner
1 | # 使用社区提供的cephfs-provisioner |
1 | [root@k8s-master1 ceph]# kubectl apply -f external-storage-cephfs-provisioner.yaml |
配置 StorageClass
1 | # 查看key 在ceph的mon或者admin节点 |
1 | # 配置 StorageClass |
1 | [root@k8s-master1 ceph]# kubectl apply -f storageclass-cephfs.yaml |
测试使用
创建pvc测试
1 | cat >cephfs-pvc-test.yaml<<EOF |
1 | [root@k8s-master1 ceph]# kubectl apply -f cephfs-pvc-test.yaml |
1 | # 创建 nginx pod 挂载测试 |
1 | [root@k8s-master1 ceph]# kubectl apply -f nginx-pod2.yaml |
1 | # 修改文件内容 |
1 | # 清理 |
Ceph 日常运维管理
集群监控管理
- 集群整体运行状态
1 | [root@cephnode01 my-cluster]# ceph -s |
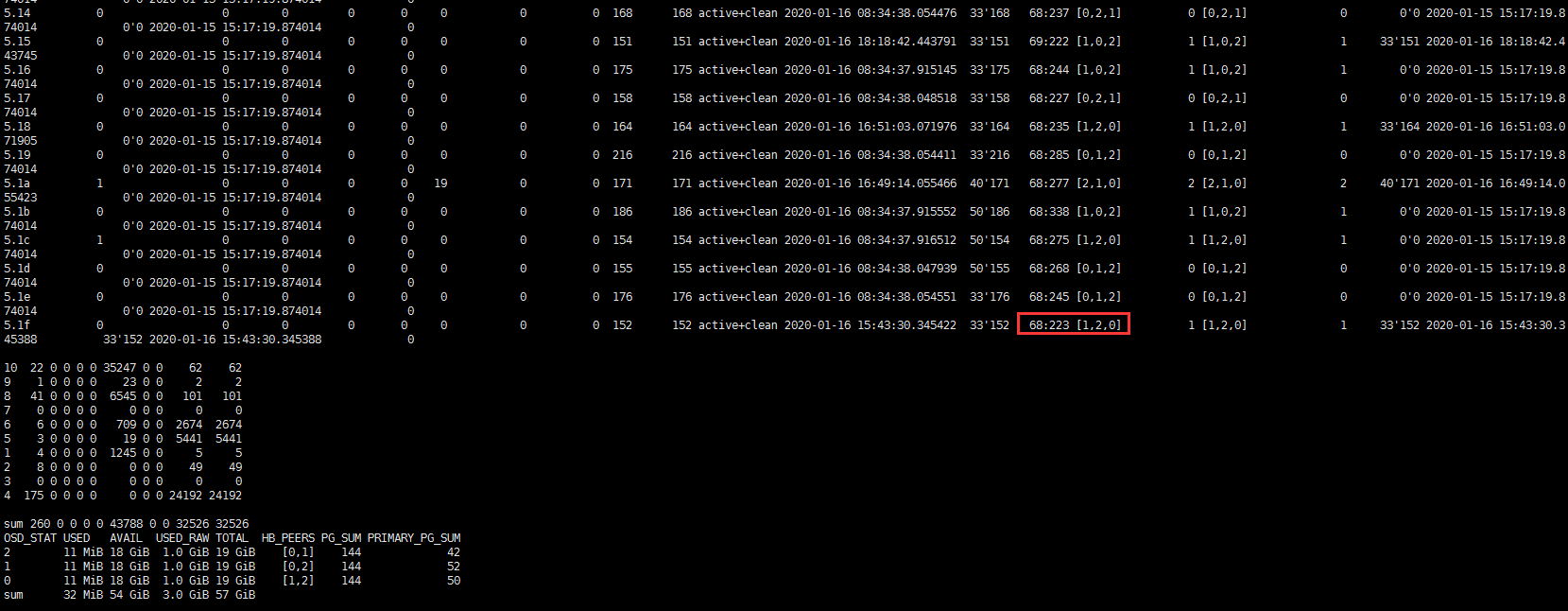
PG 状态
- 查看pg状态查看通常使用下面两个命令即可,dump可以查看更详细信息,如
1 | ceph pg dump |
Pool状态
1 | ceph osd pool stats |
OSD 状态
1 | ceph osd stat |
Monitor状态和查看仲裁状态
1 | ceph mon stat |
集群空间用量
1 | ceph df 常用 |
集群配置管理 (临时和全局,服务平滑重启)
- 有时候需要更改服务的配置,但不想重启服务,或者是临时修改。这时候就可以使用tell和daemon子命令来完成此需求。
查看运行配置
1 | 命令格式: |
tell 子命令格式
- 使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集群的角色进行设置。
- 而出现节点异常无法设置时候,只会在命令行当中进行报错,不太便于查找。
1 | 命令格式: |
daemon子命令
- 使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此方法是需要在设置的角色所在的主机上进行设置。
1 | 命令格式: |
集群操作
1 | 1. 启动所有守护进程 |
添加和删除OSD
添加 OSD
1 | 1、格式化磁盘 |
删除 OSD
1 | 1. 调整osd的crush weight为 0 |
扩容 PG
1 | ceph osd pool set {pool-name} pg_num 128 |
Pool 操作
1 | # 列出存储池 |
1 | # 创建存储池 |
1 | # 设置存储池配额 |
1 | # 删除存储池 |
1 | # 重命名存储池 |
1 | # 查看存储池统计信息 |
1 | # 给存储池做快照 |
1 | # 删除存储池的快照 |
1 | # 获取存储池选项值 |
1 | # 调整存储池选项值 |
获取对象副本数
1 | ceph osd dump | grep 'replicated size' |
用户管理
- Ceph 把数据以对象的形式存于各存储池中。
- Ceph 用户必须具有访问存储池的权限才能够读写数据。
- 另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。
1 | # 查看用户信息 |
1 | # 添加用户 |
1 | # 修改用户权限 |
增加和删除Monitor
1 | # 新增一个monitor |
1 | # 删除Monitor |
Pool 配置大小
1 | # Pool的基本配置 |
常见问题
nearfull osd(s) or pool(s) nearfull
- 此时说明部分osd的存储已经超过阈值,mon会监控ceph集群中OSD空间使用情况。
- 如果要消除WARN,可以修改这两个参数,提高阈值,但是通过实践发现并不能解决问题,可以通过观察osd的数据分布情况来分析原因。
1 | # 配置文件设置阈值 |
1 | # 自动处理 |
1 | # 手动处理 |
1 | # 全局处理 |
PG 故障状态
1 | PG状态概述 |
OSD 状态
1 | 单个OSD有两组状态需要关注,其中一组使用in/out标记该OSD是否在集群内,另一组使用up/down标记该OSD是否处于运行中状态。两组状态之间并不互斥,换句话说,当一个OSD处于“in”状态时,它仍然可以处于up或down的状态。 |